






23
Feb
生成扩散模型漫谈(十七):构建ODE的一般步骤(下)
By 苏剑林 | 2023-02-23 | 94705位读者 | 引用历史总是惊人地相似。当初笔者在写《生成扩散模型漫谈(十四):构建ODE的一般步骤(上)》(当时还没有“上”这个后缀)时,以为自己已经搞清楚了构建ODE式扩散的一般步骤,结果读者 @gaohuazuo 就给出了一个新的直观有效的方案,这直接导致了后续《生成扩散模型漫谈(十四):构建ODE的一般步骤(中)》(当时后缀是“下”)。而当笔者以为事情已经终结时,却发现ICLR2023的论文《Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow》又给出了一个构建ODE式扩散模型的新方案,其简洁、直观的程度简直前所未有,令人拍案叫绝。所以笔者只好默默将前一篇的后缀改为“中”,然后写了这个“下”篇来分享这一新的结果。
直观结果
我们知道,扩散模型是一个$\boldsymbol{x}_T\to \boldsymbol{x}_0$的演化过程,而ODE式扩散模型则指定演化过程按照如下ODE进行:
\begin{equation}\frac{d\boldsymbol{x}_t}{dt}=\boldsymbol{f}_t(\boldsymbol{x}_t)\label{eq:ode}\end{equation}
而所谓构建ODE式扩散模型,就是要设计一个函数$\boldsymbol{f}_t(\boldsymbol{x}_t)$,使其对应的演化轨迹构成给定分布$p_T(\boldsymbol{x}_T)$、$p_0(\boldsymbol{x}_0)$之间的一个变换。说白了,我们希望从$p_T(\boldsymbol{x}_T)$中随机采样一个$\boldsymbol{x}_T$,然后按照上述ODE向后演化得到的$\boldsymbol{x}_0$是$\sim p_0(\boldsymbol{x}_0)$的。
17
Mar
为什么现在的LLM都是Decoder-only的架构?
By 苏剑林 | 2023-03-17 | 123286位读者 | 引用LLM是“Large Language Model”的简写,目前一般指百亿参数以上的语言模型,主要面向文本生成任务。跟小尺度模型(10亿或以内量级)的“百花齐放”不同,目前LLM的一个现状是Decoder-only架构的研究居多,像OpenAI一直坚持Decoder-only的GPT系列就不说了,即便是Google这样的并非全部押注在Decoder-only的公司,也确实投入了不少的精力去研究Decoder-only的模型,如PaLM就是其中之一。那么,为什么Decoder-only架构会成为LLM的主流选择呢?
知乎上也有同款问题《为什么现在的LLM都是Decoder only的架构?》,上面的回答大多数聚焦于Decoder-only在训练效率和工程实现上的优势,那么它有没有理论上的优势呢?本文试图从这个角度进行简单的分析。
统一视角
需要指出的是,笔者目前训练过的模型,最大也就是10亿级别的,所以从LLM的一般概念来看是没资格回答这个问题的,下面的内容只是笔者根据一些研究经验,从偏理论的角度强行回答一波。文章多数推论以自己的实验结果为引,某些地方可能会跟某些文献的结果冲突,请读者自行取舍。
20
Mar
《为什么现在的LLM都是Decoder-only的架构?》FAQ
By 苏剑林 | 2023-03-20 | 57035位读者 | 引用上周笔者写了《为什么现在的LLM都是Decoder-only的架构?》,总结了一下我在这个问题上的一些实验结论和猜测。果然是热点问题流量大,paperweekly的转发没多久阅读量就破万了,知乎上点赞数也不少。在几个平台上,陆陆续续收到了读者的一些意见或者疑问,总结了其中一些有代表性的问题,做成了本篇FAQ,希望能进一步帮助大家解决疑惑。
回顾
在《为什么现在的LLM都是Decoder-only的架构?》中,笔者对GPT和UniLM两种架构做了对比实验,然后结合以往的研究经历,猜测了如下结论:
1、输入部分的注意力改为双向不会带来收益,Encoder-Decoder架构的优势很可能只是源于参数翻倍;
2、双向注意力没有带来收益,可能是因为双向注意力的低秩问题导致效果下降。
所以,基于这两点推测,我们得到结论:
在同等参数量、同等推理成本下,Decoder-only架构是最优选择。
24
Jun
生成扩散模型漫谈(十九):作为扩散ODE的GAN
By 苏剑林 | 2023-06-24 | 36381位读者 | 引用在文章《生成扩散模型漫谈(十六):W距离 ≤ 得分匹配》中,我们推导了Wasserstein距离与扩散模型得分匹配损失之间的一个不等式,表明扩散模型的优化目标与WGAN的优化目标在某种程度上具有相似性。而在本文,我们将探讨《MonoFlow: Rethinking Divergence GANs via the Perspective of Wasserstein Gradient Flows》中的研究成果,它进一步展示了GAN与扩散模型之间的联系:GAN实际上可以被视为在另一个时间维度上的扩散ODE!
这些发现表明,尽管GAN和扩散模型表面上是两种截然不同的生成式模型,但它们实际上存在许多相似之处,并在许多方面可以相互借鉴和参考。
思路简介
我们知道,GAN所训练的生成器是从噪声$\boldsymbol{z}$到真实样本的一个直接的确定性变换$\boldsymbol{g}_{\boldsymbol{\theta}}(\boldsymbol{z})$,而扩散模型的显著特点是“渐进式生成”,它的生成过程对应于从一系列渐变的分布$p_0(\boldsymbol{x}_0),p_1(\boldsymbol{x}_1),\cdots,p_T(\boldsymbol{x}_T)$中采样(注:在前面十几篇文章中,$\boldsymbol{x}_T$是噪声,$\boldsymbol{x}_0$是目标样本,采样过程是$\boldsymbol{x}_T\to \boldsymbol{x}_0$,但为了便于下面的表述,这里反过来改为$\boldsymbol{x}_0\to \boldsymbol{x}_T$)。看上去确实找不到多少相同之处,那怎么才能将两者联系起来呢?
17
Apr
生成扩散模型漫谈(二十三):信噪比与大图生成(下)
By 苏剑林 | 2024-04-17 | 37693位读者 | 引用上一篇文章《生成扩散模型漫谈(二十二):信噪比与大图生成(上)》中,我们介绍了通过对齐低分辨率的信噪比来改进noise schedule,从而改善直接在像素空间训练的高分辨率图像生成(大图生成)的扩散模型效果。而这篇文章的主角同样是信噪比和大图生成,但做到了更加让人惊叹的事情——直接将训练好低分辨率图像的扩散模型用于高分辨率图像生成,不用额外的训练,并且效果和推理成本都媲美直接训练的大图模型!
这个工作出自最近的论文《Upsample Guidance: Scale Up Diffusion Models without Training》,它巧妙地将低分辨率模型上采样作为引导信号,并结合了CNN对纹理细节的平移不变性,成功实现了免训练高分辨率图像生成。
思想探讨
我们知道,扩散模型的训练目标是去噪(Denoise,也是DDPM的第一个D)。按我们的直觉,去噪这个任务应该是分辨率无关的,换句话说,理想情况下低分辨率图像训练的去噪模型应该也能用于高分辨率图像去噪,从而低分辨率的扩散模型应该也能直接用于高分辨率图像生成。
24
Jul
Monarch矩阵:计算高效的稀疏型矩阵分解
By 苏剑林 | 2024-07-24 | 28947位读者 | 引用在矩阵压缩这个问题上,我们通常有两个策略可以选择,分别是低秩化和稀疏化。低秩化通过寻找矩阵的低秩近似来减少矩阵尺寸,而稀疏化则是通过减少矩阵中的非零元素来降低矩阵的复杂性。如果说SVD是奔着矩阵的低秩近似去的,那么相应地寻找矩阵稀疏近似的算法又是什么呢?
接下来我们要学习的是论文《Monarch: Expressive Structured Matrices for Efficient and Accurate Training》,它为上述问题给出了一个答案——“Monarch矩阵”,这是一簇能够分解为若干置换矩阵与稀疏矩阵乘积的矩阵,同时具备计算高效且表达能力强的特点,论文还讨论了如何求一般矩阵的Monarch近似,以及利用Monarch矩阵参数化LLM来提高LLM速度等内容。
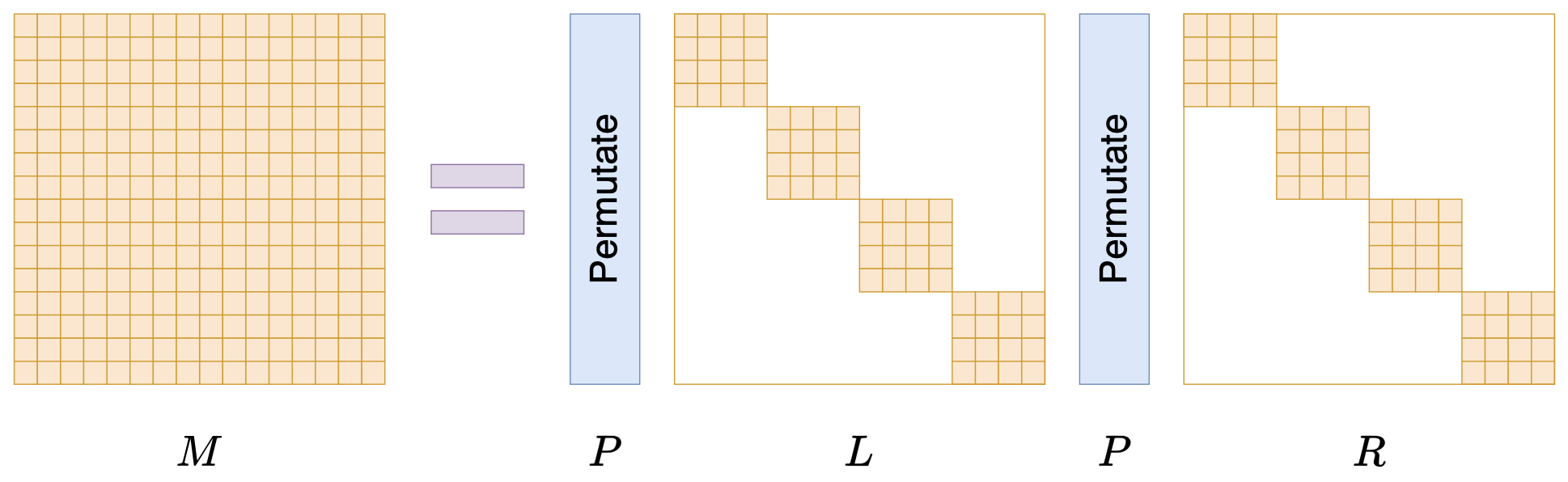
Monarch矩阵形式M=PLPR
值得指出的是,该论文的作者也正是著名的Flash Attention的作者Tri Dao,其工作几乎都在致力于改进LLM的性能,这篇Monarch也是他主页上特意展示的几篇论文之一,单从这一点看就非常值得学习一番。
17
Jan
细水长flow之TARFLOW:流模型满血归来?
By 苏剑林 | 2025-01-17 | 17685位读者 | 引用不知道还有没有读者对这个系列有印象?这个系列取名“细水长flow”,主要介绍flow模型的相关工作,起因是当年(2018年)OpenAI发布了一个新的流模型Glow,在以GAN为主流的当时来说着实让人惊艳了一番。但惊艳归惊艳,事实上在相当长的时间内,Glow及后期的一些改进在生成效果方面都是比不上GAN的,更不用说现在主流的扩散模型了。
不过局面可能要改变了,上个月的论文《Normalizing Flows are Capable Generative Models》提出了新的流模型TARFLOW,它在几乎在所有的生成任务效果上都逼近了当前SOTA,可谓是流模型的“满血”回归。

TARFLOW的生成效果
7
Jul


最近评论