






14
Mar
圆周率节快乐!|| 原来已经写了十年博客~
By 苏剑林 | 2019-03-14 | 80442位读者 | 引用
1
Dec
级联抑制:提升GAN表现的一种简单有效的方法
By 苏剑林 | 2019-12-01 | 34926位读者 | 引用昨天刷arxiv时发现了一篇来自星星韩国的论文,名字很直白,就叫做《A Simple yet Effective Way for Improving the Performance of GANs》。打开一看,发现内容也很简练,就是提出了一种加强GAN的判别器的方法,能让GAN的生成指标有一定的提升。
作者把这个方法叫做Cascading Rejection,我不知道咋翻译,扔到百度翻译里边显示“级联抑制”,想想看好像是有这么点味道,就暂时这样叫着了。介绍这个方法倒不是因为它有多强大,而是觉得它的几何意义很有趣,而且似乎有一定的启发性。
正交分解
GAN的判别器一般是经过多层卷积后,通过flatten或pool得到一个固定长度的向量$\boldsymbol{v}$,然后再与一个权重向量$\boldsymbol{w}$做内积,得到一个标量打分(先不考虑偏置项和激活函数等末节):
\begin{equation}D(\boldsymbol{x})=\langle \boldsymbol{v},\boldsymbol{w}\rangle\end{equation}
也就是说,用$\boldsymbol{v}$作为输入图片的表征,然后通过$\boldsymbol{v}$和$\boldsymbol{w}$的内积大小来判断出这个图片的“真”的程度。
19
Oct
最小熵原理(五):“层层递进”之社区发现与聚类
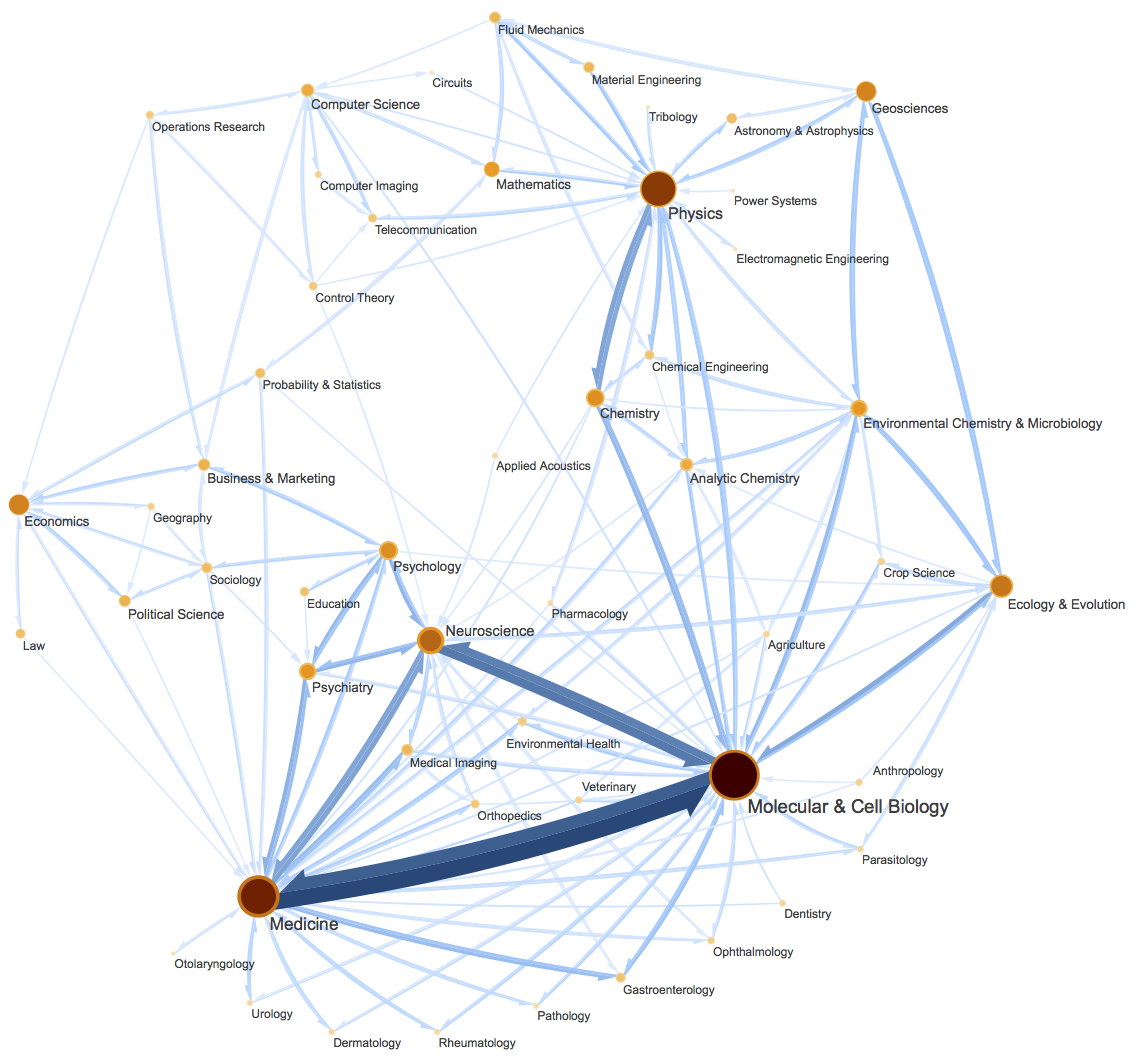
By 苏剑林 | 2019-10-19 | 161264位读者 | 引用让我们不厌其烦地回顾一下:最小熵原理是一个无监督学习的原理,“熵”就是学习成本,而降低学习成本是我们的不懈追求,所以通过“最小化学习成本”就能够无监督地学习出很多符合我们认知的结果,这就是最小熵原理的基本理念。
这篇文章里,我们会介绍一种相当漂亮的聚类算法,它同样也体现了最小熵原理,或者说它可以通过最小熵原理导出来,名为InfoMap,或者MapEquation。事实上InfoMap已经是2007年的成果了,最早的论文是《Maps of random walks on complex networks reveal community structure》,虽然看起来很旧,但我认为它仍是当前最漂亮的聚类算法,因为它不仅告诉了我们“怎么聚类”,更重要的是给了我们一个“为什么要聚类”的优雅的信息论解释,并从这个解释中直接导出了整个聚类过程。
一个复杂有向图网络示意图。图片来自InfoMap最早的论文《Maps of random walks on complex networks reveal community structure》
当然,它的定位并不仅仅局限在聚类上,更准确地说,它是一种图网络上的“社区发现”算法。所谓社区发现(Community Detection),大概意思是给定一个有向/无向图网络,然后找出这个网络上的“抱团”情况,至于详细含义,大家可以自行搜索一下。简单来说,它跟聚类相似,但是比聚类的含义更丰富。(还可以参考《什么是社区发现?》)
25
May
Google新作Synthesizer:我们还不够了解自注意力
By 苏剑林 | 2020-05-25 | 96432位读者 | 引用深度学习这个箱子,远比我们想象的要黑。
写在开头
据说物理学家费曼说过一句话[来源]:“谁要是说他懂得量子力学,那他就是真的不懂量子力学。”我现在越来越觉得,这句话中的“量子力学”也可以替换为“深度学习”。尽管深度学习已经在越来越多的领域证明了其有效性,但我们对它的解释性依然相当无力。当然,这几年来已经有不少工作致力于打开深度学习这个黑箱,但是很无奈,这些工作基本都是“马后炮”式的,也就是在已有的实验结果基础上提出一些勉强能说服自己的解释,无法做到自上而下的构建和理解模型的原理,更不用说提出一些前瞻性的预测。
本文关注的是自注意力机制。直观上来看,自注意力机制算是解释性比较强的模型之一了,它通过自己与自己的Attention来自动捕捉了token与token之间的关联,事实上在《Attention is All You Need》那篇论文中,就给出了如下的看上去挺合理的可视化效果:
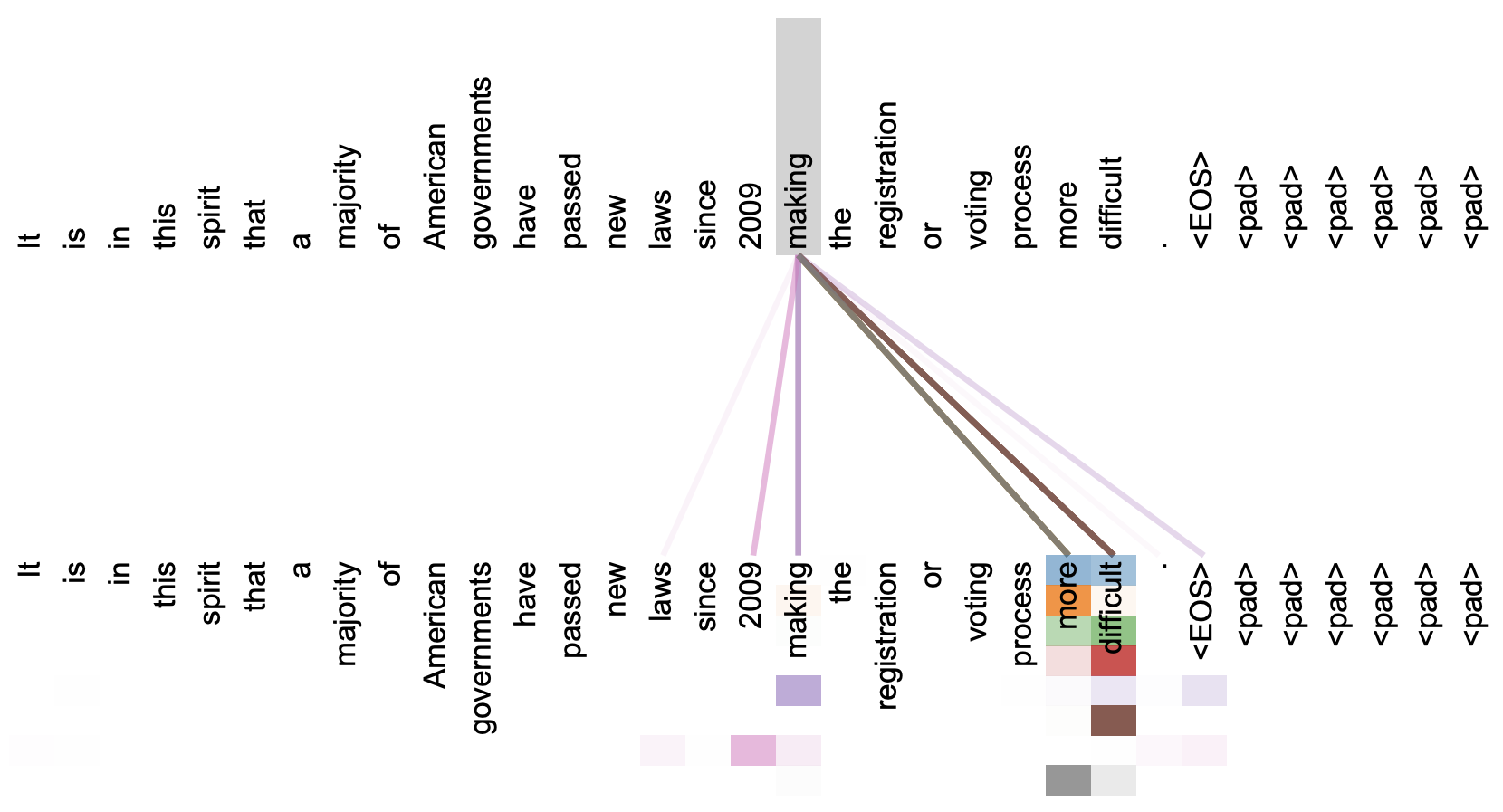
《Attention is All You Need》一文中对Attention的可视化例子
但自注意力机制真的是这样生效的吗?这种“token对token”的注意力是必须的吗?前不久Google的新论文《Synthesizer: Rethinking Self-Attention in Transformer Models》对自注意力机制做了一些“异想天开”的探索,里边的结果也许会颠覆我们对自注意力的认知。
4
Jul
线性Attention的探索:Attention必须有个Softmax吗?
By 苏剑林 | 2020-07-04 | 240974位读者 | 引用众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是$\mathcal{O}(n^2)$级别的,$n$是序列长度,所以当$n$比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到$\mathcal{O}(n\log n)$甚至$\mathcal{O}(n)$。
前几天笔者读到了论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》,了解到了线性化Attention(Linear Attention)这个探索点,继而阅读了一些相关文献,有一些不错的收获,最后将自己对线性化Attention的理解汇总在此文中。
Attention
当前最流行的Attention机制当属Scaled-Dot Attention,形式为
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\label{eq:std-att}\end{equation}
这里的$\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}$,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设$\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times d}$,一般场景下都有$n > d$甚至$n\gg d$(BERT base里边$d=64$)。
9
Oct
关于WhiteningBERT原创性的疑问和沟通
By 苏剑林 | 2021-10-09 | 69935位读者 | 引用在文章《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》中,笔者受到BERT-flow的启发,提出了一种名为BERT-whitening的替代方案,它比BERT-flow更简单,但多数数据集下能取得相近甚至更好的效果,此外它还可以用于对句向量降维以提高检索速度。后来,笔者跟几位合作者一起补充了BERT-whitening的实验,并将其写成了英文论文《Whitening Sentence Representations for Better Semantics and Faster Retrieval》,在今年3月29日发布在Arxiv上。
然而,大约一周后,一篇名为《WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach》的论文 (下面简称WhiteningBERT)出现在Arxiv上,内容跟BERT-whitening高度重合,有读者看到后向我反馈WhiteningBERT抄袭了BERT-whitening。本文跟关心此事的读者汇报一下跟WhiteningBERT的作者之间的沟通结果。
时间节点
首先,回顾一下BERT-whitening的相关时间节点,以帮助大家捋一下事情的发展顺序:
11
Apr
无监督语义相似度哪家强?我们做了个比较全面的评测
By 苏剑林 | 2021-04-11 | 153619位读者 | 引用一月份的时候,笔者写了《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》,指出无监督语义相似度的SOTA模型BERT-flow其实可以通过一个简单的线性变换(白化操作,BERT-whitening)达到。随后,我们进一步完善了实验结果,写成了论文《Whitening Sentence Representations for Better Semantics and Faster Retrieval》。这篇博客将对这篇论文的内容做一个基本的梳理,并在5个中文语义相似度任务上进行了补充评测,包含了600多个实验结果。
方法概要
BERT-whitening的思路很简单,就是在得到每个句子的句向量$\{x_i\}_{i=1}^N$后,对这些矩阵进行一个白化(也就是PCA),使得每个维度的均值为0、协方差矩阵为单位阵,然后保留$k$个主成分,流程如下图:

BERT-whitening的基本流程
26
Apr
中文任务还是SOTA吗?我们给SimCSE补充了一些实验
By 苏剑林 | 2021-04-26 | 245672位读者 | 引用今年年初,笔者受到BERT-flow的启发,构思了成为“BERT-whitening”的方法,并一度成为了语义相似度的新SOTA(参考《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》,论文为《Whitening Sentence Representations for Better Semantics and Faster Retrieval》)。然而“好景不长”,在BERT-whitening提交到Arxiv的不久之后,Arxiv上出现了至少有两篇结果明显优于BERT-whitening的新论文。
第一篇是《Generating Datasets with Pretrained Language Models》,这篇借助模板从GPT2_XL中无监督地构造了数据对来训练相似度模型,个人认为虽然有一定的启发而且效果还可以,但是复现的成本和变数都太大。另一篇则是本文的主角《SimCSE: Simple Contrastive Learning of Sentence Embeddings》,它提出的SimCSE在英文数据上显著超过了BERT-flow和BERT-whitening,并且方法特别简单~
那么,SimCSE在中文上同样有效吗?能大幅提高中文语义相似度的效果吗?本文就来做些补充实验。

最近评论