






14
Jul
当生成模型肆虐:互联网将有“疯牛病”之忧?
By 苏剑林 | 2023-07-14 | 26737位读者 | 引用众所周知,不管是文本还是视觉领域,各种生成模型正在以无法阻挡的势头“肆虐”互联网。虽然大家都明白,实现真正的通用人工智能(AGI)还有很长的路要走,但这并不妨碍人们越来越频繁地利用生成模型来创作和分享内容。君不见,很多网络文章已经配上了Stable Diffusion模型生成的插图;君不见,很多新闻风格已经越来越显现出ChatGPT的影子。看似无害的这种趋势,正悄然引发了一个问题:我们是否应该对互联网上充斥的生成模型数据保持警惕?
近期发表的论文《Self-Consuming Generative Models Go MAD》揭示了一种令人担忧的可能性,那就是生成模型正在互联网上的无节制扩张,可能会导致一场数字版的“疯牛病”疫情。本文一起学习这篇论文,探讨其可能带来的影响。
30
Nov
用热传导方程来指导自监督学习
By 苏剑林 | 2022-11-30 | 19182位读者 | 引用用理论物理来卷机器学习已经不是什么新鲜事了,比如上个月介绍的《生成扩散模型漫谈(十三):从万有引力到扩散模型》就是经典一例。最近一篇新出的论文《Self-Supervised Learning based on Heat Equation》,顾名思义,用热传导方程来做(图像领域的)自监督学习,引起了笔者的兴趣。这种物理方程如何在机器学习中发挥作用?同样的思路能否迁移到NLP中?让我们一起来读读论文。
基本方程
如下图,左边是物理中热传导方程的解,右端则是CAM、积分梯度等显著性方法得到的归因热力图,可以看到两者有一定的相似之处,于是作者认为热传导方程可以作为好的视觉特征的一个重要先验。
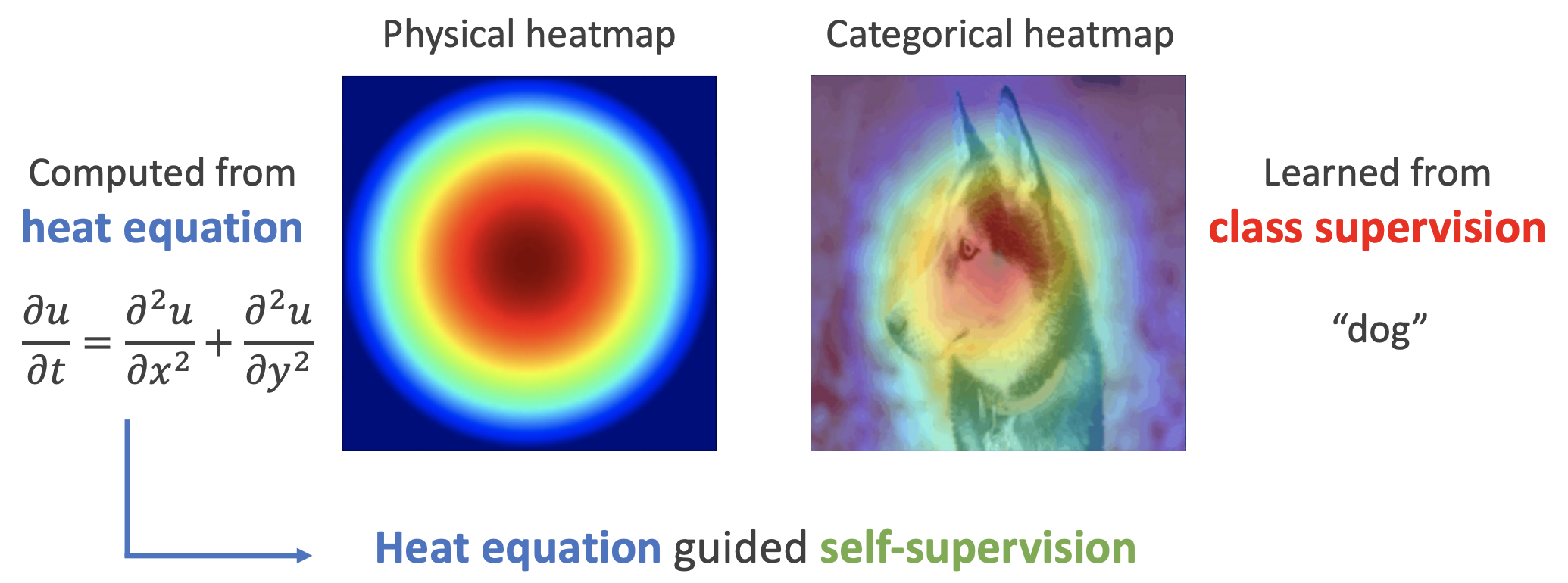
热方程的热力图(左)和视觉模型的热力图(右)
11
Feb
测试函数法推导连续性方程和Fokker-Planck方程
By 苏剑林 | 2023-02-11 | 16599位读者 | 引用在文章《生成扩散模型漫谈(六):一般框架之ODE篇》中,我们推导了SDE的Fokker-Planck方程;而在《生成扩散模型漫谈(十二):“硬刚”扩散ODE》中,我们单独推导了ODE的连续性方程。它们都是描述随机变量沿着SDE/ODE演化的分布变化方程,连续性方程是Fokker-Planck方程的特例。在推导Fokker-Planck方程时,我们将泰勒展开硬套到了狄拉克函数上,虽然结果是对的,但未免有点不伦不类;在推导连续性方程时,我们结合了雅可比行列式和泰勒展开,方法本身比较常规,但没法用来推广到Fokker-Planck方程。
这篇文章我们介绍“测试函数法”,它是推导连续性方程和Fokker-Planck方程的标准方法之一,其分析过程比较正规,并且适用场景也比较广。
21
Feb
“闭门造车”之多模态模型方案浅谈
By 苏剑林 | 2024-02-21 | 37250位读者 | 引用这篇文章分享一下笔者关于多模态模型架构的一些闭门造车的想法,或者说一些猜测。
最近Google的Gemini 1.5和OpenAI的Sora再次点燃了不少人对多模态的热情,只言片语的技术报告也引起了大家对其背后模型架构的热烈猜测。不过,本文并非是为了凑这个热闹才发出来的,事实上其中的一些思考由来已久,最近才勉强捋顺了一下,遂想写出来跟大家交流一波,刚好碰上了两者的发布。
事先声明,“闭门造车”一词并非自谦,笔者的大模型实践本就“乏善可陈”,而多模态实践更是几乎“一片空白”,本文确实只是根据以往文本生成和图像生成的一些经验所做的“主观臆测”。
问题背景
首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗?
31
Jan
幂等生成网络IGN:试图将判别和生成合二为一的GAN
By 苏剑林 | 2024-01-31 | 23080位读者 | 引用前段时间,一个名为“幂等生成网络(Idempotent Generative Network,IGN)”的生成模型引起了一定的关注。它自称是一种独立于已有的VAE、GAN、flow、Diffusion之外的新型生成模型,并且具有单步采样的特点。也许是大家苦于当前主流的扩散模型的多步采样生成过程久矣,因此任何声称可以实现单步采样的“风吹草动”都很容易吸引人们的关注。此外,IGN名称中的“幂等”一词也增加了它的神秘感,进一步扩大了人们的期待,也成功引起了笔者的兴趣,只不过之前一直有别的事情要忙,所以没来得及认真阅读模型细节。
最近闲了一点,想起来还有个IGN没读,于是重新把论文翻了出来,但阅读之后却颇感困惑:这哪里是个新模型,不就是个GAN的变种吗?跟常规GAN不同的是,它将生成器和判别器合二为一了。那这个“合二为一”是不是有什么特别的好处,比如训练更稳定?个人又感觉没有。下面将分享笔者从GAN角度理解IGN的过程和疑问。
生成对抗
关于GAN(Generative Adversarial Network,生成对抗网络),笔者前几年系统地学习过一段时间(查看GAN标签可以查看到相关文章),但近几年没有持续地关注了,因此这里先对GAN做个简单的回顾,也方便后续章节中我们对比GAN与IGN之间的异同。
30
May
路径积分系列:2.随机游走模型
By 苏剑林 | 2016-05-30 | 47517位读者 | 引用随机游走模型形式简单,但通过它可以导出丰富的结果,它是物理中各种扩散模型的基础之一,它也等价于随机过程中的布朗运动.
笔者所阅的文献表明,数学家已经对对称随机游走问题作了充分研究[2],也探讨了随机游走问题与偏微分方程的关系[3],并且还研究过不对称随机游走问题[4]. 然而,已有结果的不足之处有:1、在推导随机游走问题的概率分布或者偏微分方程之时,所用的方法不够简洁明了;2、没有研究更一般的不对称随机游走问题.
本章弥补了这一不足,首先通过母函数和傅立叶变换的方法,推导出了不对称随机游走问题所满足的偏微分方程,并且提出,由于随机游走容易通过计算机模拟,因此通过随机游走来模拟偏微分方程的解是一种有效的数值途径.
模型简介
本节通过一个本质上属于二项分布的走格子问题来引入随机游走.
考虑实数轴上的一个粒子,在$t=0$时刻它位于原点,每秒钟它以相等的概率向前或向后移动一格($+1$或$-1$),问$n$秒后它所处位置的概率分布.
18
Jul
用变分推断统一理解生成模型(VAE、GAN、AAE、ALI)
By 苏剑林 | 2018-07-18 | 279981位读者 | 引用前言:我小学开始就喜欢纯数学,后来也喜欢上物理,还学习过一段时间的理论物理,直到本科毕业时,我才慢慢进入机器学习领域。所以,哪怕在机器学习领域中,我的研究习惯还保留着数学和物理的风格:企图从最少的原理出发,理解、推导尽可能多的东西。这篇文章是我这个理念的结果之一,试图以变分推断作为出发点,来统一地理解深度学习中的各种模型,尤其是各种让人眼花缭乱的GAN。本文已经挂到arxiv上,需要读英文原稿的可以移步到《Variational Inference: A Unified Framework of Generative Models and Some Revelations》。
下面是文章的介绍。其实,中文版的信息可能还比英文版要稍微丰富一些,原谅我这蹩脚的英语...
摘要:本文从一种新的视角阐述了变分推断,并证明了EM算法、VAE、GAN、AAE、ALI(BiGAN)都可以作为变分推断的某个特例。其中,论文也表明了标准的GAN的优化目标是不完备的,这可以解释为什么GAN的训练需要谨慎地选择各个超参数。最后,文中给出了一个可以改善这种不完备性的正则项,实验表明该正则项能增强GAN训练的稳定性。
近年来,深度生成模型,尤其是GAN,取得了巨大的成功。现在我们已经可以找到数十个乃至上百个GAN的变种。然而,其中的大部分都是凭着经验改进的,鲜有比较完备的理论指导。
本文的目标是通过变分推断来给这些生成模型建立一个统一的框架。首先,本文先介绍了变分推断的一个新形式,这个新形式其实在博客以前的文章中就已经介绍过,它可以让我们在几行字之内导出变分自编码器(VAE)和EM算法。然后,利用这个新形式,我们能直接导出GAN,并且发现标准GAN的loss实则是不完备的,缺少了一个正则项。如果没有这个正则项,我们就需要谨慎地调整超参数,才能使得模型收敛。
7
Oct
深度学习中的Lipschitz约束:泛化与生成模型
By 苏剑林 | 2018-10-07 | 123318位读者 | 引用前言:去年写过一篇WGAN-GP的入门读物《互怼的艺术:从零直达WGAN-GP》,提到通过梯度惩罚来为WGAN的判别器增加Lipschitz约束(下面简称“L约束”)。前几天遐想时再次想到了WGAN,总觉得WGAN的梯度惩罚不够优雅,后来也听说WGAN在条件生成时很难搞(因为不同类的随机插值就开始乱了...),所以就想琢磨一下能不能搞出个新的方案来给判别器增加L约束。
闭门造车想了几天,然后发现想出来的东西别人都已经做了,果然是只有你想不到,没有别人做不到。主要包含在这两篇论文中:《Spectral Norm Regularization for Improving the Generalizability of Deep Learning》和《Spectral Normalization for Generative Adversarial Networks》。
所以这篇文章就按照自己的理解思路,对L约束相关的内容进行简单的介绍。注意本文的主题是L约束,并不只是WGAN。它可以用在生成模型中,也可以用在一般的监督学习中。
L约束与泛化
扰动敏感
记输入为$x$,输出为$y$,模型为$f$,模型参数为$w$,记为
$$\begin{equation}y = f_w(x)\end{equation}$$
很多时候,我们希望得到一个“稳健”的模型。何为稳健?一般来说有两种含义,一是对于参数扰动的稳定性,比如模型变成了$f_{w+\Delta w}(x)$后是否还能达到相近的效果?如果在动力学系统中,还要考虑模型最终是否能恢复到$f_w(x)$;二是对于输入扰动的稳定性,比如输入从$x$变成了$x+\Delta x$后,$f_w(x+\Delta x)$是否能给出相近的预测结果。读者或许已经听说过深度学习模型存在“对抗攻击样本”,比如图片只改变一个像素就给出完全不一样的分类结果,这就是模型对输入过于敏感的案例。

最近评论