






22
Nov
生成扩散模型漫谈(二十六):基于恒等式的蒸馏(下)
By 苏剑林 | 2024-11-22 | 27181位读者 | 引用继续回到我们的扩散系列。在《生成扩散模型漫谈(二十五):基于恒等式的蒸馏(上)》中,我们介绍了SiD(Score identity Distillation),这是一种不需要真实数据、也不需要从教师模型采样的扩散模型蒸馏方案,其形式类似GAN,但有着比GAN更好的训练稳定性。
SiD的核心是通过恒等变换来为学生模型构建更好的损失函数,这一点是开创性的,同时也遗留了一些问题。比如,SiD对损失函数的恒等变换是不完全的,如果完全变换会如何?如何从理论上解释SiD引入的$\lambda$的必要性?上个月放出的《Flow Generator Matching》(简称FGM)成功从更本质的梯度角度解释了$\lambda=0.5$的选择,而受到FGM启发,笔者则进一步发现了$\lambda = 1$的一种解释。
接下来我们将详细介绍SiD的上述理论进展。
15
Dec
生成扩散模型漫谈(二十七):将步长作为条件输入
By 苏剑林 | 2024-12-15 | 27455位读者 | 引用这篇文章我们再次聚焦于扩散模型的采样加速。众所周知,扩散模型的采样加速主要有两种思路,一是开发更高效的求解器,二是事后蒸馏。然而,据笔者观察,除了上两篇文章介绍过的SiD外,这两种方案都鲜有能将生成步数降低到一步的结果。虽然SiD能做到单步生成,但它需要额外的蒸馏成本,并且蒸馏过程中用到了类似GAN的交替训练过程,总让人感觉差点意思。
本文要介绍的是《One Step Diffusion via Shortcut Models》,其突破性思想是将生成步长也作为扩散模型的条件输入,然后往训练目标中加入了一个直观的正则项,这样就能直接稳定训练出可以单步生成模型,可谓简单有效的经典之作。
ODE扩散
原论文的结论是基于ODE式扩散模型的,而对于ODE式扩散的理论基础,我们在本系列的(六)、(十二)、(十四)、(十五)、(十七)等博客中已经多次介绍,其中最简单的一种理解方式大概是(十七)中的ReFlow视角,下面我们简单重复一下。
18
Dec
生成扩散模型漫谈(二十八):分步理解一致性模型
By 苏剑林 | 2024-12-18 | 27410位读者 | 引用书接上文,在《生成扩散模型漫谈(二十七):将步长作为条件输入》中,我们介绍了加速采样的Shortcut模型,其对比的模型之一就是“一致性模型(Consistency Models)”。事实上,早在《生成扩散模型漫谈(十七):构建ODE的一般步骤(下)》介绍ReFlow时,就有读者提到了一致性模型,但笔者总感觉它更像是实践上的Trick,理论方面略显单薄,所以兴趣寥寥。
不过,既然我们开始关注扩散模型加速采样方面的进展,那么一致性模型就是一个绕不开的工作。因此,趁着这个机会,笔者在这里分享一下自己对一致性模型的理解。
熟悉配方
还是熟悉的配方,我们的出发点依旧是ReFlow,因为它大概是ODE式扩散最简单的理解方式。设$\boldsymbol{x}_0\sim p_0(\boldsymbol{x}_0)$是目标分布的真实样本,$\boldsymbol{x}_1\sim p_1(\boldsymbol{x}_1)$是先验分布的随机噪声,$\boldsymbol{x}_t = (1-t)\boldsymbol{x}_0 + t\boldsymbol{x}_1$是加噪样本,那么ReFlow的训练目标是:
14
Feb
生成扩散模型漫谈(二十九):用DDPM来离散编码
By 苏剑林 | 2025-02-14 | 19571位读者 | 引用笔者前两天在arXiv刷到了一篇新论文《Compressed Image Generation with Denoising Diffusion Codebook Models》,实在为作者的天马行空所叹服,忍不住来跟大家分享一番。
如本文标题所述,作者提出了一个叫DDCM(Denoising Diffusion Codebook Models)的脑洞,它把DDPM的噪声采样限制在一个有限的集合上,然后就可以实现一些很奇妙的效果,比如像VQVAE一样将样本编码为离散的ID序列并重构回来。注意这些操作都是在预训练好的DDPM上进行的,无需额外的训练。
有限集合
由于DDCM只需要用到一个预训练好的DDPM模型来执行采样,所以这里我们就不重复介绍DDPM的模型细节了,对DDPM还不大了解的读者可以回顾我们《生成扩散模型漫谈》系列的(一)、(二)、(三)篇。
8
Apr
生成扩散模型漫谈(二十二):信噪比与大图生成(上)
By 苏剑林 | 2024-04-08 | 60114位读者 | 引用盘点主流的图像扩散模型作品,我们会发现一个特点:当前多数做高分辨率图像生成(下面简称“大图生成”)的工作,都是先通过Encoder变换到Latent空间进行的(即LDM,Latent Diffusion Model),直接在原始Pixel空间训练的扩散模型,大多数分辨率都不超过64*64,而恰好,LDM通过AutoEncoder变换后的Latent,大小通常也不超过64*64。这就自然引出了一系列问题:扩散模型是不是对于高分辨率生成存在固有困难?能否在Pixel空间直接生成高分辨率图像?
论文《Simple diffusion: End-to-end diffusion for high resolution images》尝试回答了这个问题,它通过“信噪比”分析了大图生成的困难,并以此来优化noise schdule,同时提出只需在最低分辨率feature上对架构进行scale up、多尺度Loss等技巧来保证训练效率和效果,这些改动使得原论文成功在Pixel空间上训练了分辨率高达1024*1024的图像扩散模型。
14
Jul
当生成模型肆虐:互联网将有“疯牛病”之忧?
By 苏剑林 | 2023-07-14 | 61939位读者 | 引用众所周知,不管是文本还是视觉领域,各种生成模型正在以无法阻挡的势头“肆虐”互联网。虽然大家都明白,实现真正的通用人工智能(AGI)还有很长的路要走,但这并不妨碍人们越来越频繁地利用生成模型来创作和分享内容。君不见,很多网络文章已经配上了Stable Diffusion模型生成的插图;君不见,很多新闻风格已经越来越显现出ChatGPT的影子。看似无害的这种趋势,正悄然引发了一个问题:我们是否应该对互联网上充斥的生成模型数据保持警惕?
近期发表的论文《Self-Consuming Generative Models Go MAD》揭示了一种令人担忧的可能性,那就是生成模型正在互联网上的无节制扩张,可能会导致一场数字版的“疯牛病”疫情。本文一起学习这篇论文,探讨其可能带来的影响。
30
Nov
用热传导方程来指导自监督学习
By 苏剑林 | 2022-11-30 | 35752位读者 | 引用用理论物理来卷机器学习已经不是什么新鲜事了,比如上个月介绍的《生成扩散模型漫谈(十三):从万有引力到扩散模型》就是经典一例。最近一篇新出的论文《Self-Supervised Learning based on Heat Equation》,顾名思义,用热传导方程来做(图像领域的)自监督学习,引起了笔者的兴趣。这种物理方程如何在机器学习中发挥作用?同样的思路能否迁移到NLP中?让我们一起来读读论文。
基本方程
如下图,左边是物理中热传导方程的解,右端则是CAM、积分梯度等显著性方法得到的归因热力图,可以看到两者有一定的相似之处,于是作者认为热传导方程可以作为好的视觉特征的一个重要先验。
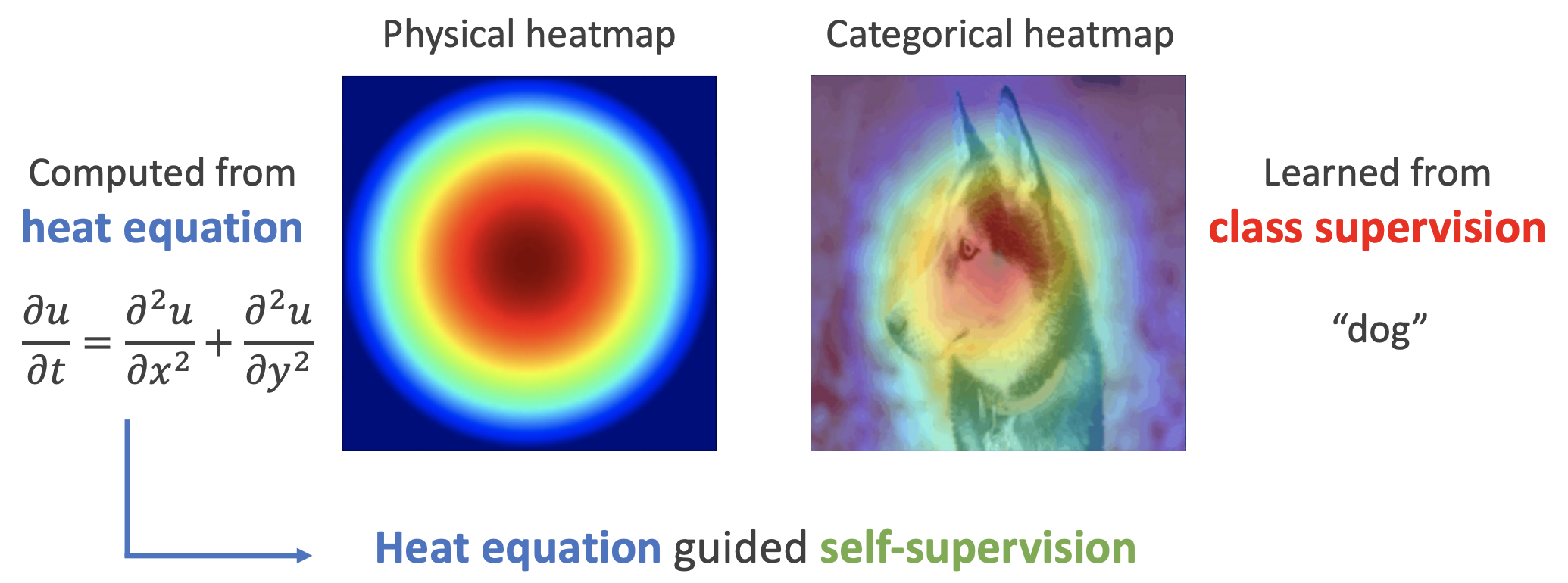
热方程的热力图(左)和视觉模型的热力图(右)
11
Feb
测试函数法推导连续性方程和Fokker-Planck方程
By 苏剑林 | 2023-02-11 | 43790位读者 | 引用在文章《生成扩散模型漫谈(六):一般框架之ODE篇》中,我们推导了SDE的Fokker-Planck方程;而在《生成扩散模型漫谈(十二):“硬刚”扩散ODE》中,我们单独推导了ODE的连续性方程。它们都是描述随机变量沿着SDE/ODE演化的分布变化方程,连续性方程是Fokker-Planck方程的特例。在推导Fokker-Planck方程时,我们将泰勒展开硬套到了狄拉克函数上,虽然结果是对的,但未免有点不伦不类;在推导连续性方程时,我们结合了雅可比行列式和泰勒展开,方法本身比较常规,但没法用来推广到Fokker-Planck方程。
这篇文章我们介绍“测试函数法”,它是推导连续性方程和Fokker-Planck方程的标准方法之一,其分析过程比较正规,并且适用场景也比较广。

最近评论