






27
Nov
从变分编码、信息瓶颈到正态分布:论遗忘的重要性
By 苏剑林 | 2018-11-27 | 167786位读者 | 引用这是一篇“散文”,我们来谈一下有着千丝万缕联系的三个东西:变分自编码器、信息瓶颈、正态分布。
众所周知,变分自编码器是一个很经典的生成模型,但实际上它有着超越生成模型的含义;而对于信息瓶颈,大家也许相对陌生一些,然而事实上信息瓶颈在去年也热闹了一阵子;至于正态分布,那就不用说了,它几乎跟所有机器学习领域都有或多或少的联系。
那么,当它们三个碰撞在一块时,又有什么样的故事可说呢?它们跟“遗忘”又有什么关系呢?
变分自编码器
在本博客你可以搜索到若干几篇介绍VAE的文章。下面简单回顾一下。
理论形式回顾
简单来说,VAE的优化目标是:
\begin{equation}KL(\tilde{p}(x)p(z|x)\Vert q(z)q(x|z))=\iint \tilde{p}(x)p(z|x)\log \frac{\tilde{p}(x)p(z|x)}{q(x|z)q(z)} dzdx\end{equation}
其中$q(z)$是标准正态分布,$p(z|x),q(x|z)$是条件正态分布,分别对应编码器、解码器。具体细节可以参考《变分自编码器(二):从贝叶斯观点出发》。
2
Dec
最小熵原理(四):“物以类聚”之从图书馆到词向量
By 苏剑林 | 2018-12-02 | 99024位读者 | 引用从第一篇看下来到这里,我们知道所谓“最小熵原理”就是致力于降低学习成本,试图用最小的成本完成同样的事情。所以整个系列就是一个“偷懒攻略”。那偷懒的秘诀是什么呢?答案是“套路”,所以本系列又称为“套路宝典”。
本篇我们介绍图书馆里边的套路。
先抛出一个问题:词向量出现在什么时候?是2013年Mikolov的Word2Vec?还是是2003年Bengio大神的神经语言模型?都不是,其实词向量可以追溯到千年以前,在那古老的图书馆中...

图书馆一角(图片来源于百度搜索)
走进图书馆
图书馆里有词向量?还是千年以前?在哪本书?我去借来看看。
放书的套路
其实不是哪本书,而是放书的套路。
很明显,图书馆中书的摆放是有“套路”的:它们不是随机摆放的,而是分门别类地放置的,比如数学类放一个区,文学类放一个区,计算机类也放一个区;同一个类也有很多子类,比如数学类中,数学分析放一个子区,代数放一个子区,几何放一个子区,等等。读者是否思考过,为什么要这么分类放置?分类放置有什么好处?跟最小熵又有什么关系?
8
Jan
从动力学角度看优化算法(三):一个更整体的视角
By 苏剑林 | 2019-01-08 | 62677位读者 | 引用
20
Jan
从Wasserstein距离、对偶理论到WGAN
By 苏剑林 | 2019-01-20 | 227320位读者 | 引用
推土机哪家强?成本最低找Wasserstein
2017年的时候笔者曾写过博文《互怼的艺术:从零直达WGAN-GP》,从一个相对通俗的角度来介绍了WGAN,在那篇文章中,WGAN更像是一个天马行空的结果,而实际上跟Wasserstein距离没有多大关系。
在本篇文章中,我们再从更数学化的视角来讨论一下WGAN。当然,本文并不是纯粹地讨论GAN,而主要侧重于Wasserstein距离及其对偶理论的理解。本文受启发于著名的国外博文《Wasserstein GAN and the Kantorovich-Rubinstein Duality》,内容跟它大体上相同,但是删除了一些冗余的部分,对不够充分或者含糊不清的地方作了补充。不管怎样,在此先对前辈及前辈的文章表示致敬。
(注:完整理解本文,应该需要多元微积分、概率论以及线性代数等基础知识。还有,本文确实长,数学公式确实多,但是,真的不复杂、不难懂,大家不要看到公式就吓怕了~)
6
Mar
O-GAN:简单修改,让GAN的判别器变成一个编码器!
By 苏剑林 | 2019-03-06 | 266223位读者 | 引用本文来给大家分享一下笔者最近的一个工作:通过简单地修改原来的GAN模型,就可以让判别器变成一个编码器,从而让GAN同时具备生成能力和编码能力,并且几乎不会增加训练成本。这个新模型被称为O-GAN(正交GAN,即Orthogonal Generative Adversarial Network),因为它是基于对判别器的正交分解操作来完成的,是对判别器自由度的最充分利用。

FFHQ线性插值效果图
10
Apr
分享一次专业领域词汇的无监督挖掘
By 苏剑林 | 2019-04-10 | 90160位读者 | 引用去年 Data Fountain 曾举办了一个“电力专业领域词汇挖掘”的比赛,该比赛有意思的地方在于它是一个“无监督”的比赛,也就是说它考验的是从大量的语料中无监督挖掘专业词汇的能力。
这个显然确实是工业界比较有价值的一个能力,又想着我之前也在无监督新词发现中做过一定的研究,加之“无监督比赛”的新颖性,所以当时毫不犹豫地参加了,然而最终排名并不靠前~
不管怎样,还是分享一下我自己的做法,这是一个真正意义上的无监督做法,也许会对部分读者有些参考价值。
基准对比
首先,新词发现部分,用到了我自己写的库nlp zero,基本思路是先分别对“比赛所给语料”、“自己爬的一部分百科百科语料”做新词发现,然后两者进行对比,就能找到一批“比赛所给语料”的特征词。
21
Mar
细水长flow之可逆ResNet:极致的暴力美学
By 苏剑林 | 2019-03-21 | 121033位读者 | 引用今天我们来介绍一个非常“暴力”的模型:可逆ResNet。
为什么一个模型可以可以用“暴力”来形容呢?当然是因为它确实非常暴力:它综合了很多数学技巧,活生生地(在一定约束下)把常规的ResNet模型搞成了可逆的!
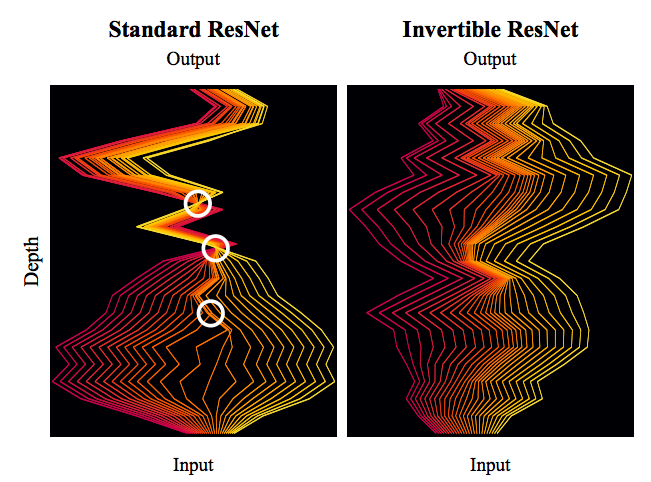
标准ResNet与可逆ResNet对比图。可逆ResNet允许信息无损可逆流动,而标准ResNet在某处则存在“坍缩”现象。
模型出自《Invertible Residual Networks》,之前在机器之心也报导过。在这篇文章中,我们来简单欣赏一下它的原理和内容。
可逆模型的点滴
为什么要研究可逆ResNet模型?它有什么好处?以前没有人研究过吗?
可逆的好处
可逆意味着什么?
意味着它是信息无损的,意味着它或许可以用来做更好的分类网络,意味着可以直接用最大似然来做生成模型,而且得益于ResNet强大的能力,意味着它可能有着比之前的Glow模型更好的表现~总而言之,如果一个模型是可逆的,可逆的成本不高而且拟合能力强,那么它就有很广的用途(分类、密度估计和生成任务,等等)。
19
Apr
从DCGAN到SELF-MOD:GAN的模型架构发展一览
By 苏剑林 | 2019-04-19 | 84623位读者 | 引用事实上,O-GAN的发现,已经达到了我对GAN的理想追求,使得我可以很惬意地跳出GAN的大坑了。所以现在我会试图探索更多更广的研究方向,比如NLP中还没做过的任务,又比如图神经网络,又或者其他有趣的东西。
不过,在此之前,我想把之前的GAN的学习结果都记录下来。
这篇文章中,我们来梳理一下GAN的架构发展情况,当然主要的是生成器的发展,判别器一直以来的变动都不大。还有,本文介绍的是GAN在图像方面的模型架构发展,跟NLP的SeqGAN没什么关系。
此外,关于GAN的基本科普,本文就不再赘述了。

棋盘效应图示,体现为放大之后出现如国际象棋棋盘一样的交错效应。图片来自文章《Deconvolution and Checkerboard Artifacts》

最近评论