






25
Nov
果壳中的条件随机场(CRF In A Nutshell)
By 苏剑林 | 2017-11-25 | 120312位读者 | 引用本文希望用尽可能简短的语言把CRF(条件随机场,Conditional Random Field)的原理讲清楚,这里In A Nutshell在英文中其实有“导论”、“科普”等意思(霍金写过一本《果壳中的宇宙》,这里东施效颦一下)。
网上介绍CRF的文章,不管中文英文的,基本上都是先说一些概率图的概念,然后引入特征的指数公式,然后就说这是CRF。所谓“概率图”,只是一个形象理解的说法,然而如果原理上说不到点上,你说太多形象的比喻,反而让人糊里糊涂,以为你只是在装逼。(说到这里我又想怼一下了,求解神经网络,明明就是求一下梯度,然后迭代一下,这多好理解,偏偏还弄个装逼的名字叫“反向传播”,如果不说清楚它的本质是求导和迭代求解,一下子就说反向传播,有多少读者会懂?)
好了,废话说完了,来进入正题。
逐标签Softmax
CRF常见于序列标注相关的任务中。假如我们的模型输入为$Q$,输出目标是一个序列$a_1,a_2,\dots,a_n$,那么按照我们通常的建模逻辑,我们当然是希望目标序列的概率最大
$$P(a_1,a_2,\dots,a_n|Q)$$
不管用传统方法还是用深度学习方法,直接对完整的序列建模是比较艰难的,因此我们通常会使用一些假设来简化它,比如直接使用朴素假设,就得到
$$P(a_1,a_2,\dots,a_n|Q)=P(a_1|Q)P(a_2|Q)\dots P(a_n|Q)$$
18
May
简明条件随机场CRF介绍(附带纯Keras实现)
By 苏剑林 | 2018-05-18 | 349061位读者 | 引用笔者去年曾写过博文《果壳中的条件随机场(CRF In A Nutshell)》,以一种比较粗糙的方式介绍了一下条件随机场(CRF)模型。然而那篇文章显然有很多不足的地方,比如介绍不够清晰,也不够完整,还没有实现,在这里我们重提这个模型,将相关内容补充完成。
本文是对CRF基本原理的一个简明的介绍。当然,“简明”是相对而言中,要想真的弄清楚CRF,免不了要提及一些公式,如果只关心调用的读者,可以直接移到文末。
图示
按照之前的思路,我们依旧来对比一下普通的逐帧softmax和CRF的异同。
逐帧softmax
CRF主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
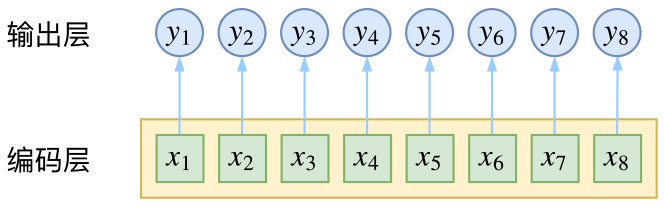
逐帧softmax并没有直接考虑输出的上下文关联
7
Feb
你的CRF层的学习率可能不够大
By 苏剑林 | 2020-02-07 | 110401位读者 | 引用CRF是做序列标注的经典方法,它理论优雅,实际也很有效,如果还不了解CRF的读者欢迎阅读旧作《简明条件随机场CRF介绍(附带纯Keras实现)》。在BERT模型出来之后,也有不少工作探索了BERT+CRF用于序列标注任务的做法。然而,很多实验结果显示(比如论文《BERT Meets Chinese Word Segmentation》)不管是中文分词还是实体识别任务,相比于简单的BERT+Softmax,BERT+CRF似乎并没有带来什么提升,这跟传统的BiLSTM+CRF或CNN+CRF的模型表现并不一样。
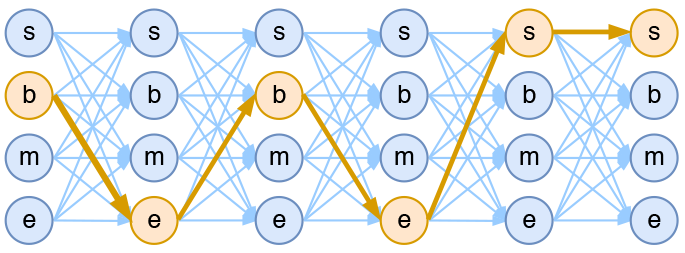
基于CRF的4标签分词模型示意图
这两天给bert4keras增加了用CRF做中文分词的例子(task_sequence_labeling_cws_crf.py),在调试过程中发现了CRF层可能存在学习不充分的问题,进一步做了几个对比实验,结果显示这可能是CRF在BERT中没什么提升的主要原因,遂在此记录一下分析过程,与大家分享。
19
Aug
【中文分词系列】 3. 字标注法与HMM模型
By 苏剑林 | 2016-08-19 | 89185位读者 | 引用在这篇文章中,我们暂停查词典方法的介绍,转而介绍字标注的方法。前面已经提到过,字标注是通过给句子中每个字打上标签的思路来进行分词,比如之前提到过的,通过4标签来进行标注(single,单字成词;begin,多字词的开头;middle,三字以上词语的中间部分;end,多字词的结尾。均只取第一个字母。),这样,“为人民服务”就可以标注为“sbebe”了。4标注不是唯一的标注方式,类似地还有6标注,理论上来说,标注越多会越精细,理论上来说效果也越好,但标注太多也可能存在样本不足的问题,一般常用的就是4标注和6标注。
值得一提的是,这种通过给每个字打标签、进而将问题转化为序列到序列的学习,不仅仅是一种分词方法,还是一种解决大量自然语言问题的思路,比如命名实体识别等任务,同样可以用标注的方法来做。回到分词来,通过字标注法来进行分词的模型有隐马尔科夫模型(HMM)、最大熵模型(ME)、条件随机场模型(CRF),它们在精度上都是递增的,据说目前公开评测中分词效果最好的是4标注的CRF。然而,在本文中,我们要讲解的是最不精确的HMM。因为在我看来,它并非一个特定的模型,而是解决一大类问题的通用思想,一种简化问题的学问。
这一切,还得从概率模型谈起。
14
Jan
基于CNN和序列标注的对联机器人
By 苏剑林 | 2019-01-14 | 45018位读者 | 引用缘起
前几天在量子位公众号上看到了《这个脑洞清奇的对联AI,大家都玩疯了》一文,觉得挺有意思,难得的是作者还整理并公开了数据集,所以决定自己尝试一下。
动手
“对对联”,我们可以看成是一个句子生成任务,可以用seq2seq完成,跟笔者之前写的《玩转Keras之seq2seq自动生成标题》一样,稍微修改一下输入即可。上面提到的文章所用的方法也是seq2seq,可见这算是标准做法了。
24
Feb
CRF用过了,不妨再了解下更快的MEMM?
By 苏剑林 | 2020-02-24 | 50949位读者 | 引用HMM、MEMM、CRF被称为是三大经典概率图模型,在深度学习之前的机器学习时代,它们被广泛用于各种序列标注相关的任务中。一个有趣的现象是,到了深度学习时代,HMM和MEMM似乎都“没落”了,舞台上就只留下CRF。相信做NLP的读者朋友们就算没亲自做过也会听说过BiLSTM+CRF做中文分词、命名实体识别等任务,却几乎没有听说过BiLSTM+HMM、BiLSTM+MEMM的,这是为什么呢?
今天就让我们来学习一番MEMM,并且通过与CRF的对比,来让我们更深刻地理解概率图模型的思想与设计。
模型推导
MEMM全称Maximum Entropy Markov Model,中文名可译为“最大熵马尔可夫模型”。不得不说,这个名字可能会吓退80%的初学者:最大熵还没搞懂,马尔可夫也不认识,这两个合起来怕不是天书?而事实上,不管是MEMM还是CRF,它们的模型都远比它们的名字来得简单,它们的概念和设计都非常朴素自然,并不难理解。
1
May
GlobalPointer:用统一的方式处理嵌套和非嵌套NER
By 苏剑林 | 2021-05-01 | 336586位读者 | 引用(注:本文的相关内容已整理成论文《Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition》,如需引用可以直接引用英文论文,谢谢。)
本文将介绍一个称为GlobalPointer的设计,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是$\mathcal{O}(1)$!
简单来说,就是更漂亮、更快速、更强大!真有那么好的设计吗?不妨继续看看。
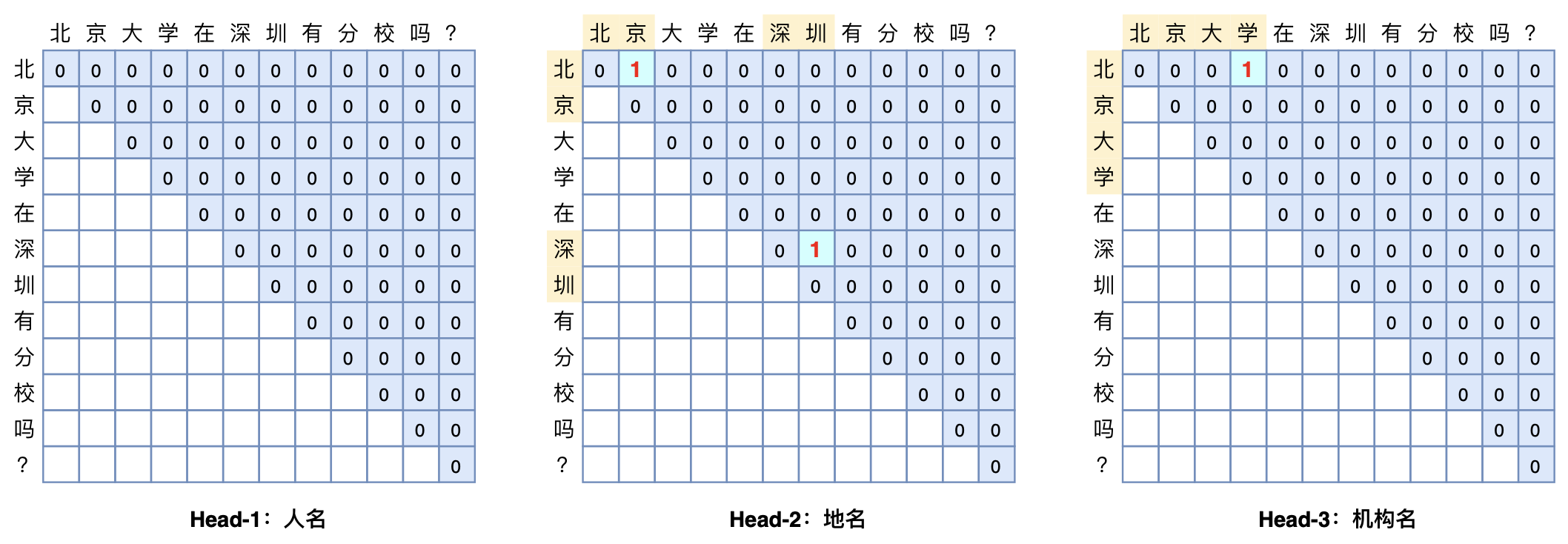
GlobalPointer多头识别嵌套实体示意图
1
Jul
与首都机场的“难分难舍”
By 苏剑林 | 2013-07-01 | 17278位读者 | 引用
无尽的等待
上个月的最后三天(06.28-06.30),我去国家天文台参加了第三届宇宙驿站的站长联谊会及科普研讨会。会议在河北兴隆天文台举行,我们按照计划是先到北京总部,然后去兴隆,然后回到北京总部解散。具体的故事我会另写文章与大家分享,本文主要想说一下我与北京首都国际机场的“难分难舍”的返程之旅。
按照计划,我是昨晚9点的飞机,今天凌晨应该可以到广州。我七点多到机场,八点左右就办完了登记手续,然而,我们等了两三个钟,最终得到的结果是:由于雷暴雨的影响(北京并没有下雨,估计是途中某个地方的上空天气太糟糕),该航班取消,补到第二天七点......这对我来说可真是个大考验。虽说航空公司会为我们联系宾馆,但是效率之低让不少人在机场抗议,于是乎冰冷的机场一下子就热闹起来的(取消的不知我们一趟航班,还有很多其他航班)。而我虽然来过好几次北京,毕竟还属于“异客”,自然经验不足,但我做出了一个很大胆的决定:在机场过夜!

最近评论