






14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 124962位读者 | 引用从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
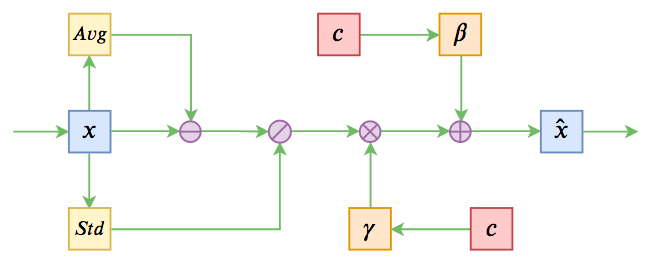
条件Normalization示意图
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。
4
Dec
层次分解位置编码,让BERT可以处理超长文本
By 苏剑林 | 2020-12-04 | 134795位读者 | 引用大家都知道,目前的主流的BERT模型最多能处理512个token的文本。导致这一瓶颈的根本原因是BERT使用了从随机初始化训练出来的绝对位置编码,一般的最大位置设为了512,因此顶多只能处理512个token,多出来的部分就没有位置编码可用了。当然,还有一个重要的原因是Attention的$\mathcal{O}(n^2)$复杂度,导致长序列时显存用量大大增加,一般显卡也finetune不了。
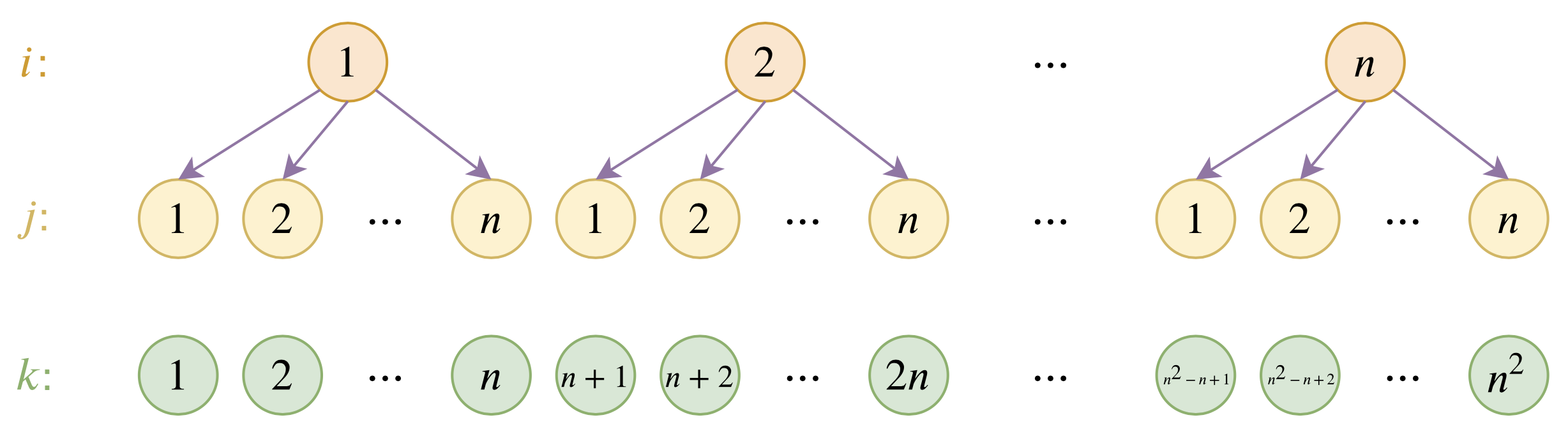
位置编码的层次分解示意图
本文主要面向前一个原因,即假设有足够多的显存前提下,如何简单修改当前最大长度为512的BERT模型,使得它可以直接处理更长的文本,主要思路是层次分解已经训练好的绝对位置编码,使得它可以延拓到更长的位置。
22
Jan
【搜出来的文本】⋅(三)基于BERT的文本采样
By 苏剑林 | 2021-01-22 | 96517位读者 | 引用从这一篇开始,我们就将前面所介绍的采样算法应用到具体的文本生成例子中。而作为第一个例子,我们将介绍如何利用BERT来进行文本随机采样。所谓文本随机采样,就是从模型中随机地产生一些自然语言句子出来,通常的观点是这种随机采样是GPT2、GPT3这种单向自回归语言模型专有的功能,而像BERT这样的双向掩码语言模型(MLM)是做不到的。
事实真的如此吗?当然不是。利用BERT的MLM模型其实也可以完成文本采样,事实上它就是上一篇文章所介绍的Gibbs采样。这一事实首先由论文《BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model》明确指出。论文的标题也颇为有趣:“BERT也有嘴巴,所以它得说点什么。”现在就让我们看看BERT究竟能说出什么来~
6
Mar
【中文分词系列】 7. 深度学习分词?只需一个词典!
By 苏剑林 | 2017-03-06 | 122864位读者 | 引用这个系列慢慢写到第7篇,基本上也把分词的各种模型理清楚了,除了一些细微的调整(比如最后的分类器换成CRF)外,剩下的就看怎么玩了。基本上来说,要速度,就用基于词典的分词,要较好地解决组合歧义何和新词识别,则用复杂模型,比如之前介绍的LSTM、FCN都可以。但问题是,用深度学习训练分词器,需要标注语料,这费时费力,仅有的公开的几个标注语料,又不可能赶得上时效,比如,几乎没有哪几个公开的分词系统能够正确切分出“扫描二维码,关注微信号”来。
本文就是做了这样的一个实验,仅用一个词典,就完成了一个深度学习分词器的训练,居然效果还不错!这种方案可以称得上是半监督的,甚至是无监督的。
12
Apr
【语料】百度的中文问答数据集WebQA
By 苏剑林 | 2017-04-12 | 235402位读者 | 引用信息抽取
众所周知,百度知道上有大量的人提了大量的问题,并且得到大量的回复。然而,百度知道上的回复者貌似懒人居多,他们往往喜欢直接在网上复制粘贴一大片来作为回答内容,而且这些内容可能跟问题相关,也可能跟问题不相关,比如
https://zhidao.baidu.com/question/557785746.html
问:广州白云山海拨多高
答:广州白云山(Guangzhou Baiyun Mountain),是新 “羊城八景”之首、国家4A级景区和国家重点风景名胜区。它位于广州市的东北部,为南粤名山之一,自古就有“羊城第一秀”之称。山体相当宽阔,由30多座山峰组成,为广东最高峰九连山的支脉。面积20.98平方公里,主峰摩星岭高382米(注:最新测绘高度为372.6米——国家测绘局,2008年),峰峦重叠,溪涧纵横,登高可俯览全市,遥望珠江。每当雨后天晴或暮春时节,山间白云缭绕,蔚为奇观,白云山之名由此得来
3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 92532位读者 | 引用前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
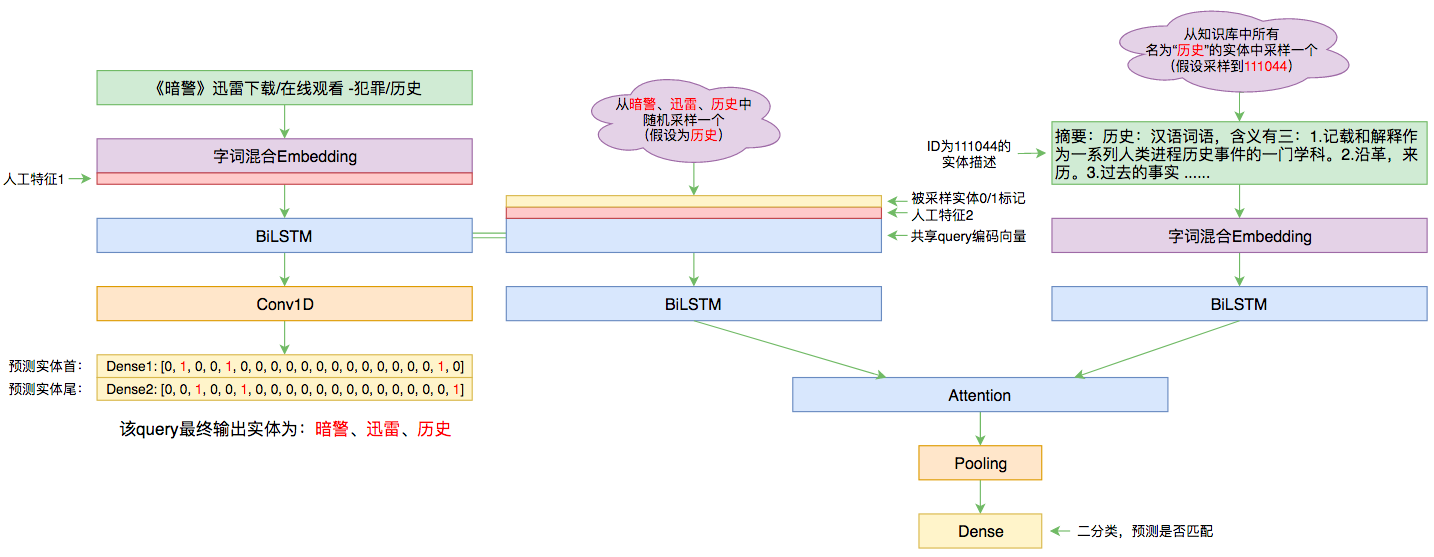
本文的实体链接模型总图(可以点击查看大图)
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
2
Apr
bert4keras在手,baseline我有:百度LIC2020
By 苏剑林 | 2020-04-02 | 100610位读者 | 引用百度的“2020语言与智能技术竞赛”开赛了,今年有五个赛道,分别是机器阅读理解、推荐任务对话、语义解析、关系抽取、事件抽取。每个赛道中,主办方都给出了基于PaddlePaddle的baseline模型,这里笔者也基于bert4keras给出其中三个赛道的个人baseline,从中我们可以看到用bert4keras搭建baseline模型的方便快捷与简练。
思路简析
这里简单分析一下这三个赛道的任务特点以及对应的baseline设计。
29
Jun

最近评论