






21
Oct
把Python脚本放到手机上定时运行
By 苏剑林 | 2015-10-21 | 40604位读者 | 引用毫无疑问,数据是数据分析的基础,而对于我等平民来说,获取大量数据的方式自然是通过爬虫采集,而对于笔者来说,写爬虫最自然的方式就是用Python写了。短短几行代码,就可以完成一个实用的爬虫,多清爽。(请参考:《记录一次爬取淘宝/天猫评论数据的过程》)
爬虫要住在哪里?
接下来的一个问题是,这个爬虫放到哪里运行?为了爬取每天更新的数据,往往需要每天都要运行一次爬虫,特别地,是在某个点定时运行。这样的话,老挂在自己的电脑运行是不大现实,因为自己的电脑总有关机的时候。也许有读者会想到放在云服务器里边,这是个方法,但是需要额外的成本。受到小虾大神的启发,我开始想把它放到路由器里边运行,某些比较好的路由器是可以外接U盘,且可以刷open-wrt系统的(一个Linux内核的路由器系统,可以像普通Linux那样装Python)。这对我来说是一种很吸引人的做法,但是我对Linux环境下的编译并不熟悉,尤其是路由器环境下的操作;另外路由器配置很低,一般都只是16M闪存、64M内存,如果没有耐心,那么是很难受得了的。
20
Jan
简单的迅雷VIP账号获取器(Python)
By 苏剑林 | 2016-01-20 | 30803位读者 | 引用在Windows工作的时候,经常会用迅雷下载东西,如果速度慢或者没资源,尤其是一些比较冷门的视频,迅雷的VIP会员服务总能够帮上大忙。后来无意间发现了有个“迅雷VIP账号获取器”的软件,可以获取一些临时的VIP账号供使用,这可是个好东西,因为开通迅雷会员虽然不贵,但是我又不经常下载,所以老感觉有点浪费,而有了这个之后,我随时下点东西都可以免费用了。
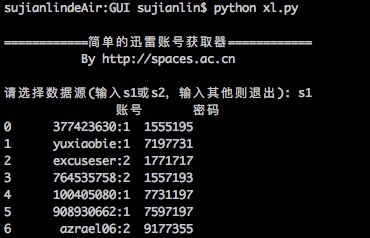
简单的迅雷VIP账号获取器
最近转移到了Mac上,而Mac也有迅雷,但那个账号获取器是exe的,不能在Mac运行。本以为获取器的构造会很复杂,谁知道,经过抓包研究,发现那个账号获取器的原理极其简单,说白了,就是一个简单的爬虫,以下这两个网站提供账号,它就到相应的抓取账号而已:
http://yunbo.xinjipin.com/
http://www.fenxs.com
据此,我也用Python简单写了一个,主要是方便我在Mac使用。读者如果有需要,也可以下载使用,代码兼容2.x和3.x的版本。主要的库是requests和re,pandas和sys的使用只不过是为了更加人性化。本来想用Tkinter写一个简单的GUI的,但是想想看,还是没必要了~~
7
Feb
年三十折腾极路由之SSH反向代理
By 苏剑林 | 2016-02-07 | 58097位读者 | 引用
猴年快乐!
今天是年三十了,这里简单祝大家除夕快乐,新年快乐!愿大家在新的一年里都晋升为学神。^_^
这两天主要在折腾家里的路由器。平时家里只有爸妈两人,所以为了节省,家里只是通过中继隔壁家的网络来上网。本来家里用小米路由器mini,可是小米mini中继模式下功能限制非常多,我又不想刷第三方固件(因为这样会失去app控制功能,不是很方便),所以干脆换了个极路由3。极路由在中继模式下仍然保留了大部分功能(我觉得这样才是正常的,我不理解小米mini在中继之后就没了那么多功能究竟是什么逻辑)。
作为折腾派,一个新路由到手,总有很多东西要配置,极路由本身是基于openwrt的,因此可玩性也很强。首先要完成中继,然后上网,这个很简单就不多说了。其次是获得ssh权限,在极路由那里叫做“申请开发者模式”,或者叫root(感觉极路由想做路由界的苹果,但是在如今这个时代,苹果当初那种发展模式估计很难发展起来了),这个步骤也不难,不过申请之后就会失去极路由的保修资格(不理解这是什么逻辑)。
本文主要介绍了怎么在openwrt(极路由)上安装python,以及建立SSH反向代理(实现内网穿透)。
1
Apr
《量子力学与路径积分》习题解答V0.5
By 苏剑林 | 2016-04-01 | 34047位读者 | 引用习题解答继续艰难推进中,目前是0.5版本,相比0.4版,跳过了8、9章,先做了第10、11章统计力学部分的习题。
第10章有10道习题,第11章其实没有习题。看上去很少,但其实每一道习题的难度都很大。这两章的主要内容都是在用路径积分方法算统计力学中的配分函数,这本来就是一个很艰辛的课题。加上费曼在书中那形象的描述,容易让读者能够认识到大概,但是却很难算下去。事实上,这一章的习题,我参考了相当多的资料,中文的、英文的都有,才勉强完成了。
虽说是完成,但10道题目中,我只完成了9道,其中问题10-3是有困惑的,我感觉的结果跟费曼给出的不一样,因此就算不下去了。在这里提出来,希望了解的读者赐教。
24
Apr
【语料】2500万中文三元组!
By 苏剑林 | 2017-04-24 | 82770位读者 | 引用闲聊
这两年,知识图谱、问答系统、聊天机器人等领域是越来越火了。知识图谱是一个很泛化的概念,在我看来,涉及到知识库的构建、检索、利用等机器学习相关的内容,都算知识图谱。当然,这也不是个什么定义,只是个人的直观感觉。
做知识图谱的读者都知道,三元组是结构化知识的一种方法,是做知识型问答系统的重要组成部分。对于英文领域,已经有一些较大的开源的三元组语料库,而很显然,中文目前还没有这样的语料库共享(哪怕有人爬取到了,也珍藏起来了)。笔者前段时间写了个百度百科的爬虫,爬了一段时间,抓了几百万个百度百科的词条。其中不少词条含有一些结构化的信息,直接抽取出来,就是有效的“三元组”了,可以用来做知识图谱。本文分享的三元组语料正是由此而来,共有2500万个三元组。

百度百科的三元组
17
May
如何“扒”站?手把手教你爬百度百科~
By 苏剑林 | 2017-05-17 | 31996位读者 | 引用
27
Aug
fashion mnist的一个baseline (MobileNet 95%)
By 苏剑林 | 2017-08-27 | 76097位读者 | 引用浅尝
昨天简单试了一下在fashion mnist的gan模型,发现还能work,当然那个尝试也没什么技术水平,就是把原来的脚本改一下路径跑了就完事。今天回到fashion mnist本身的主要任务——10分类,用Keras测了一下一些模型在上面的分类效果,最后得到了94.5%左右的准确率,加上随机翻转的数据扩增能做到95%。
首先随便手写了一些模型的组合,测试发现准确率都不大好,看来对于这个数据集来说,自己构思模型是比较困难的了,于是想着用现成的模型结构。一说到现成的cnn模型,基本上我们都会想到VGG、ResNet、inception、Xception等,但这些模型为解决imagenet的1000分类问题而设计,用到这个入门级别的数据集上似乎过于庞大了,而且也容易过拟合。后来突然想起,Keras好像自带了个叫MobileNet的模型,查看了一下模型权重,发现参数量不大,但是容量应该还是可以的,故选用MobileNet做实验。
深究
21
Jul
中山大学力学网络教程
By 苏剑林 | 2010-07-21 | 18506位读者 | 引用
中山大学力学教程-目录图
为了避免以后出现资源无法访问的问题,BoJone把这部分内容拷贝到了科学空间的服务器上。
您现在所看到的版本,是位于“科学空间”服务器上的。

最近评论