






17
Mar
你所没有思考过的平行线问题
By 苏剑林 | 2015-03-17 | 35009位读者 | 引用
欧几里得
本文的主题是平行线,了解数学的朋友可能会想我会写有关非欧几何的内容。但这次不是,本文的内容纯粹是我们从小就开始学习的欧氏几何,基于“欧几里得第五公设”(又称平行公设)。但即便是从小就学习的欧氏几何中的平行线,也许里边的很多问题我们都没有思考清楚。因为平行是几何中非常基本的情形,因此,在讨论这种基本命题的时候,相当容易会出现循环论证、甚至本末倒置的情况。
我们从初中开始就被灌输“同位角相等,两直线平行”、“内错角相等,两直线平行”之类的平行线判断法则,当然,还少不了的是“过直线外一点只能作一条直线与已知直线平行”。但是,这些内容之中,有多少是基本的公理,有多少是可以证明的,该如何证明,我想很多人都理解不清楚,我自己也没有一个很好的答案。那些在初中教授平行线的老师们,估计也没多少个能够把它说清楚的。后来我发现,我居然不会证明“同位角相等,两直线平行”,“欧几里得第五公设”好像并没有告诉我们这个判定法则呀。于是,我翻看了一下初中的数学教科书,发现原来当初“同位角相等,两直线平行”这一判定法则是不加证明地让我们接受的,无怪乎我怎么也想不到关于这一法则的简单的证明...
于是,我想写这篇文章,为大家理解平行线的整个逻辑提供一点参考。
20
Mar
[欧拉数学]伯努利级数及相关级数的总结
By 苏剑林 | 2016-03-20 | 94304位读者 | 引用最近在算路径积分的时候,频繁地遇到了以下两种无穷级数:
$$\sum_n \frac{1}{n^2\pm\omega^2}\quad \text{和} \quad \prod_n \left(1\pm\frac{\omega^2}{n^2}\right)$$
当然,直接用Mathematica可以很干脆地算出结果来,但是我还是想知道为什么,至少大概地知道。
伯努利级数
当$\omega=0$的时候,第一个级数变为著名的伯努利级数
$$\sum_n \frac{1}{n^2}=1+\frac{1}{4}+\frac{1}{9}+\frac{1}{16}+\dots$$
既然跟伯努利级数有关,那么很自然想到,从伯努利级数的求和入手。
6
Nov
【外微分浅谈】5. 几何意义
By 苏剑林 | 2016-11-06 | 69190位读者 | 引用对于前面所述的外微分,包括后面还略微涉及到的微分形式的积分,都是纯粹代数定义的内容,本身不具有任何的几何意义。但是,我们可以将某些公式或者定义,与一些几何内容对应起来,使我们更深刻地理解它,并且更灵活运用它。但是,它仅仅是一种对应,而且取决于我们的诠释。比如,我们说外微分公式
$$\int_{\partial D} Pdx+Qdy = \int_{D} \left(\frac{\partial Q}{\partial x}-\frac{\partial P}{\partial y}\right)dx\land dy \tag{32} $$
对应于格林公式
$$\int_{\partial D} Pdx+Qdy = \int_{D} \left(\frac{\partial Q}{\partial x}-\frac{\partial P}{\partial y}\right)dxdy \tag{33} $$
。这是没问题的,但它们并不等价,它们仅仅是形式上刚好一样。因为格林公式是描述闭合曲线的积分跟面积分的联系,而外微分的公式是一种纯粹的代数运算。因为你完全可以将$dx\land dy$对应于$-dxdy$而不是$dxdy$,这样就得到另外一种几何的对应。
更深刻的问题是:为什么恰好有这个对应?也就是说,为什么经过一些调整和诠释后,就能够得到与积分公式的对应?首先要明确的是外积与普通的数的乘积,除了反对称性之外,是没有任何区别的,因此不少性质得以保留;其次,还应该要回到反对称本身来考虑,矩阵的行列式代表着矩阵所对应的向量组张成的$n$维立体的体积,然而行列式是反对称的,这就意味着反对称运算跟体积、积分等有着先天的联系。当然,更细致的认识,笔者也还没做到。
此外,我们说寻求微分形式的几何意义,通常只是针对不超过3维的空间来讨论的,更高维的几何图像我们很难想象出来,尤其是高维的曲面积分,一般只是类比,但类比是否成立,有时还需要进一步商榷。因此,这种情况下,倒不如干脆点,说微分形式描述的东西就是几何,而不再去寻找所谓的几何意义了。也就是说,反过来,将微分形式和外微分作为公理式的第一性原理来定义几何。
甚至,你可以只将外微分当作是一种记忆各种微分、积分公式的有效途径,比如现在我要大家默写三维空间中的斯托克斯公式,大家估计会乱,因为不一定记得是哪个减哪个。但是在外微分框架下,可以很快地将它推导一遍。好比式$(11)$,如果非要寻求几何解释,那就是开普勒第二定律:单位时间内扫过的面积相等;然而没有几何解释,你依旧可以把方程解下去。
21
Mar
细水长flow之可逆ResNet:极致的暴力美学
By 苏剑林 | 2019-03-21 | 110171位读者 | 引用今天我们来介绍一个非常“暴力”的模型:可逆ResNet。
为什么一个模型可以可以用“暴力”来形容呢?当然是因为它确实非常暴力:它综合了很多数学技巧,活生生地(在一定约束下)把常规的ResNet模型搞成了可逆的!
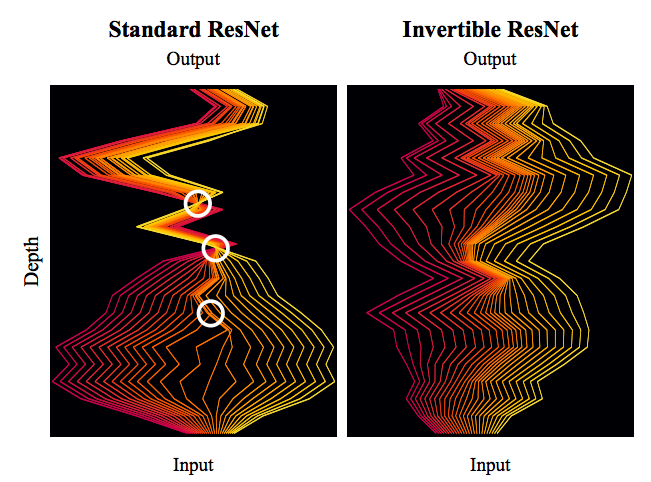
标准ResNet与可逆ResNet对比图。可逆ResNet允许信息无损可逆流动,而标准ResNet在某处则存在“坍缩”现象。
模型出自《Invertible Residual Networks》,之前在机器之心也报导过。在这篇文章中,我们来简单欣赏一下它的原理和内容。
可逆模型的点滴
为什么要研究可逆ResNet模型?它有什么好处?以前没有人研究过吗?
可逆的好处
可逆意味着什么?
意味着它是信息无损的,意味着它或许可以用来做更好的分类网络,意味着可以直接用最大似然来做生成模型,而且得益于ResNet强大的能力,意味着它可能有着比之前的Glow模型更好的表现~总而言之,如果一个模型是可逆的,可逆的成本不高而且拟合能力强,那么它就有很广的用途(分类、密度估计和生成任务,等等)。
8
Jul
两个多元正态分布的KL散度、巴氏距离和W距离
By 苏剑林 | 2021-07-08 | 101188位读者 | 引用正态分布是最常见的连续型概率分布之一。它是给定均值和协方差后的最大熵分布(参考《“熵”不起:从熵、最大熵原理到最大熵模型(二)》),也可以看作任意连续型分布的二阶近似,它的地位就相当于一般函数的线性近似。从这个角度来看,正态分布算得上是最简单的连续型分布了。也正因为简单,所以对于很多估计量来说,它都能写出解析解来。
本文主要来计算两个多元正态分布的几种度量,包括KL散度、巴氏距离和W距离,它们都有显式解析解。
正态分布
这里简单回顾一下正态分布的一些基础知识。注意,仅仅是回顾,这还不足以作为正态分布的入门教程。
概率密度
正态分布,也即高斯分布,是定义在$\mathbb{R}^n$上的连续型概率分布,其概率密度函数为
\begin{equation}p(\boldsymbol{x})=\frac{1}{\sqrt{(2\pi)^n \det(\boldsymbol{\Sigma})}}\exp\left\{-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{\top}\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right\}\end{equation}
8
Feb
多任务学习漫谈(二):行梯度之事
By 苏剑林 | 2022-02-08 | 50594位读者 | 引用在《多任务学习漫谈(一):以损失之名》中,我们从损失函数的角度初步探讨了多任务学习问题,最终发现如果想要结果同时具有缩放不变性和平移不变性,那么用梯度的模长倒数作为任务的权重是一个比较简单的选择。我们继而分析了,该设计等价于将每个任务的梯度单独进行归一化后再相加,这意味着多任务的“战场”从损失函数转移到了梯度之上:看似在设计损失函数,实则在设计更好的梯度,所谓“以损失之名,行梯度之事”。
那么,更好的梯度有什么标准呢?如何设计出更好的梯度呢?本文我们就从梯度的视角来理解多任务学习,试图直接从设计梯度的思路出发构建多任务学习算法。
整体思路
我们知道,对于单任务学习,常用的优化方法就是梯度下降,那么它是怎么推导的呢?同样的思路能不能直接用于多任务学习呢?这便是这一节要回答的问题。
14
Feb
多任务学习漫谈(三):分主次之序
By 苏剑林 | 2022-02-14 | 34646位读者 | 引用多任务学习是一个很宽泛的命题,不同场景下多任务学习的目标不尽相同。在《多任务学习漫谈(一):以损失之名》和《多任务学习漫谈(二):行梯度之事》中,我们将多任务学习的目标理解为“做好每一个任务”,具体表现是“尽量平等地处理每一个任务”,我们可以称之为“平行型多任务学习”。然而,并不是所有多任务学习的目标都是如此,在很多场景下,我们主要还是想学好某一个主任务,其余任务都只是辅助,希望通过增加其他任务的学习来提升主任务的效果罢了,此类场景我们可以称为“主次型多任务学习”。
在这个背景下,如果还是沿用平行型多任务学习的“做好每一个任务”的学习方案,那么就可能会明显降低主任务的效果了。所以本文继续沿着“行梯度之事”的想法,探索主次型多任务学习的训练方案。
目标形式
在这篇文章中,我们假设读者已经阅读并且基本理解《多任务学习漫谈(二):行梯度之事》里边的思想和方法,那么在梯度视角下,让某个损失函数保持下降的必要条件是更新量与其梯度夹角至少大于90度,这是贯穿全文的设计思想。
20
Apr
你的语言模型有没有“无法预测的词”?
By 苏剑林 | 2022-04-20 | 20113位读者 | 引用众所周知,分类模型通常都是先得到编码向量,然后接一个Dense层预测每个类别的概率,而预测时则是输出概率最大的类别。但大家是否想过这样一种可能:训练好的分类模型可能存在“无法预测的类别”,即不管输入是什么,都不可能预测出某个类别$k$,类别$k$永远不可能成为概率最大的那个。
当然,这种情况一般只出现在类别数远远超过编码向量维度的场景,常规的分类问题很少这么极端的。然而,我们知道语言模型本质上也是一个分类模型,它的类别数也就是词表的总大小,往往是远超过向量维度的,那么我们的语言模型是否有“无法预测的词”?(只考虑Greedy解码)
是否存在
ACL2022的论文《Low-Rank Softmax Can Have Unargmaxable Classes in Theory but Rarely in Practice》首先探究了这个问题,正如其标题所言,答案是“理论上存在但实际出现概率很小”。

最近评论