






7
Sep
BytePiece:更纯粹、更高压缩率的Tokenizer
By 苏剑林 | 2023-09-07 | 51423位读者 | 引用目前在LLM中最流行的Tokenizer(分词器)应该是Google的SentencePiece了,因为它符合Tokenizer的一些理想特性,比如语言无关、数据驱动等,并且由于它是C++写的,所以Tokenize(分词)的速度很快,非常适合追求效率的场景。然而,它也有一些明显的缺点,比如训练速度慢(BPE算法)、占用内存大等,同时也正因为它是C++写的,对于多数用户来说它就是黑箱,也不方便研究和二次开发。
事实上,Tokenizer的训练就相当于以往的“新词发现”,而笔者之前也写过中文分词和最小熵系列文章,对新词发现也有一定的积累,所以很早之前就有自己写一版Tokenizer的想法。这几天总算腾出了时间初步完成了这件事情,东施效颦SentencePiece,命名为“BytePiece”。
1
Jan
新年快乐!记录一下 Cool Papers 的开发体验
By 苏剑林 | 2024-01-01 | 53942位读者 | 引用上周在《写了个刷论文的辅助网站:Cool Papers》中,笔者分享了一个自己开发的刷论文网站Cool Papers,并得到了一些用户的认可。然而,“使用的人越多,暴露的问题就越多”,当用户量上来后,才感觉到之前写的代码是多么不严谨,于是过去一整周都在不停地修Bug之中,直到今天下午还发现了一个Bug在修。这篇文章简单总结一下笔者在开发和修Bug过程中的感想。
Cool Papers:https://papers.cool
技术
事实上,“papers.cool”这个域名已经注册了四年多,从这可以看出笔者其实很早以前就计划着做类似Cool Papers的网站,也做过一些雏形,但之所以这个网站在四年后才正式诞生,根本原因就只有一个:技术不行。
12
Feb
再来一顿贺岁宴:从K-Means到Capsule
By 苏剑林 | 2018-02-12 | 220616位读者 | 引用在本文中,我们再次对Capsule进行一次分析。
整体上来看,Capsule算法的细节不是很复杂,对照着它的流程把Capsule用框架实现它基本是没问题的。所以,困难的问题是理解Capsule究竟做了什么,以及为什么要这样做,尤其是Dynamic Routing那几步。
为什么我要反复对Capsule进行分析?这并非单纯的“炒冷饭”,而是为了得到对Capsule原理的理解。众所周知,Capsule给人的感觉就是“有太多人为约定的内容”,没有一种“虽然我不懂,但我相信应该就是这样”的直观感受。我希望尽可能将Capsule的来龙去脉思考清楚,使我们能觉得Capsule是一个自然、流畅的模型,甚至对它举一反三。
在《揭开迷雾,来一顿美味的Capsule盛宴》中,笔者先分析了动态路由的结果,然后指出输出是输入的某种聚类,这个“从结果到原因”的过程多多少少有些望文生义的猜测成分;这次则反过来,直接确认输出是输入的聚类,然后反推动态路由应该是怎样的,其中含糊的成分大大减少。两篇文章之间有一定的互补作用。
20
Dec
从动力学角度看优化算法(二):自适应学习率算法
By 苏剑林 | 2018-12-20 | 46761位读者 | 引用在《从动力学角度看优化算法(一):从SGD到动量加速》一文中,我们提出SGD优化算法跟常微分方程(ODE)的数值解法其实是对应的,由此还可以很自然地分析SGD算法的收敛性质、动量加速的原理等等内容。
在这篇文章中,我们继续沿着这个思路,去理解优化算法中的自适应学习率算法。
RMSprop
首先,我们看一个非常经典的自适应学习率优化算法:RMSprop。RMSprop虽然不是最早提出的自适应学习率的优化算法,但是它却是相当实用的一种,它是诸如Adam这样的更综合的算法的基石,通过它我们可以观察自适应学习率的优化算法是怎么做的。
算法概览
一般的梯度下降是这样的:
$$\begin{equation}\boldsymbol{\theta}_{n+1}=\boldsymbol{\theta}_{n} - \gamma \nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}_{n})\end{equation}$$
很明显,这里的$\gamma$是一个超参数,便是学习率,它可能需要在不同阶段做不同的调整。
而RMSprop则是
$$\begin{equation}\begin{aligned}\boldsymbol{g}_{n+1} =& \nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}_{n})\\
\boldsymbol{G}_{n+1}=&\lambda \boldsymbol{G}_{n} + (1 - \lambda) \boldsymbol{g}_{n+1}\otimes \boldsymbol{g}_{n+1}\\
\boldsymbol{\theta}_{n+1}=&\boldsymbol{\theta}_{n} - \frac{\tilde{\gamma}}{\sqrt{\boldsymbol{G}_{n+1} + \epsilon}}\otimes \boldsymbol{g}_{n+1}
\end{aligned}\end{equation}$$
18
Sep
从语言模型到Seq2Seq:Transformer如戏,全靠Mask
By 苏剑林 | 2019-09-18 | 321313位读者 | 引用相信近一年来(尤其是近半年来),大家都能很频繁地看到各种Transformer相关工作(比如Bert、GPT、XLNet等等)的报导,连同各种基础评测任务的评测指标不断被刷新。同时,也有很多相关的博客、专栏等对这些模型做科普和解读。
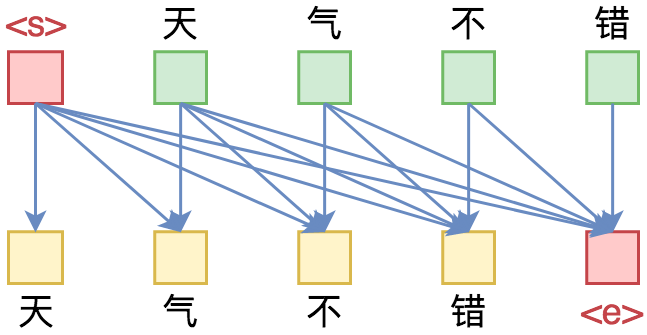
单向语言模型图示。每预测一个token,只依赖于前面的token。
俗话说,“外行看热闹,内行看门道”,我们不仅要在“是什么”这个层面去理解这些工作,我们还需要思考“为什么”。这个“为什么”不仅仅是“为什么要这样做”,还包括“为什么可以这样做”。比如,在谈到XLNet的乱序语言模型时,我们或许已经从诸多介绍中明白了乱序语言模型的好处,那不妨更进一步思考一下:
为什么Transformer可以实现乱序语言模型?是怎么实现的?RNN可以实现吗?
本文从对Attention矩阵进行Mask的角度,来分析为什么众多Transformer模型可以玩得如此“出彩”的基本原因,正如标题所述“Transformer如戏,全靠Mask”,这是各种花式Transformer模型的重要“门道”之一。
读完本文,你或许可以了解到:
1、Attention矩阵的Mask方式与各种预训练方案的关系;
2、直接利用预训练的Bert模型来做Seq2Seq任务。
10
Oct
从动力学角度看优化算法(五):为什么学习率不宜过小?
By 苏剑林 | 2020-10-10 | 52959位读者 | 引用本文的主题是“为什么我们需要有限的学习率”,所谓“有限”,指的是不大也不小,适中即可,太大容易导致算法发散,这不难理解,但为什么太小也不好呢?一个容易理解的答案是,学习率过小需要迭代的步数过多,这是一种没有必要的浪费,因此从“节能”和“加速”的角度来看,我们不用过小的学习率。但如果不考虑算力和时间,那么过小的学习率是否可取呢?Google最近发布在Arxiv上的论文《Implicit Gradient Regularization》试图回答了这个问题,它指出有限的学习率隐式地给优化过程带来了梯度惩罚项,而这个梯度惩罚项对于提高泛化性能是有帮助的,因此哪怕不考虑算力和时间等因素,也不应该用过小的学习率。
对于梯度惩罚,本博客已有过多次讨论,在文章《对抗训练浅谈:意义、方法和思考(附Keras实现)》和《泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练》中,我们就分析了对抗训练一定程度上等价于对输入的梯度惩罚,而文章《我们真的需要把训练集的损失降低到零吗?》介绍的Flooding技巧则相当于对参数的梯度惩罚。总的来说,不管是对输入还是对参数的梯度惩罚,都对提高泛化能力有一定帮助。
29
Jul
生活中的趣味数学:同一天生日概率有多大
By 苏剑林 | 2009-07-29 | 28608位读者 | 引用
21
Feb


最近评论