






 感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持!
感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持! 科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
5
Dec
智能家居之小爱同学控制极米投影仪的简单方案
By 苏剑林 | 2022-12-05 | 48523位读者 | Kimi 引用前段时间买了一个极米投影仪,开始折腾才发现极米跟小米基本没啥关系,它根本无法跟小爱同学互动。在众多名字带“米”的品牌中,极米是为数不多的无法接入米家生态的品牌,想必有不少用户开始都会被极米这个名字误导,关键是极米投影仪还在小米商城上有得卖(捂脸)。
买都买了,还过了七天无理由,退是退不成了,只能试着折腾一下,看看能不能强行互动。
现有方案
首先网上搜了一下,网友给出的参考方案大体上有几种,一种是用“米家智能插座 + 上电自动开机”来控制开关机(事实上主要的联动就是开关机了),一种是接入Home Assistant后通过ADB控制,还有一种是修改遥控器,给遥控器加入红外模块,继而用小爱同学的红外遥控功能。
30
Nov
用热传导方程来指导自监督学习
By 苏剑林 | 2022-11-30 | 53356位读者 | Kimi 引用用理论物理来卷机器学习已经不是什么新鲜事了,比如上个月介绍的《生成扩散模型漫谈(十三):从万有引力到扩散模型》就是经典一例。最近一篇新出的论文《Self-Supervised Learning based on Heat Equation》,顾名思义,用热传导方程来做(图像领域的)自监督学习,引起了笔者的兴趣。这种物理方程如何在机器学习中发挥作用?同样的思路能否迁移到NLP中?让我们一起来读读论文。
基本方程
如下图,左边是物理中热传导方程的解,右端则是CAM、积分梯度等显著性方法得到的归因热力图,可以看到两者有一定的相似之处,于是作者认为热传导方程可以作为好的视觉特征的一个重要先验。
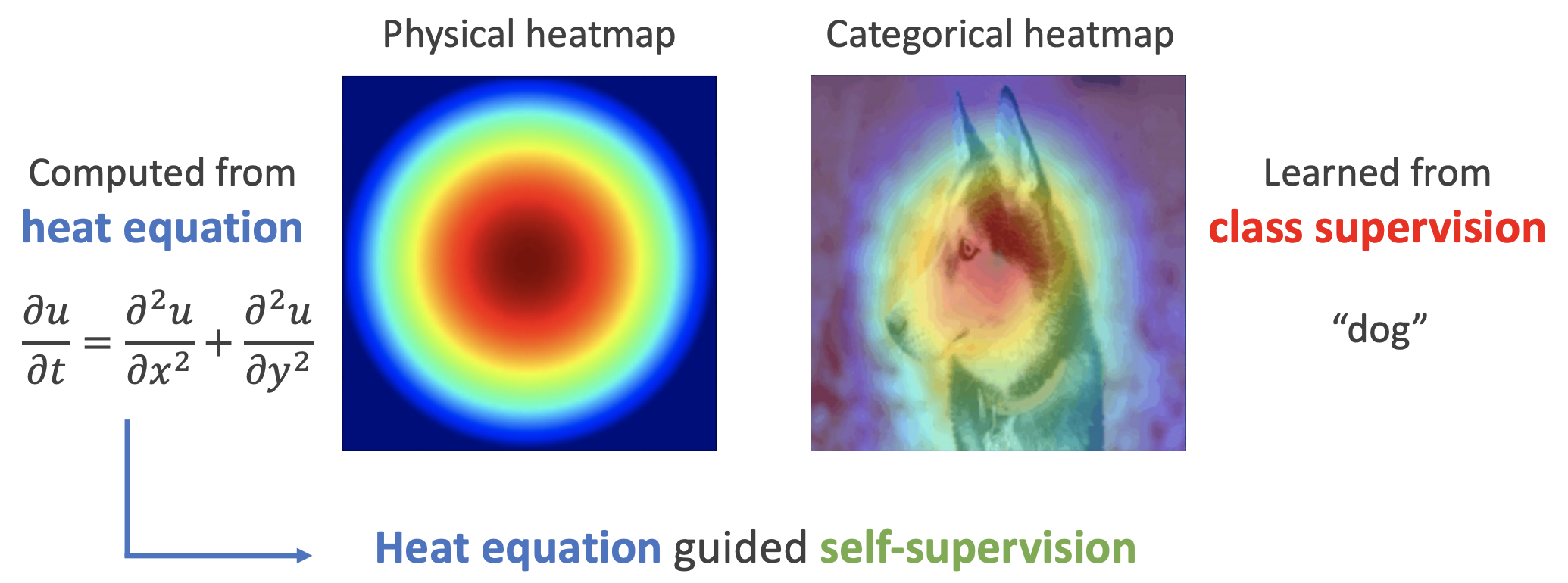
热方程的热力图(左)和视觉模型的热力图(右)
22
Nov
基于Amos优化器思想推导出来的一些“炼丹策略”
By 苏剑林 | 2022-11-22 | 49264位读者 | Kimi 引用如果将训练模型比喻为“炼丹”,那么“炼丹炉”显然就是优化器了。据传AdamW优化器是当前训练神经网络最快的方案,这一点笔者也没有一一对比过,具体情况如何不得而知,不过目前做预训练时多数都用AdamW或其变种LAMB倒是真的。然而,正如有了炼丹炉也未必能炼出好丹,即便我们确定了选择AdamW优化器,依然有很多问题还没有确定的答案,比如:
1、学习率如何适应不同初始化和参数化?
2、权重衰减率该怎么调?
3、学习率应该用什么变化策略?
4、能不能降低优化器的显存占用?
尽管在实际应用时,我们大多数情况下都可以直接套用前人已经调好的参数和策略,但缺乏比较系统的调参指引,始终会让我们在“炼丹”之时感觉没有底气。在这篇文章中,我们基于Google最近提出的Amos优化器的思路,给出一些参考结果。
9
Nov
CoSENT(三):作为交互式相似度的损失函数
By 苏剑林 | 2022-11-09 | 48942位读者 | Kimi 引用在《CoSENT(一):比Sentence-BERT更有效的句向量方案》中,笔者提出了名为“CoSENT”的有监督句向量方案,由于它是直接训练cos相似度的,跟评测目标更相关,因此通常能有着比Sentence-BERT更好的效果以及更快的收敛速度。在《CoSENT(二):特征式匹配与交互式匹配有多大差距?》中我们还比较过它跟交互式相似度模型的差异,显示它在某些任务上的效果还能直逼交互式相似度模型。
然而,当时笔者是一心想找一个更接近评测目标的Sentence-BERT替代品,所以结果都是面向有监督句向量的,即特征式相似度模型。最近笔者突然反应过来,CoSENT其实也能作为交互式相似度模型的损失函数。那么它跟标准选择交叉熵相比孰优孰劣呢?本文来补充这部分实验。
2
Nov
利用CUR分解加速交互式相似度模型的检索
By 苏剑林 | 2022-11-02 | 52953位读者 | Kimi 引用文本相似度有“交互式”和“特征式”两种做法,想必很多读者对此已经不陌生,之前笔者也写过一篇文章《CoSENT(二):特征式匹配与交互式匹配有多大差距?》来对比两者的效果。总的来说,交互式相似度效果通常会好些,但直接用它来做大规模检索是不现实的,而特征式相似度则有着更快的检索速度,以及稍逊一筹的效果。
因此,如何在保证交互式相似度效果的前提下提高它的检索速度,是学术界一直都有在研究的课题。近日,论文《Efficient Nearest Neighbor Search for Cross-Encoder Models using Matrix Factorization》提出了一份新的答卷:CUR分解。

CUR分解示意图
25
Oct
圆内随机n点在同一个圆心角为θ的扇形的概率
By 苏剑林 | 2022-10-25 | 60018位读者 | Kimi 引用
18
Oct
生成扩散模型漫谈(十三):从万有引力到扩散模型
By 苏剑林 | 2022-10-18 | 90739位读者 | Kimi 引用对于很多读者来说,生成扩散模型可能是他们遇到的第一个能够将如此多的数学工具用到深度学习上的模型。在这个系列文章中,我们已经展示了扩散模型与数学分析、概率统计、常微分方程、随机微分方程乃至偏微分方程等内容的深刻联系,可以说,即便是做数学物理方程的纯理论研究的同学,大概率也可以在扩散模型中找到自己的用武之地。
在这篇文章中,我们再介绍一个同样与数学物理有深刻联系的扩散模型——由“万有引力定律”启发的ODE式扩散模型,出自论文《Poisson Flow Generative Models》(简称PFGM),它给出了一个构建ODE式扩散模型的全新视角。
万有引力
中学时期我们就学过万有引力定律,大概的描述方式是:
两个质点彼此之间相互吸引的作用力,是与它们的质量乘积成正比,并与它们之间的距离成平方反比。
9
Oct

最近评论