






30
Nov
用热传导方程来指导自监督学习
By 苏剑林 | 2022-11-30 | 53478位读者 | 引用用理论物理来卷机器学习已经不是什么新鲜事了,比如上个月介绍的《生成扩散模型漫谈(十三):从万有引力到扩散模型》就是经典一例。最近一篇新出的论文《Self-Supervised Learning based on Heat Equation》,顾名思义,用热传导方程来做(图像领域的)自监督学习,引起了笔者的兴趣。这种物理方程如何在机器学习中发挥作用?同样的思路能否迁移到NLP中?让我们一起来读读论文。
基本方程
如下图,左边是物理中热传导方程的解,右端则是CAM、积分梯度等显著性方法得到的归因热力图,可以看到两者有一定的相似之处,于是作者认为热传导方程可以作为好的视觉特征的一个重要先验。
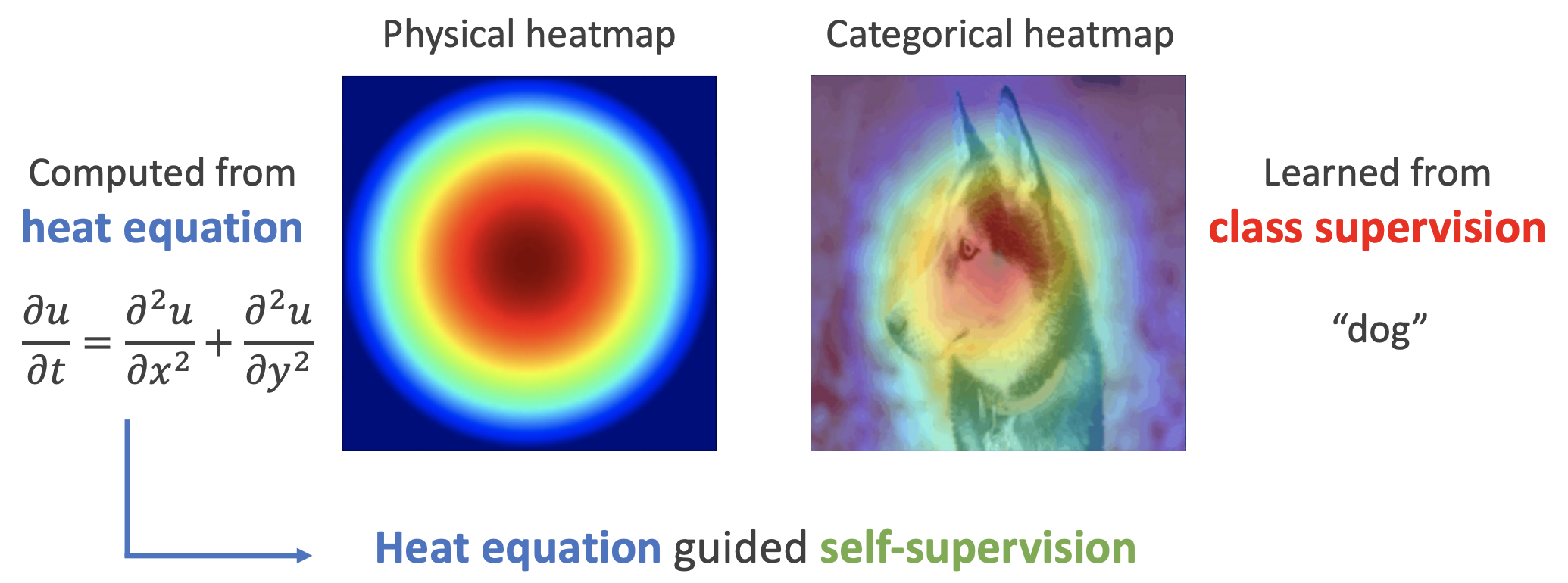
热方程的热力图(左)和视觉模型的热力图(右)
22
Nov
基于Amos优化器思想推导出来的一些“炼丹策略”
By 苏剑林 | 2022-11-22 | 49312位读者 | 引用如果将训练模型比喻为“炼丹”,那么“炼丹炉”显然就是优化器了。据传AdamW优化器是当前训练神经网络最快的方案,这一点笔者也没有一一对比过,具体情况如何不得而知,不过目前做预训练时多数都用AdamW或其变种LAMB倒是真的。然而,正如有了炼丹炉也未必能炼出好丹,即便我们确定了选择AdamW优化器,依然有很多问题还没有确定的答案,比如:
1、学习率如何适应不同初始化和参数化?
2、权重衰减率该怎么调?
3、学习率应该用什么变化策略?
4、能不能降低优化器的显存占用?
尽管在实际应用时,我们大多数情况下都可以直接套用前人已经调好的参数和策略,但缺乏比较系统的调参指引,始终会让我们在“炼丹”之时感觉没有底气。在这篇文章中,我们基于Google最近提出的Amos优化器的思路,给出一些参考结果。
9
Nov
CoSENT(三):作为交互式相似度的损失函数
By 苏剑林 | 2022-11-09 | 48967位读者 | 引用在《CoSENT(一):比Sentence-BERT更有效的句向量方案》中,笔者提出了名为“CoSENT”的有监督句向量方案,由于它是直接训练cos相似度的,跟评测目标更相关,因此通常能有着比Sentence-BERT更好的效果以及更快的收敛速度。在《CoSENT(二):特征式匹配与交互式匹配有多大差距?》中我们还比较过它跟交互式相似度模型的差异,显示它在某些任务上的效果还能直逼交互式相似度模型。
然而,当时笔者是一心想找一个更接近评测目标的Sentence-BERT替代品,所以结果都是面向有监督句向量的,即特征式相似度模型。最近笔者突然反应过来,CoSENT其实也能作为交互式相似度模型的损失函数。那么它跟标准选择交叉熵相比孰优孰劣呢?本文来补充这部分实验。
2
Nov
利用CUR分解加速交互式相似度模型的检索
By 苏剑林 | 2022-11-02 | 52991位读者 | 引用文本相似度有“交互式”和“特征式”两种做法,想必很多读者对此已经不陌生,之前笔者也写过一篇文章《CoSENT(二):特征式匹配与交互式匹配有多大差距?》来对比两者的效果。总的来说,交互式相似度效果通常会好些,但直接用它来做大规模检索是不现实的,而特征式相似度则有着更快的检索速度,以及稍逊一筹的效果。
因此,如何在保证交互式相似度效果的前提下提高它的检索速度,是学术界一直都有在研究的课题。近日,论文《Efficient Nearest Neighbor Search for Cross-Encoder Models using Matrix Factorization》提出了一份新的答卷:CUR分解。

CUR分解示意图
18
Oct
生成扩散模型漫谈(十三):从万有引力到扩散模型
By 苏剑林 | 2022-10-18 | 90860位读者 | 引用对于很多读者来说,生成扩散模型可能是他们遇到的第一个能够将如此多的数学工具用到深度学习上的模型。在这个系列文章中,我们已经展示了扩散模型与数学分析、概率统计、常微分方程、随机微分方程乃至偏微分方程等内容的深刻联系,可以说,即便是做数学物理方程的纯理论研究的同学,大概率也可以在扩散模型中找到自己的用武之地。
在这篇文章中,我们再介绍一个同样与数学物理有深刻联系的扩散模型——由“万有引力定律”启发的ODE式扩散模型,出自论文《Poisson Flow Generative Models》(简称PFGM),它给出了一个构建ODE式扩散模型的全新视角。
万有引力
中学时期我们就学过万有引力定律,大概的描述方式是:
两个质点彼此之间相互吸引的作用力,是与它们的质量乘积成正比,并与它们之间的距离成平方反比。
28
Sep
生成扩散模型漫谈(十二):“硬刚”扩散ODE
By 苏剑林 | 2022-09-28 | 138181位读者 | 引用在《生成扩散模型漫谈(五):一般框架之SDE篇》中,我们从SDE的角度理解了生成扩散模型,然后在《生成扩散模型漫谈(六):一般框架之ODE篇》中,我们知道SDE对应的扩散模型中,实际上隐含了一个ODE模型。无独有偶,在《生成扩散模型漫谈(四):DDIM = 高观点DDPM》中我们也知道原本随机采样的DDPM模型中,也隐含了一个确定性的采样过程DDIM,它的连续极限也是一个ODE。
细想上述过程,可以发现不管是“DDPM→DDIM”还是“SDE→ODE”,都是从随机采样模型过渡到确定性模型,而如果我们一开始的目标就是ODE,那么该过程未免显得有点“迂回”了。在本文中,笔者尝试给出ODE扩散模型的直接推导,并揭示了它与雅可比行列式、热传导方程等内容的联系。
微分方程
像GAN这样的生成模型,它本质上是希望找到一个确定性变换,能将从简单分布(如标准正态分布)采样出来的随机变量,变换为特定数据分布的样本。flow模型也是生成模型之一,它的思路是反过来,先找到一个能将数据分布变换简单分布的可逆变换,再求解相应的逆变换来得到一个生成模型。
21
Sep
生成扩散模型漫谈(十一):统一扩散模型(应用篇)
By 苏剑林 | 2022-09-21 | 72246位读者 | 引用在《生成扩散模型漫谈(十):统一扩散模型(理论篇)》中,笔者自称构建了一个统一的模型框架(Unified Diffusion Model,UDM),它允许更一般的扩散方式和数据类型。那么UDM框架究竟能否实现如期目的呢?本文通过一些具体例子来演示其一般性。
框架回顾
首先,UDM通过选择噪声分布$q(\boldsymbol{\varepsilon})$和变换$\boldsymbol{\mathcal{F}}$来构建前向过程
\begin{equation}\boldsymbol{x}_t = \boldsymbol{\mathcal{F}}_t(\boldsymbol{x}_0,\boldsymbol{\varepsilon}),\quad \boldsymbol{\varepsilon}\sim q(\boldsymbol{\varepsilon})\end{equation}
然后,通过如下的分解来实现反向过程$\boldsymbol{x}_{t-1}\sim p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t)$的采样
\begin{equation}\hat{\boldsymbol{x}}_0\sim p(\boldsymbol{x}_0|\boldsymbol{x}_t)\quad \& \quad \boldsymbol{x}_{t-1}\sim p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0=\hat{\boldsymbol{x}}_0)\end{equation}
其中$p(\boldsymbol{x}_0|\boldsymbol{x}_t)$就是用$\boldsymbol{x}_t$预估$\boldsymbol{x}_0$的概率,一般用简单分布$q(\boldsymbol{x}_0|\boldsymbol{x}_t)$来近似建模,训练目标基本上就是$-\log q(\boldsymbol{x}_0|\boldsymbol{x}_t)$或其简单变体。当$\boldsymbol{x}_0$是连续型数据时,$q(\boldsymbol{x}_0|\boldsymbol{x}_t)$一般就取条件正态分布;当$\boldsymbol{x}_0$是离散型数据时,$q(\boldsymbol{x}_0|\boldsymbol{x}_t)$可以选择自回归模型或者非自回归模型。
14
Sep
生成扩散模型漫谈(十):统一扩散模型(理论篇)
By 苏剑林 | 2022-09-14 | 126501位读者 | 引用老读者也许会发现,相比之前的更新频率,这篇文章可谓是“姗姗来迟”,因为这篇文章“想得太多”了。
通过前面九篇文章,我们已经对生成扩散模型做了一个相对全面的介绍。虽然理论内容很多,但我们可以发现,前面介绍的扩散模型处理的都是连续型对象,并且都是基于正态噪声来构建前向过程。而“想得太多”的本文,则希望能够构建一个能突破以上限制的扩散模型统一框架(Unified Diffusion Model,UDM):
1、不限对象类型(可以是连续型$\boldsymbol{x}$,也可以是离散型的$\boldsymbol{x}$);
2、不限前向过程(可以用加噪、模糊、遮掩、删减等各种变换构建前向过程);
3、不限时间类型(可以是离散型的$t$,也可以是连续型的$t$);
4、包含已有结果(可以推出前面的DDPM、DDIM、SDE、ODE等结果)。
这是不是太过“异想天开”了?有没有那么理想的框架?本文就来尝试一下。

最近评论