






6
May
变分自编码器(五):VAE + BN = 更好的VAE
By 苏剑林 | 2020-05-06 | 299228位读者 |本文我们继续之前的变分自编码器系列,分析一下如何防止NLP中的VAE模型出现“KL散度消失(KL Vanishing)”现象。本文受到参考文献是ACL 2020的论文《A Batch Normalized Inference Network Keeps the KL Vanishing Away》的启发,并自行做了进一步的完善。
值得一提的是,本文最后得到的方案还是颇为简洁的——只需往编码输出加入BN(Batch Normalization),然后加个简单的scale——但确实很有效,因此值得正在研究相关问题的读者一试。同时,相关结论也适用于一般的VAE模型(包括CV的),如果按照笔者的看法,它甚至可以作为VAE模型的“标配”。
最后,要提醒读者这算是一篇VAE的进阶论文,所以请读者对VAE有一定了解后再来阅读本文。
VAE简单回顾 #
这里我们简单回顾一下VAE模型,并且讨论一下VAE在NLP中所遇到的困难。关于VAE的更详细介绍,请读者参考笔者的旧作《变分自编码器(一):原来是这么一回事》、《变分自编码器(二):从贝叶斯观点出发》等。
VAE的训练流程 #
VAE的训练流程大概可以图示为
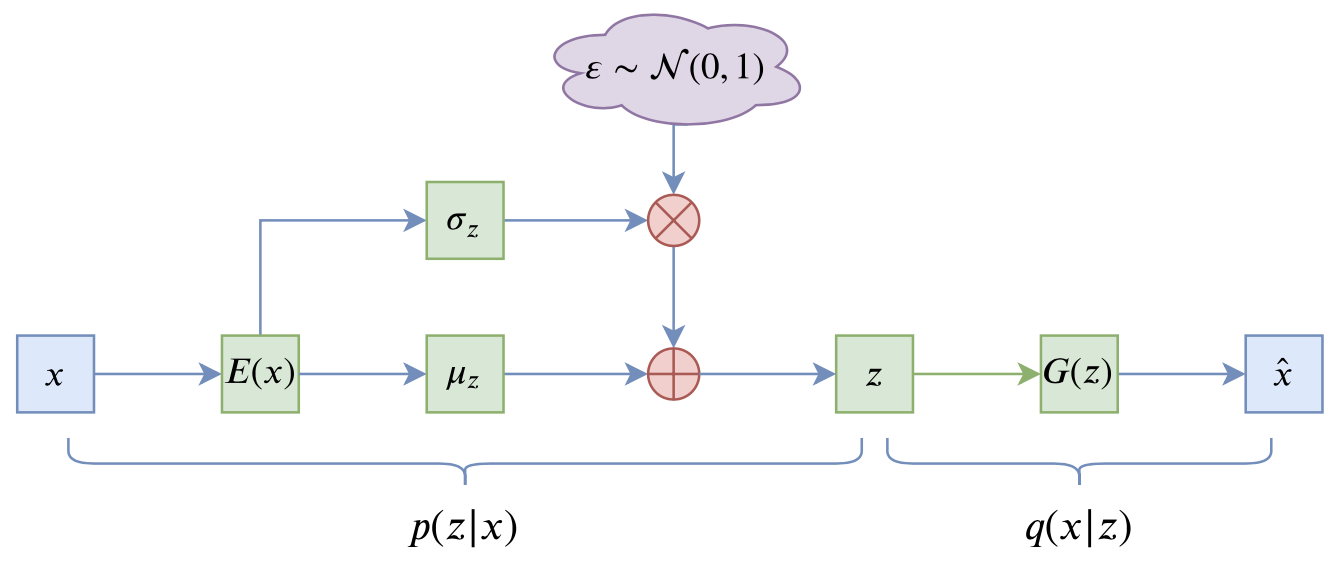
VAE训练流程图示
写成公式就是
$$\begin{equation}\mathcal{L} = \mathbb{E}_{x\sim \tilde{p}(x)} \Big[\mathbb{E}_{z\sim p(z|x)}\big[-\log q(x|z)\big]+KL\big(p(z|x)\big\Vert q(z)\big)\Big]
\end{equation}$$
其中第一项就是重构项,$\mathbb{E}_{z\sim p(z|x)}$是通过重参数来实现;第二项则称为KL散度项,这是它跟普通自编码器的显式差别,如果没有这一项,那么基本上退化为常规的AE。更详细的符号含义可以参考《变分自编码器(二):从贝叶斯观点出发》。
NLP中的VAE #
在NLP中,句子被编码为离散的整数ID,所以$q(x|z)$是一个离散型分布,可以用万能的“条件语言模型”来实现,因此理论上$q(x|z)$可以精确地拟合生成分布,问题就出在$q(x|z)$太强了,训练时重参数操作会来噪声,噪声一大,$z$的利用就变得困难起来,所以它干脆不要$z$了,退化为无条件语言模型(依然很强),$KL(p(z|x)\Vert q(z))$则随之下降到0,这就出现了KL散度消失现象。
这种情况下的VAE模型并没有什么价值:KL散度为0说明编码器输出的是常数向量,而解码器则是一个普通的语言模型。而我们使用VAE通常来说是看中了它无监督构建编码向量的能力,所以要应用VAE的话还是得解决KL散度消失问题。事实上从2016开始,有不少工作在做这个问题,相应地也提出了很多方案,比如退火策略、更换先验分布等,读者Google一下“KL Vanishing”就可以找到很多文献了,这里不一一溯源。
BN的巧与妙 #
本文的方案则是直接针对KL散度项入手,简单有效而且没什么超参数。其思想很简单:
KL散度消失不就是KL散度项变成0吗?我调整一下编码器输出,让KL散度有一个大于零的下界,这样它不就肯定不会消失了吗?
这个简单的思想的直接结果就是:在$\mu$后面加入BN层,如图

往VAE里加入BN
推导过程简述 #
为什么会跟BN联系起来呢?我们来看KL散度项的形式:
\begin{equation}\mathbb{E}_{x\sim\tilde{p}(x)}\left[KL\big(p(z|x)\big\Vert q(z)\big)\right] = \frac{1}{b} \sum_{i=1}^b \sum_{j=1}^d \frac{1}{2}\Big(\mu_{i,j}^2 + \sigma_{i,j}^2 - \log \sigma_{i,j}^2 - 1\Big)\end{equation}
上式是采样了$b$个样本进行计算的结果,而编码向量的维度则是$d$维。由于我们总是有$e^x \geq x + 1$,所以$\sigma_{i,j}^2 - \log \sigma_{i,j}^2 - 1 \geq 0$,因此
\begin{equation}\mathbb{E}_{x\sim\tilde{p}(x)}\left[KL\big(p(z|x)\big\Vert q(z)\big)\right] \geq \frac{1}{b} \sum_{i=1}^b \sum_{j=1}^d \frac{1}{2}\mu_{i,j}^2 = \frac{1}{2}\sum_{j=1}^d \left(\frac{1}{b} \sum_{i=1}^b \mu_{i,j}^2\right)\label{eq:kl}\end{equation}
留意到括号里边的量,其实它就是$\mu$在batch内的二阶矩,如果我们往$\mu$加入BN层,那么大体上可以保证$\mu$的均值为$\beta$,方差为$\gamma^2$($\beta,\gamma$是BN里边的可训练参数),这时候
\begin{equation}\mathbb{E}_{x\sim\tilde{p}(x)}\left[KL\big(p(z|x)\big\Vert q(z)\big)\right] \geq \frac{d}{2}\left(\beta^2 + \gamma^2\right)\label{eq:kl-lb}\end{equation}
所以只要控制好$\beta,\gamma$(主要是固定$\gamma$为某个常数),就可以让KL散度项有个正的下界,因此就不会出现KL散度消失现象了。这样一来,KL散度消失现象跟BN就被巧妙地联系起来了,通过BN来“杜绝”了KL散度消失的可能性。
为什么不是LN? #
善于推导的读者可能会想到,按照上述思路,如果只是为了让KL散度项有个正的下界,其实LN(Layer Normalization)也可以,也就是在式$\eqref{eq:kl}$中按$j$那一维归一化。
那为什么用BN而不是LN呢?
这个问题的答案也是BN的巧妙之处。直观来理解,KL散度消失是因为$z\sim p(z|x)$的噪声比较大,解码器无法很好地辨别出$z$中的非噪声成分,所以干脆弃之不用;而当给$\mu(x)$加上BN后,相当于适当地拉开了不同样本的$z$的距离,使得哪怕$z$带了噪声,区分起来也容易一些,所以这时候解码器乐意用$z$的信息,因此能缓解这个问题;相比之下,LN是在样本内进的行归一化,没有拉开样本间差距的作用,所以LN的效果不会有BN那么好。
进一步的结果 #
事实上,原论文的推导到上面基本上就结束了,剩下的都是实验部分,包括通过实验来确定$\gamma$的值。然而,笔者认为目前为止的结论还有一些美中不足的地方,比如没有提供关于加入BN的更深刻理解,倒更像是一个工程的技巧,又比如只是$\mu(x)$加上了BN,$\sigma(x)$没有加上,未免有些不对称之感。
经过笔者的推导,发现上面的结论可以进一步完善。
联系到先验分布 #
对于VAE来说,它希望训练好后的模型的隐变量分布为先验分布$q(z)=\mathcal{N}(z;0,1)$,而后验分布则是$p(z|x)=\mathcal{N}(z; \mu(x),\sigma^2(x))$,所以VAE希望下式成立:
\begin{equation}q(z) = \int \tilde{p}(x)p(z|x)dx=\int \tilde{p}(x)\mathcal{N}(z; \mu(x),\sigma^2(x))dx\end{equation}
两边乘以$z$,并对$z$积分,得到
\begin{equation}0 = \int \tilde{p}(x)\mu(x)dx=\mathbb{E}_{x\sim \tilde{p}(x)}[\mu(x)]\end{equation}
两边乘以$z^2$,并对$z$积分,得到
\begin{equation}1 = \int \tilde{p}(x)\left[\mu^2(x) + \sigma^2(x)\right]dx = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\mu^2(x)\right] + \mathbb{E}_{x\sim \tilde{p}(x)}\left[\sigma^2(x)\right]\end{equation}
如果往$\mu(x),\sigma(x)$都加入BN,那么我们就有
\begin{equation}\begin{aligned}
&0 = \mathbb{E}_{x\sim \tilde{p}(x)}[\mu(x)] = \beta_{\mu}\\
&1 = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\mu^2(x)\right] + \mathbb{E}_{x\sim \tilde{p}(x)}\left[\sigma^2(x)\right] = \beta_{\mu}^2 + \gamma_{\mu}^2 + \beta_{\sigma}^2 + \gamma_{\sigma}^2
\end{aligned}\end{equation}
所以现在我们知道$\beta_{\mu}$一定是0,而如果我们也固定$\beta_{\sigma}=0$,那么我们就有约束关系:
\begin{equation}1 = \gamma_{\mu}^2 + \gamma_{\sigma}^2\label{eq:gamma2}\end{equation}
参考的实现方案 #
经过这样的推导,我们发现可以往$\mu(x),\sigma(x)$都加入BN,并且可以固定$\beta_{\mu}=\beta_{\sigma}=0$,但此时需要满足约束$\eqref{eq:gamma2}$。要注意的是,这部分讨论还仅仅是对VAE的一般分析,并没有涉及到KL散度消失问题,哪怕这些条件都满足了,也无法保证KL项不趋于0。结合式$\eqref{eq:kl-lb}$我们可以知道,保证KL散度不消失的关键是确保$\gamma_{\mu} > 0$,所以,笔者提出的最终策略是:
\begin{equation}\begin{aligned}
&\beta_{\mu}=\beta_{\sigma}=0\\
&\gamma_{\mu} = \sqrt{\tau + (1-\tau)\cdot\text{sigmoid}(\theta)}\\
&\gamma_{\sigma} = \sqrt{(1-\tau)\cdot\text{sigmoid}(-\theta)}
\end{aligned}\end{equation}
其中$\tau\in(0,1)$是一个常数,笔者在自己的实验中取了$\tau=0.5$,而$\theta$是可训练参数,上式利用了恒等式$\text{sigmoid}(-\theta) = 1-\text{sigmoid}(\theta)$。
关键代码参考(Keras):
class Scaler(Layer):
"""特殊的scale层
"""
def __init__(self, tau=0.5, **kwargs):
super(Scaler, self).__init__(**kwargs)
self.tau = tau
def build(self, input_shape):
super(Scaler, self).build(input_shape)
self.scale = self.add_weight(
name='scale', shape=(input_shape[-1],), initializer='zeros'
)
def call(self, inputs, mode='positive'):
if mode == 'positive':
scale = self.tau + (1 - self.tau) * K.sigmoid(self.scale)
else:
scale = (1 - self.tau) * K.sigmoid(-self.scale)
return inputs * K.sqrt(scale)
def get_config(self):
config = {'tau': self.tau}
base_config = super(Scaler, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
def sampling(inputs):
"""重参数采样
"""
z_mean, z_std = inputs
noise = K.random_normal(shape=K.shape(z_mean))
return z_mean + z_std * noise
e_outputs # 假设e_outputs是编码器的输出向量
scaler = Scaler()
z_mean = Dense(hidden_dims)(e_outputs)
z_mean = BatchNormalization(scale=False, center=False, epsilon=1e-8)(z_mean)
z_mean = scaler(z_mean, mode='positive')
z_std = Dense(hidden_dims)(e_outputs)
z_std = BatchNormalization(scale=False, center=False, epsilon=1e-8)(z_std)
z_std = scaler(z_std, mode='negative')
z = Lambda(sampling, name='Sampling')([z_mean, z_std])
文章内容小结 #
本文简单分析了VAE在NLP中的KL散度消失现象,并介绍了通过BN层来防止KL散度消失、稳定训练流程的方法。这是一种简洁有效的方案,不单单是原论文,笔者私下也做了简单的实验,结果确实也表明了它的有效性,值得各位读者试用。因为其推导具有一般性,所以甚至任意场景(比如CV)中的VAE模型都可以尝试一下。
转载到请包括本文地址:https://kexue.fm/archives/7381
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (May. 06, 2020). 《 变分自编码器(五):VAE + BN = 更好的VAE 》[Blog post]. Retrieved from https://kexue.fm/archives/7381
@online{kexuefm-7381,
title={ 变分自编码器(五):VAE + BN = 更好的VAE},
author={苏剑林},
year={2020},
month={May},
url={\url{https://kexue.fm/archives/7381}},
}

October 17th, 2022
苏老师您好,我看下来VAE这个系列觉得您的推理非常有条理,十分受教,不过有几个积攒下来的问题一直有一点疑惑麻烦您解答一下~
1、p(z|x)和q(x|z)我理解是从联合分布设定得到的,并没有像以前那种假定p是真实分布,q是模型分布来接近p是吗?
2、隐变量其实指的是编码器的输出吗?只考虑输出的特征向量,并没有考虑它和输入样本的关系,然后后验概率是对二者关系的表示,这样就能理解希望隐变量是标准正态分布而后验概率不是。不过我记得您在第一篇讲解中也提到了希望后验概率是标准正态分布然后得到隐变量的分布是标准正态分布,但是本文公式5的上面说希望后验概率服从正态分布,这里我就有一点疑惑为什么不是标准正态分布了
3、z包含噪声怎么理解呢?是说采样采到的数据不确定吗?因为我觉得z的方差是服从后验概率的方差的,这个时候它和x的联系还是比较密切的,就不太理解这里的噪声是什么意思,所以就不理解解码器不利用z是什么意思了
4、您在说为什么不用层归一化时说的不同样本z的距离是什么意思呢?这部分也不太理解
1、$p$也是有参数的,$p$、$q$是相互接近,没有谁逼近谁;
2、我从没说过“希望”$p(z|x)$是标准正态分布,第一篇说过是通过$p(z|x)$向标准正态分布看齐,以实现$p(z)$是标准正态分布的目的;
3、如果$p(z|x)=\mathcal{N}(z;0.0000001x, 1)$呢?还密切吗?你怎么断定它一定就会密切?(反过来说,所有解决KL散度消失问题的策略,都是为了保证它密切,所以密切并不是一件显然成立的事情)
4、就是“不同样本”的“z”的“距离”的意思,请思考和想象一下。
谢谢您,我大概理解您的答复,但是我之前提问可能没有表述清楚我的疑问之处,所以我再描述一下我的理解和疑问:
1、我理解您说的互相接近的观点,但我其实主要是想搞清楚“p(z|x)和q(x|z)没有用统一的符号来表示比如都是p或都是q”这个问题,因为我觉得如果用符号来分别表示编码器和解码器的话,应该是符号统一的。关于这个问题,我根据第二篇的讲解的理解是它们是由真正的联合分布p(x,z)和模型得到的联合分布q(x,z)定义来的,或者说就是直接定义的符号,但是这样的理解并没有说服我自己,所以还请您再解答一下p和q的符号差异问题
2、您第一篇确实说的是“通过p(z|x)向标准正态分布看齐,以实现p(z)是标准正态分布的目的”,然后我的理解是在训练过程中,由于重构损失和这个“p(z|x)与标准正态分布的KL距离”二者的对抗关系使得p(z|x)最后只是一个正态分布而并非标准正态分布,但是这个分布也能够帮助构建z和x的关系,并且能够根据平移和压缩的变换操作将标准正态分布中采样的样本转换为p(z|x)分布下的样本,这样的话就不要求p(z|x)是标准正态分布了,这样理解对吗?
3、关于z包含噪声我还是不太理解,这个“噪声”具体指的是什么含义呢?您举得例子我的理解是能够说明z和x的关系不密切,但是我还是不太理解这个“噪声”的含义
4、关于BN和LN的问题,可以理解说BN是利用到了不同样本的特征向量的信息,而LN只用到了某个样本的信息,所以LN不能保证对不同样本提供区分度
我的问题可能看上去比较简单而且有点钻牛角尖,但是确实是让我困扰挺久但也得不到具体答案的问题,希望您能解答~
1、我不知道你所谓符号不统一究竟想表达什么,$p$、$q$是两个不同的分布,用两个不同的记号不是显然成立的事情,什么叫做“应该符号统一”?
2、是的;
3、噪声就是我们平时理解的噪声,没什么隐藏的含义,$z=\mu+\sigma\varepsilon$,只要$\sigma\neq 0$,$\varepsilon$不就是明显的噪声?
4、是的。
您好,我猜测您的疑惑应该是在于有些讲解把$p(z \mid x)$和$q(z \mid x)$分别定义为真实后验和近似后验(注意都是后验分布),而在这里的是$p(z \mid x)$和$q(x \mid z)$。
您好,请问这里p(z∣x)和q(x∣z)不是真是后验和近似后验吗?
忘记传统变分推断的各种概念,那是无穷无尽的泥沼。
理解VAE的最简单方法是 https://kexue.fm/archives/5343 ,这个系列也一直按照这个思路来理解。$p(z|x)$是一个条件分布,它没有其他名字,它跟数据分布$\tilde{p}(x)$组合构成一个联合分布$\tilde{p}(x)p(z|x)$;$q(x|z)$是另一个条件分布,也没有名字,它跟标准正态分布$q(z)$一起构成一个联合分布$q(x|z)q(z)$。VAE就是最小化这两个联合分布的KL散度$KL(\tilde{p}(x)p(z|x)\Vert q(x|z)q(z))$。
March 16th, 2023
苏老师,我是这么理解的:原$E[\mu(x)]\to 0$使得$q(z)\to N(0,1)$,而$E[\sigma^2(x)]$是可学习的,KL消失是因为学习过程中$E[\sigma^2(x)]\to 0$,因此(4)式中在$\mu(x)$加上BN让$E[\mu(x)] + E[\sigma^2(x)] \geq \frac{d}{2}(\beta^2+\gamma^2)$,$E[\mu(x)]=\beta_{\mu} \to 0$仍是需要的,因此限制$\gamma^2 > 0$就好了,为啥(10)式中要$\gamma_{\mu} > 0$呢?
原因后面的章节我也解释了啊,我觉得只在$\mu(x)$加BN、不在$\sigma(x)$加BN对我来说挺难受,所以我想两者都加入BN,那么约束条件就变成了$\eqref{eq:gamma2}$,而$\eqref{eq:gamma2}$中的$\gamma_{\mu}$就相当于$\eqref{eq:kl-lb}$的$\gamma$。
好的苏老师,我再琢磨琢磨,十分感谢回复。
June 24th, 2023
苏神, 我对这篇文章有点不太理解. 按照原论文的思路, 我们对 $\mu(x)$ 应用 BN 后, 我们确实保证了 KL Loss 不为 0. 但我认为这只是因为我们强行把 $\mu(x)$ 变为了 0.5, 自然转化后的分布不再是正态分布了, KL Loss 自然不为 0. 但这真的解决的 KL Diverge 的核心问题吗, Decoder 仍然可能不利用 Encoder 的信息, 它很可能只是从随机从正态分布采样变成了随机从 $\mu(x)=0.5, \sigma(x)=1$ 中采样了.
没有强行设置$\mu(x)$吧?设置的是方差。
你的担忧也没错,这样只是拉开了encoder的特征的差距,没有保证decoder一定会利用encoder的信息,但即便是常规的自编码器也会有这个担忧,只能说梯度下降会尽量利用到能利用的信息,拉开特征差距后,梯度下降利用起来更容易了,所以有利于缓解。
我仔细想了想, 我们并没有强制设定 $\mu(x)$. 根据原文的逻辑, 对一个模型预测的 $\mu(x)$ 进行归一化, 可以将 $norm(\mu(x))$ 控制在 -1 到 1 之间, 同时其均值为 0. 接着, 我们使用 $\gamma$ 来调整方差, 然后通过 $\beta$(可学习)来调整均值. 如此一来, 转换后的分布的 $\mu(x)$ 仍然可以等于 0.
不过 KL Loss 不等于 0 不代表模型在有效利用信息的可能性依然存在. 但是, 如您所说, BN-VAE 之所以有效可能更多地是因为它扩大了特征差距, 而不仅仅是保证了 KL Loss 不等于 0 (尽管这也间接地反映了特征间的差距).
再次感谢苏神解答.
July 18th, 2023
您好,我用pytorch实现了您的方案,目前的问题是虽然reconstruction loss很小(约0.06),kl loss很稳定,但是kl loss保持在一个较高的值(约3.6)不下降,所以整体的elbo比较大。如果不加入变分的部分,loss大概在0.8。方便帮忙判断下可能是什么问题吗?
BN的目的就是保持在一个较大的值不要下降,所以单看你这个现象并没有分析。你可以具体分析一下kl loss=3.6是否合理,或者直接看最终的结果是否合理。
January 28th, 2024
苏神你好!如果我的显卡只能允许我跑batchsize=1,是否能够通过梯度累积若干个batch的方法等价使用BN层啊?还是必须要改网络结构了呀?
bn的梯度累积好像有专门的技巧的,或者你可以参考:https://kexue.fm/archives/8471
June 26th, 2024
苏神好,发现一处可能的笔误,“BN的巧与秒”是不是应该是“BN的巧与妙”
另外我用了本文的方法做了个小玩具,确实挺好用:https://zhuanlan.zhihu.com/p/637430709
已经修正,谢谢指出。
August 6th, 2024
您好,我正在学习 posterior collapse 问题,刚刚拜读了您的文章,以及原论文。我感觉 "A Batch Normalized Inference Network Keeps the KL Vanishing Away" (Zhu et al., 2020) 相当于对 "Preventing posterior collapse with delta-VAEs" (Razavi et al., 2019) 中对 KL 散度下界的约束做了 relaxation*,从而有了改进,但本质属于同一系的方法。Razavi et al. (2019) 讨论了如何通过引入 auxiliary prior 应对 posterior hole 问题。我想请问 1) 您对本文以及 Zhu et al. (2020) 就如何应对 posterior hole 问题有何见解?2) (可能有点离题了~~)"Variational Lossy Autoencoder" (Chen et al., 2017) 从 information-theoretic 角度讨论了 posterior collapse 的可能原因,您觉得 Chen et al. (2017) 的观点和 free-bits、delta-VAE、BN-VAE 这系方法有什么联系?总感觉通过给 KL 散度设置下界的方法似乎与最初 Kingma & Welling (2013) 想解决的问题相悖。
非常感谢!
*: Razavi et al. (2019) (如果我理解正确的话)约束变分后验 family 从而使每个数据点对应的 KL 散度都大于零,而 Zhu et al. (2020) 仅要求 KL 散度关于数据集的期望大于零,由于 posterior collapse 只有在整个数据集的变分后验都 collapse 到先验才是有害的,所以 Zhu et al. (2020) 对变分后验 family 的约束同样有效。
1、你说的“本文”和“Zhu et al. (2020) ”,不是同一篇文章吗?
2、我对 posterior collapse 并没有深入的研究,你提到的free-bits、delta-VAE我此前也并不了解,所以很难有什么有价值的见解;
3、不过你提到的“通过给 KL 散度设置下界的方法似乎与最初 Kingma & Welling (2013) 想解决的问题相悖”,我确实有类似的感觉,我觉得并不是所有跟KL设置下界的方法都是合理的,而是必须结合“我们希望全体latent的分布是标准正态分布”这一点来设置,所以我看到BN-VAE就感觉它走在了正确的方向上。
非常感谢您的回复!我以为填写邮箱后您的回复会发我邮箱里去,一直在等邮件。。
"本文" 指的是这篇博客文章。"Zhu et al. (2020)" 指的是那篇 arXiv 论文。
因为通过限制变分后验 $q$ 从而保证非零 KL 散度的方法往往会导致 posterior hole 问题(例如 delta-VAE),就有点想当然地觉得 BN-VAE 也是一样的。由于您对 BN-VAE 的认可,我今天才又重新思考 BN-VAE 的作用原理(不知道为什么之后好像就没人讨论为什么 BN-VAE 能成了,甚至 IJCAI "Regularizing Variational Autoencoder with Diversity and Uncertainty Awareness" (Shen et al., 2021) 还评论称 BN-VAE 缺乏理论基础。由于 KL = marginal KL + mutual information ("ELBO surgery: yet another way to carve up the variational evidence lower bound", Hoffman & Johnson, 2016),只要满足 marginal KL 逼近 0 同时 mutual information > 0 即可同时解决 posterior hole 和 posterior collapse,然而 marginal KL 和 mutual information 都是 intractable 的。我正在想或许 BN-VAE 一定程度上提高了 mutual information (的下界)才避免了 posterior collapse?您对此有什么看法吗?
我写了一篇关于 BN-VAE 如何选择 $\gamma$ 的博客,证明了(希望没证错~)$\gamma>1$ 虽然解决了 posterior collapse,但会导致 posterior hole。还没写完的部分是关于上面 mutual information 的。在这里:https://kkew3.github.io/2024/08/09/gamma-in-bn-vae.html。您可否有时间时帮我看下(抱歉可能有点偏题了)。我感觉 Zhu et al. 可能也觉得 $\gamma$ 不应大于 1,因为尽管没有说明,但是原论文里展示了其值为 0.3 和 1.0 的实验结果,却偏偏没有大于 1 的实验结果。
邮箱通知这个确实比较遗憾,由于个人云服务搞邮箱服务比较麻烦,一直没跑通。
我去搜了一下posterior hole的定义,按道理对于BN-VAE,只要$\gamma\neq 1$,那么posterior hole就肯定存在吧。至于选择$\gamma < 1$,有点类似于退火,以获得更好的随机生成质量吧(可能会牺牲多样性)。
我对VAE的主流理论并不了解,你说的很多名词我此前都不认识,所以可能还需要你多指点一下。
October 6th, 2024
苏神太牛啦!模型终于能正常收敛了!!!
September 3rd, 2025
感谢苏神,最近在学习VAE,很有收获!