






16
Mar
现在可以用Keras玩中文GPT2了(GPT2_ML)
By 苏剑林 | 2020-03-16 | 126356位读者 |前段时间留意到有大牛开源了一个中文的GPT2模型,是最大的15亿参数规模的,看作者给的demo,生成效果还是蛮惊艳的,就想着加载到自己的bert4keras来玩玩。不过早期的bert4keras整体架构写得比较“死”,集成多个不同的模型很不方便。前两周终于看不下去了,把bert4keras的整体结构重写了一遍,现在的bert4keras总能算比较灵活地编写各种Transformer结构的模型了,比如GPT2、T5等都已经集成在里边了。
GPT2科普 #
GPT,相信很多读者都听说过它了,简单来说,它就是一个基于Transformer结构的语言模型,源自论文《GPT:Improving Language Understanding by Generative Pre-Training》,但它又不是为了做语言模型而生,它是通过语言模型来预训练自身,然后在下游任务微调,提高下游任务的表现。它是“Transformer + 预训练 + 微调”这种模式的先驱者,相对而言,BERT都算是它的“后辈”,而GPT2,则是GPT的升级版——模型更大,训练数据更多——模型最大版的参数量达到了15亿。
中文版 #
看过GPT2的科普推文的读者,多数都会被它的生成效果所惊艳。不过再好也是别人家的语言,OpenAI并没有帮忙训练中文版。不过好消息是,一个叫GPT2_ML的项目开源了一个中文版的GPT2,而且还是最大的15亿参数级别的模型。
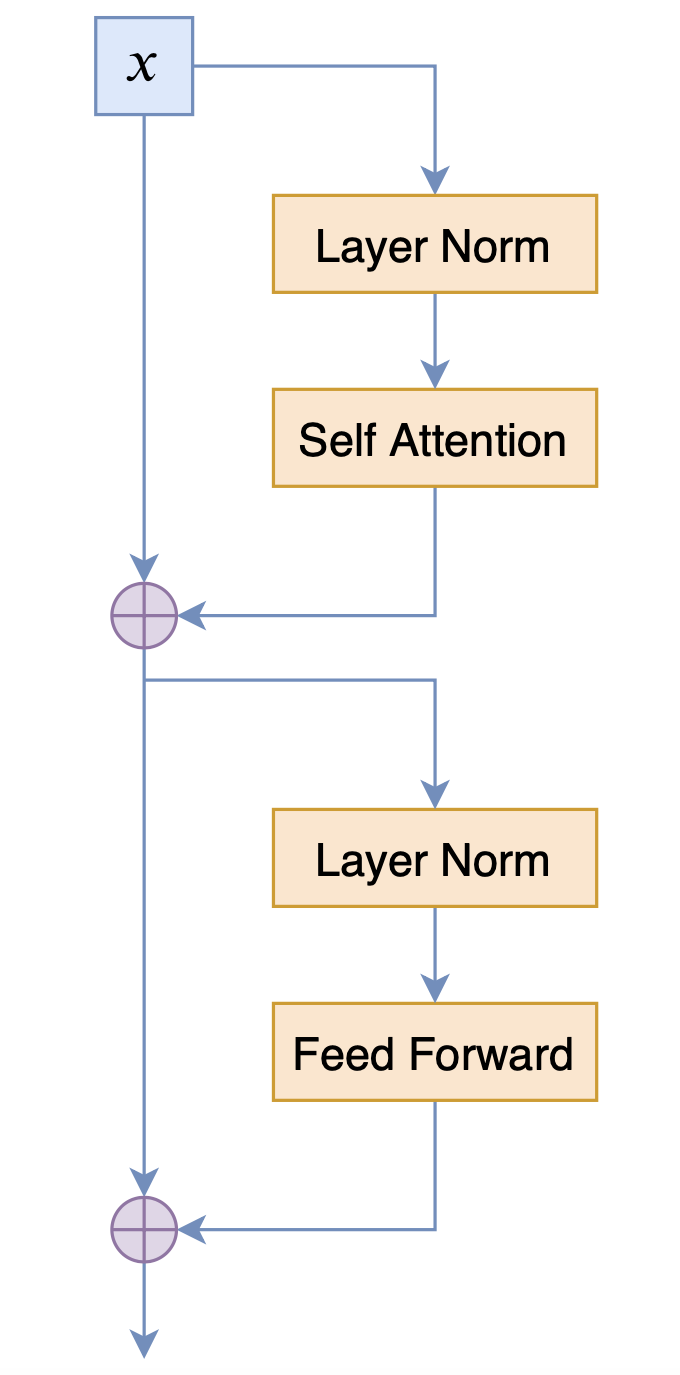
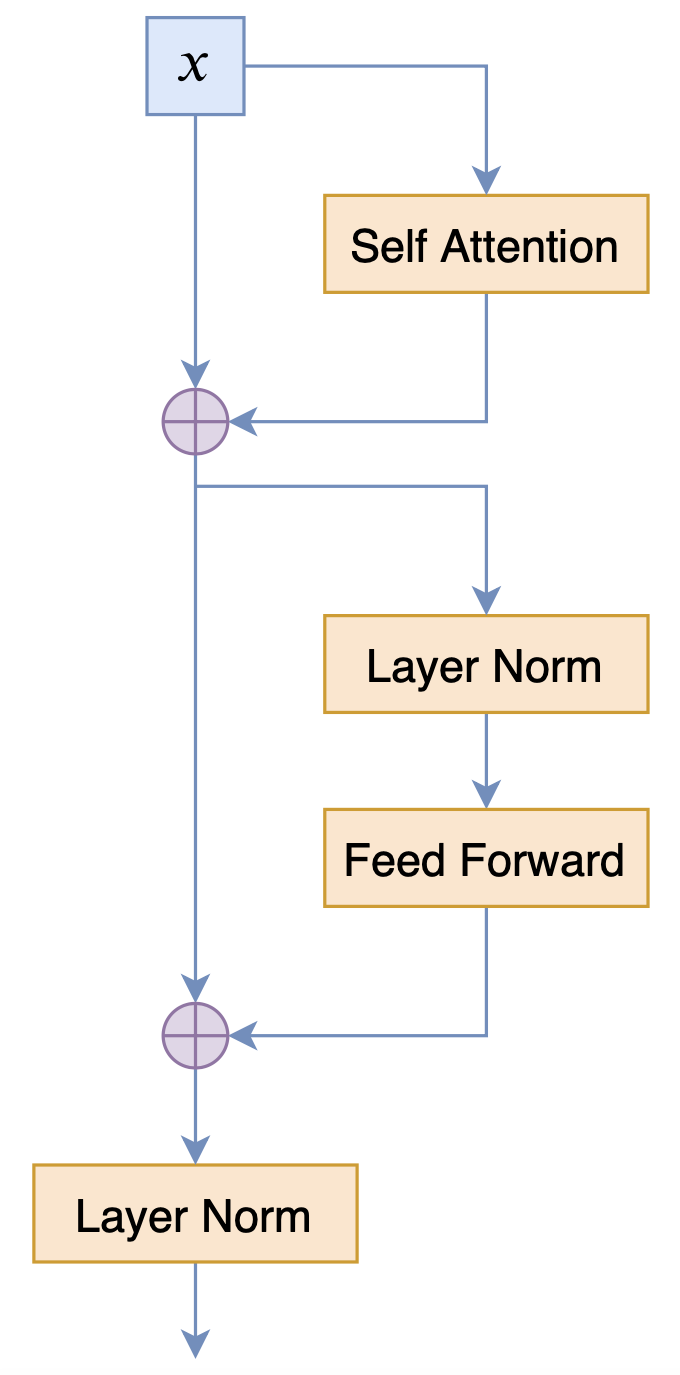
目前bert4keras集成的GPT2,正是GPT2_ML项目给出的,而不是OpenAI的那个,毕竟bert4keras优先服务中文版。值得指出的是,GPT2_ML的模型结构,跟OpenAI版的GPT2结构并不一样,也跟BERT的结构有所不同,三者的Block对比如下:
官方GPT2的Block示意图
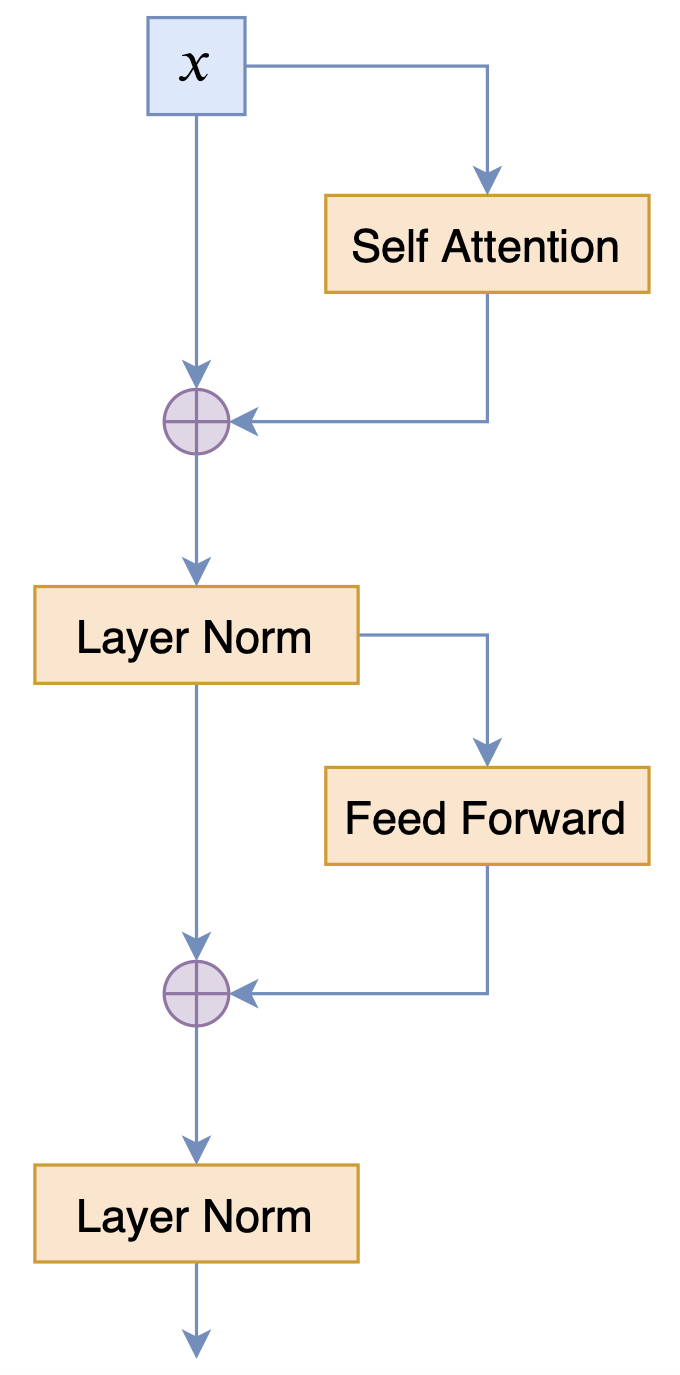
BERT的Block示意图
GPT2_ML的Block示意图
测试一下 #
首先,下载模型权重,地址为:
链接: https://pan.baidu.com/s/1OXBd16o82SpIzu57kwA8Mg 提取码: q79r
其中,主文件“model.ckpt-100000.data-00000-of-00001”还可以从Google Drive下载。下载完成后请检查一下model.ckpt-100000.data-00000-of-00001的SHA256(4a6e5124df8db7ac2bdd902e6191b807a6983a7f5d09fb10ce011f9a073b183e)。
然后安装不低于0.6.0版本的bert4keras(当前最新版),就可以跑下述测试代码了(如果因为版本迭代原因导致下述代码已经过期,那么请到 basic_language_model_gpt2_ml.py 查看最新版本):
#! -*- coding: utf-8 -*-
# 基本测试:中文GPT2模型
# 介绍链接:https://kexue.fm/archives/7292
import numpy as np
from bert4keras.models import build_transformer_model
from bert4keras.tokenizers import Tokenizer
from bert4keras.snippets import AutoRegressiveDecoder
from bert4keras.snippets import uniout
config_path = '/root/gpt2/config.json'
checkpoint_path = '/root/gpt2/model.ckpt-100000'
dict_path = '/root/gpt2/vocab.txt'
tokenizer = Tokenizer(dict_path,
token_start=None,
token_end=None,
do_lower_case=True) # 建立分词器
model = build_transformer_model(config_path=config_path,
checkpoint_path=checkpoint_path,
model='gpt2_ml') # 建立模型,加载权重
class ArticleCompletion(AutoRegressiveDecoder):
"""基于随机采样的文章续写
"""
@AutoRegressiveDecoder.set_rtype('probas')
def predict(self, inputs, output_ids, step):
token_ids = np.concatenate([inputs[0], output_ids], 1)
return model.predict(token_ids)[:, -1]
def generate(self, text, n=1, topk=5):
token_ids, _ = tokenizer.encode(text)
results = self.random_sample([token_ids], n, topk) # 基于随机采样
return [text + tokenizer.decode(ids) for ids in results]
article_completion = ArticleCompletion(start_id=None,
end_id=511, # 511是中文句号
maxlen=256,
minlen=128)
print(article_completion.generate(u'今天天气不错'))
部分结果:
>>> article_completion.generate(u'今天天气不错')
[u'今天天气不错,可以去跑步。昨晚看了一个关于跑步的纪录片,里面的女主讲述的是一个女孩子的成长,很励志,也很美丽。我也想跑,但是我不知道跑步要穿运动鞋,所以就买了一双运动鞋。这个纪录片是关于运动鞋的,有一 集讲了一个女孩子,从小学开始就没有穿过运动鞋,到了高中才开始尝试跑步。']>>> article_completion.generate(u'双十一')
[u'双十一马上就要到了!你还在为双11的物流配送而担心吗?你还在为没时间去仓库取货而发愁吗?你还在为不知道怎么买到便宜货而发愁吗?你还在为买不到心仪的产品而懊恼吗?那么,双十一就来了!今天小编带你来看看这些 快递,都是怎么送货的!1. 物流配送快递公司的配送,主要是由快递公司负责,快递公司负责派件,物流服务。']>>> article_completion.generate(u'科学空间')
[u'科学空间站科学空间站(英文:science space station),是中华人民共和国的一个空间站。该空间站是中国科学院大连物理研究所研制,主要研发和使用中国科学院大连物理研究所的核能动力空间站。科学空间站位于北京市海淀区,距离地面393米,总建筑面积约为1万平方米,总投资约为5亿元人民币。科学空间站于2018年12月26日开始动工,2021年6月建成并投入使用。']
是不是感觉还挺好的?
想Finetune? #
看到这效果,估计不少读者的想法就是:怎么用到我自己的模型上,能不能在我自己的任务上finetune一下?
不好意思,告诉大家一个比较悲观的结果:笔者用Adam优化器在公司的22G显存的TITAN RTX上测试finetune这个参数规模接近15亿的GPT2,发现batch_size=1都没法跑起来...最后发现,只有在AdaFactor优化器下,才能Finetune得动它。
关于AdaFactor,后面有机会再写文章讨论。
转载到请包括本文地址:https://kexue.fm/archives/7292
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Mar. 16, 2020). 《现在可以用Keras玩中文GPT2了(GPT2_ML) 》[Blog post]. Retrieved from https://kexue.fm/archives/7292
@online{kexuefm-7292,
title={现在可以用Keras玩中文GPT2了(GPT2_ML)},
author={苏剑林},
year={2020},
month={Mar},
url={\url{https://kexue.fm/archives/7292}},
}

September 7th, 2020
大佬你好,能不能介绍一下怎么finetune?
稍微学点keras就知道怎么finetune了。finetune这个gpt2的核心难度不是在于技术,而是在于硬件,文章已经谈及了一下了。
March 6th, 2021
苏老师您好,学习了,非常感谢。请问一下,如果我希望能从您这个函数,改成一个可以实时调用的http服务,应该如何实现呢?比如基于Flask,谢谢啊!
bert4keras自带了个简单的web sever的demo,可以参考:https://github.com/bojone/bert4keras/blob/master/examples/basic_simple_web_serving_simbert.py
如果你需要其他的,请自行学习和实现,我也没法教你...