






3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 348936位读者 |在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
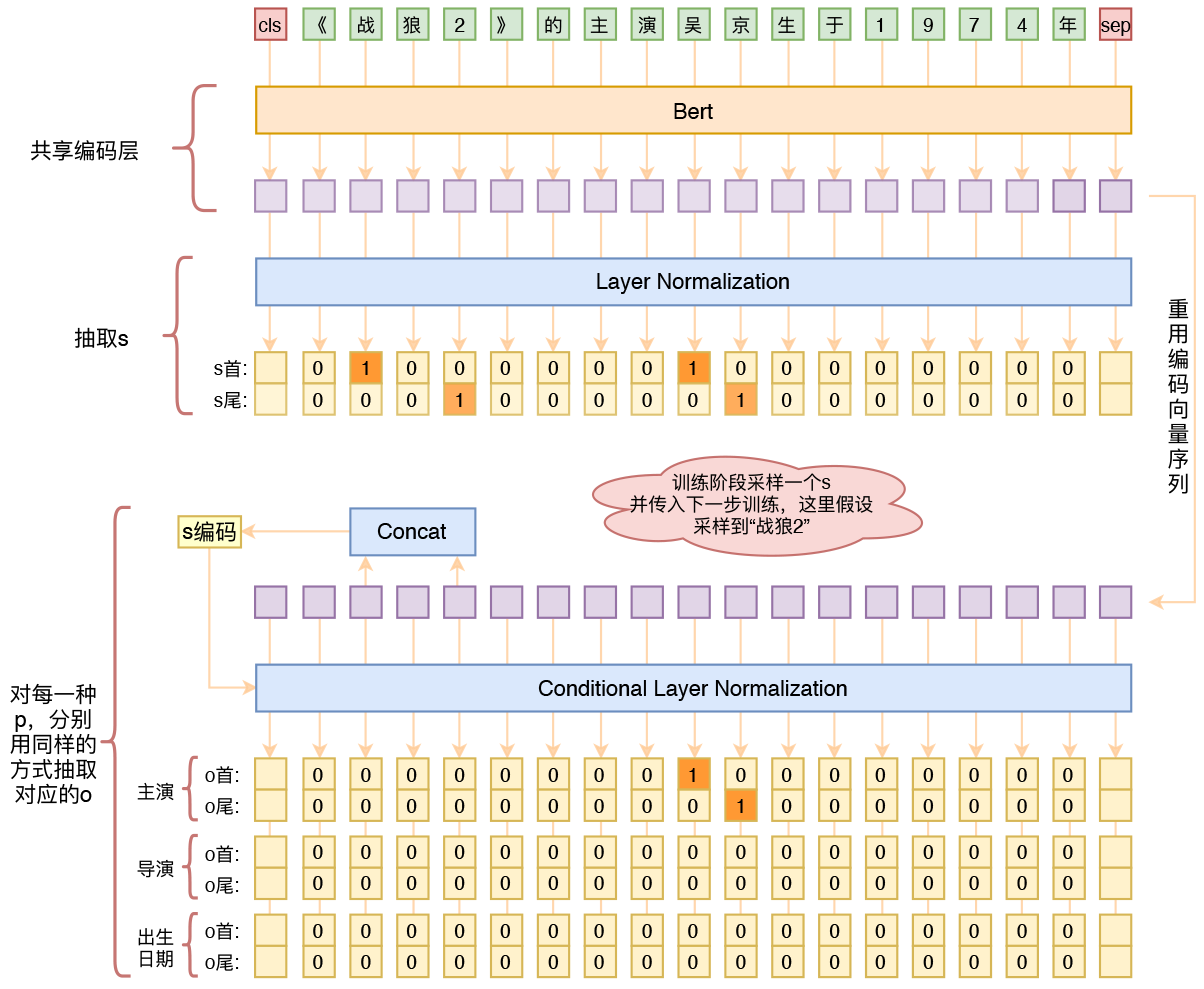
基于Bert的三元组抽取模型结构示意图
模型简介 #
关于数据格式和模型的基本思路,在《基于DGCNN和概率图的轻量级信息抽取模型》一文中已经详细介绍过了,在此不再重复。数据集百度已经公开了,在这里就可以下载。
跟之前的策略一样,模型依然是基于“半指针-半标注”的方式来做抽取,顺序是先抽取s,然后传入s来抽取o、p,不同的只是将模型的整体架构换成了bert:
1、原始序列转id后,传入bert的编码器,得到编码序列;
2、编码序列接两个二分类器,预测s;
3、根据传入的s,从编码序列中抽取出s的首和尾对应的编码向量;
4、以s的编码向量作为条件,对编码序列做一次条件Layer Norm;
5、条件Layer Norm后的序列来预测该s对应的o、p。
类别失衡 #
不难想到,用“半指针-半标注”结构做实体抽取时,会面临类别不均衡的问题,因为通常来说目标实体词比非目标词要少得多,所以标签1会比标签0少得多。常规的处理不平衡的方法都可以用,比如focal loss或者人工调节类权重,但这些方法用了之后,阈值就不大好取了。我这里用了一种自以为比较恰当的方法:将概率值做$n$次方。
具体来说,原来输出一个概率值$p$,代表类别1的概率是$p$,我现在将它变为$p^n$,也就是认为类别1的概率是$p^n$,除此之外不变,loss还是用正常的二分类交叉熵loss。由于原来就有$0\leq p \leq 1$,所以$p^n$整体会更接近于0,因此初始状态就符合目标分布了,所以最终能加速收敛。
从loss角度也可以比较两者的差异,假设标签为$t\in\{0, 1\}$,那么原来的loss是:
\begin{equation}- t \log p - (1 - t) \log (1 - p)\end{equation}
而$n$次方之后的loss就变成了
\begin{equation}- t \log p^n - (1 - t) \log (1 - p^n)\end{equation}
注意到$- t \log p^n = -nt \log p$,所以当标签为1时,相当于放大了loss的权重,而标签为0时,$(1 - p^n)$更接近于1,所以对应的loss $\log(1 - p^n)$更小(梯度也更小)。因此,这算是一种自适应调节loss权重(梯度权重)的思路了。
相比于focal loss或人工调节类权重,这种方法的好处是不改变原来内积($p$通常是内积加sigmoid得到的)的分布就能使得分布更加贴近目标,而不改变内积分布通常来说对优化更加友好。
源码效果 #
Github:task_relation_extraction.py
在没有任何前处理和后处理的情况下,最终在验证集上的f1为0.822,基本上比之前的DGCNN模型都要好。注意这是没有任何前后处理的,如果加上一些前后处理,估计可以f1达到0.83。
同时,我们可以发现训练集和验证集的标注有不少错漏之处,而当初我们做比赛的时候,线上测试集的标注质量比训练集和验证集都要高(更规范、更完整),所以当时提交测试的f1基本上要比线下验证集的f1高4%~5%,也就是说,加上一些规则修正后,这个结果如果提交到当时的排行榜上,单模型估计有0.87的f1。
值得注意 #
开头已经提到了,之前用keras-bert就写过一个用bert来抽三元组的例子了,而这里主要谈谈本文模型跟之前的例子不同之处以及一些值得注意的地方。
第一个不同之处是,当时仅仅是简单的尝试,所以仅仅是将s的向量加到编码序列中,然后做o、p的预测,而不是像本文一样用到条件Layer Norm;条件Layer Norm的方案有更好的表达能力,效果略微有提升。
第二个不同之处,也是值得留意的地方,就是本文的模型用的是标准的bert的tokenizer,而之前的例子是直接按字切分。标准的tokenizer出来的序列,并不是简单地按字切分的,尤其是函数英文和数字的情况下,输出的分词结果跟原始序列的字并非对齐的,所以在构建训练样本和输出结果时,都要格外留意这一点。
读者可能会疑问:那为什么不用回原来的按字切分的方式呢?笔者觉得,既然用了bert,应该按照bert的tokenizer,就算不对齐其实也有办法处理好的;而之前的按字切分,只是笔者当时还不够熟悉bert所导致的不规范用法,是不值得提倡的;遵循bert的tokenizer,还有可能比自己强行按字切分获得更好的finetune效果。
此外,笔者还发现一个有点意外的事实,就是中文bert所带的字表(vocab.txt)是不全的,比如“符箓”的“箓”字就不在bert的vocab.txt里边,所以要输出最终结果的时候,最好别用tokenizer自带的decode方法,而是直接对应到原始序列,在原始序列中切片输出。
最后,这一版模型的训练还加入了权重滑动平均,它可以稳定模型的训练,甚至能轻微提升模型的效果。关于权重滑动平均的相关介绍,可以参考这里。
文章小结 #
本文给出了用bert4keras来做三元组抽取的一个例子,并且指出了一些值得注意的事情,欢迎大家参考试用。
转载到请包括本文地址:https://kexue.fm/archives/7161
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jan. 03, 2020). 《用bert4keras做三元组抽取 》[Blog post]. Retrieved from https://kexue.fm/archives/7161
@online{kexuefm-7161,
title={用bert4keras做三元组抽取},
author={苏剑林},
year={2020},
month={Jan},
url={\url{https://kexue.fm/archives/7161}},
}

April 14th, 2020
苏神,我的batch_subject_labels = sequence_padding(batch_subject_labels)报维度对不齐~
请问一下您那边会把这个错误吗?
不会。提示:github上的examples只保证适配github上的最新bert4keras。
感谢苏神回复^-^
我的python是3.5的,拉取的是您的稳定版本。
我刚刚自己修改了一下~
由于
batch_subject_labels是batchsize*len(token_ids)*2,故设padding=[0,0]
batch_object_labels是batchsize*len(token_ids)*len(predicate2id)*2
,故设padding=[[0,0]] * len(predicate2id)。
另外,
在预测是的extract_spoes中
subject_preds = subject_model.predict([token_ids, segment_ids]),
token_ids和segment_ids转化成了数组以满足_standardize_input_data的list[array]的结构。
苏神,我的数据量目前是6784,batchsize=32
在训练时,一直是
f1: 0.00000, precision: 1.00000, recall: 0.00000
想请教一下您原因
不知道。
你可以自定打印一下预测序列,看看数值情况;可以考虑先去掉ema,ema可能导致前期收敛变慢。
好的。
非常感谢
苏神,ema+adam、adam跑了5个epoch网络loss在4.3,lookahead+adam第一个epoch网络损失降到了0.7,想请教下原因,被损失情况弄得有些摸不着头脑(sample提供的数据)
那就是说明你的情况下各个优化器的表现不一样咯。
十分感谢苏神的解答。个人在复现三元组指针抽取和文本摘要的时候发现,最终的损失和您标注的sota还有几个百分点的距离。可能是一些优化t上的trick不当,比如warm-up的设置,同时也发现,lookhead+radam有时候比adam表现得更差一些。优化这部分工作确实是比较神奇而有些玄学的。
您好,我跑5个epoch用了30多个小时,请问下模型是不是都是这么长时间训练的,
AdamEMA = extend_with_lookahead_v2(Adam, name='Adam')
optimizer = AdamEMA()
train_model.compile(optimizer=optimizer)
按照lookahead+adam
我不大清楚你的实验环境,我记得我这里5个epoch可能需要3小时左右。
和我的结果类似,我感觉是否文本过长造成的标签倾斜严重有关?现在手边没有gpu,没法测试。不知道调高概率的n次方是否可行。
April 14th, 2020
苏神,你好。想问下在task_relation_extraction.py中对s的采样体现在哪里?是extrac_subject中return subject[:,0]中的0吗?
@王晶|comment-13183
sorry,看错了。是在data_generator中采样的吧?
是的
April 22nd, 2020
楼主读了你的代码,有几个问题希望您能解惑一下
1.在随机选取主体id时,选择的主体起点start和终点end,都是随机选取的,虽然end是在大于start的范围选择,但是仍导致生成的(start,end)与spoes字典中的对应不上,这样主体subject_ids和客体object_labels都可能为空,这样做是为了加入噪声吗?
2.这种抽取三元组的模型在属性抽取里是不是也很适用?
1. 参考这里 https://kexue.fm/archives/6671/comment-page-1#comment-11303
2. 不清楚,没经验。
感谢苏神回复!还有个小问题哈
关于在Totalloss层计算loss时的mask,因为mask输入在代码里没有体现,我参考了链接里的评论,我理解是mask是标注的真实句子,这样在计算loss会忽略padding带来的影响,不知道这样理解对不对?
是的。
May 9th, 2020
苏神你好,很荣幸看了你在csdn发的博客,那篇的ema是封装一个类,对model进行参数注册和更新,而目前的代码是封装在optimizer中。
这样验证阶段是:
1.在每个on_epoch_end后调用optimizer.apply_ema_weights()
2.预测
3.optimizer.reset_old_weights()恢复参数
4.下一个epoch
这是我理解的执行和调用,还请苏神指正一下~
刚刚看到验证代码了,感谢苏神~
请问验证代码在哪里呀
June 18th, 2020
请问本篇讲述的进行改进后的模型的整个源代码在哪里找呢?
什么改进后的模型?
July 7th, 2020
对于extend_with_exponential_moving_average函数的代码有点疑问。
在第4行中,self.ema_weights被置零,则第9行的w1永远是0。感觉第4行应该放到def __init__()中。
这是静态图写法,没有问题的~
刚看到你更新的v2版本,谢谢
July 30th, 2020
您好,学习过程中看到了您的结构设计,最近也在思考这个问题,之前一直认为把关系与实体识别统一在BIO标注框架下,当做序列标注任务,即《Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme》,应该是一个很优雅的思路,但是致命的是无法解决嵌套、多重同类关系。您的设计很优雅,从中学到很多,谢谢!有个问题:
1. 在做S抽取的过程中,没有区分S具体的类别。对于最终结果而言,P确定的情况下,S与O的类型随之确定,对于最终结果似乎没有帮助。但是,从模型角度,S的类别信息可能对后续P、O分类起作用,比如Stype为影视作品,对应的P只可能是票房、上映时间,不可能是丈夫等。那么预测S类别的话,任务难度提升,但是可能对后续P分类有作用;不预测S类别的话,任务难度下降,但后续预测可能存在信息损失。
想知道您怎么看?
如果测试阶段也提供了Stype的话,那么可以想办法利用起来,但是如果没有提供Stype而是要靠预测的话,那就没有必要了,因为你这相当于先预测Stype,然后根据Stype预测P,分了两步走,理论上存在传递误差,不如直接一步到位预测P好。
September 17th, 2020
苏神晚上好,今日我有幸尝试运行了您的bert4keras应用在三元组抽取的例子,加载的网络参数是您github上给出的第一个谷歌的连接。其他的代码均未修改,当然路径就不提了,数据也是您测试的百度2019的数据。但在我的尝试过程中,直到跑到最后一个epoch,f1的值仍然停留在52%左右,与您当时测试的结果差距较大。我拜读了您的代码之后只感觉受益匪浅但不能发现我测试时效果差的原因。还请苏神赐教,稍微点拨一下可能出现问题的地方,万分期待您的回复
苏神您好,再次打扰,我又在自己的数据集上进行了测试,标注的方法完全一致,但训练的结果f1值几乎为0,查看生成的结果也是几乎所有的句子都没有预测出三元组(无论正误都没预测出来),请问像这种情况按您的经验我应该从哪里开始调整呢?期待您的回复
在自己的数据集上测试效果不好的原因就是数据集较小,训练的轮次不够
开源了这么多代码,就这个代码问题最多了...
你试试优化器去掉EMA?如果还不行的话,试试手动设置个随机种子?再不行的话,换个tf版本?我发现这代码好像随机性比较大,有些人随便就复现了,有些人死活复现不了。。。
苏神上午好,很感谢您的解答。暂时已经得到和您实验中接近的结果了。人生苦短,我声援苏神!!
做了什么改动?跟大家分享一下,确认一下障碍点在哪...
November 5th, 2020
苏大佬您好,我这边一直报keyerror错误,我运行了几遍发现这些文字都是随机出现的(在all_50_schemas里的三元组)的
File "D:/myprojects/NER_RE/task_relation_extraction.py", line 86, in __iter__
p = predicate2id[p]
KeyError: '出生地'
Epoch 1/20
Process finished with exit code 1
不清楚。运行出错就应该直接去debug,该出错的你再多运行几遍还是会出错,不需要运行几遍来确认了哈~
这是读取数据解码格式的问题;我也出现了。你把all_50_schemas 文件属性加上尾缀.txt,然后把打开数据的with open ('数据路径'),改成with open ('数据路径','r',encoding='UTF-8-sig') 就可以
感谢帮助读者答疑。
November 6th, 2020
苏神你好,看了你的文章受益匪浅,关于关系抽取里面有几点疑问望解答:
1. 你的subject_model和object_model的输出为概率的平方,而在extract_spoes里面设置输出要大于0.6/0.5,这样是不是增大了筛选条件,导致precision过高而recall过低;
2. 看你其他的文章学习了学习率设置的重要性,然后对本篇关系提取的学习率设置也进行了思考,bert部分的学习率和其他层次的学习率需不需要分开设置?该如何做?
3. keras4bert里面有没有好的方法,能对不同层次设置不同的学习率呢?
1. 目前看precision的确略大于recall,但不至于“过高”;
2. 我没有尝试过;
3. 这个目前没有,但开发起来不难,我可以考虑加入到下一版bert4keras中