






3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 352932位读者 |在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
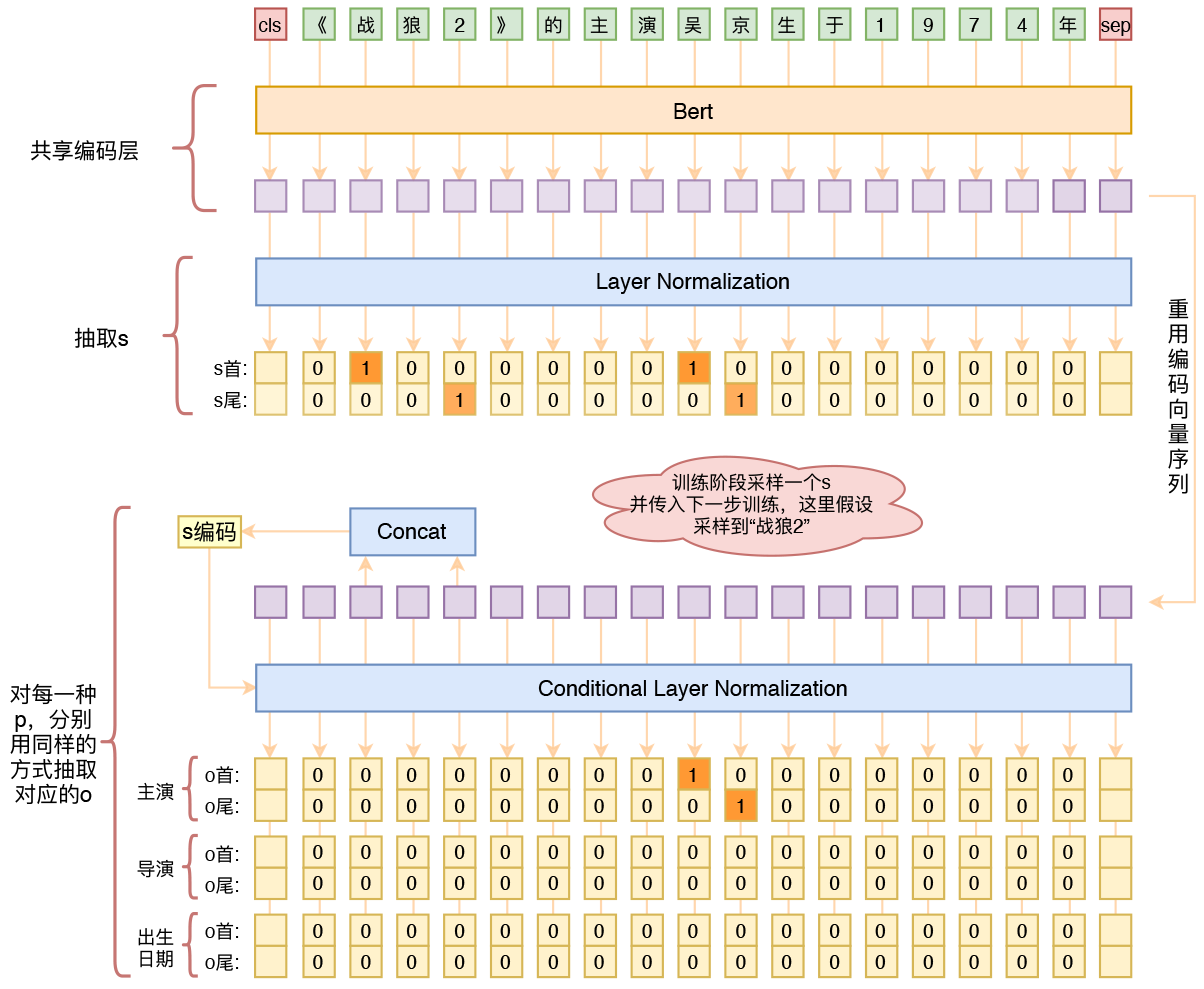
基于Bert的三元组抽取模型结构示意图
模型简介 #
关于数据格式和模型的基本思路,在《基于DGCNN和概率图的轻量级信息抽取模型》一文中已经详细介绍过了,在此不再重复。数据集百度已经公开了,在这里就可以下载。
跟之前的策略一样,模型依然是基于“半指针-半标注”的方式来做抽取,顺序是先抽取s,然后传入s来抽取o、p,不同的只是将模型的整体架构换成了bert:
1、原始序列转id后,传入bert的编码器,得到编码序列;
2、编码序列接两个二分类器,预测s;
3、根据传入的s,从编码序列中抽取出s的首和尾对应的编码向量;
4、以s的编码向量作为条件,对编码序列做一次条件Layer Norm;
5、条件Layer Norm后的序列来预测该s对应的o、p。
类别失衡 #
不难想到,用“半指针-半标注”结构做实体抽取时,会面临类别不均衡的问题,因为通常来说目标实体词比非目标词要少得多,所以标签1会比标签0少得多。常规的处理不平衡的方法都可以用,比如focal loss或者人工调节类权重,但这些方法用了之后,阈值就不大好取了。我这里用了一种自以为比较恰当的方法:将概率值做$n$次方。
具体来说,原来输出一个概率值$p$,代表类别1的概率是$p$,我现在将它变为$p^n$,也就是认为类别1的概率是$p^n$,除此之外不变,loss还是用正常的二分类交叉熵loss。由于原来就有$0\leq p \leq 1$,所以$p^n$整体会更接近于0,因此初始状态就符合目标分布了,所以最终能加速收敛。
从loss角度也可以比较两者的差异,假设标签为$t\in\{0, 1\}$,那么原来的loss是:
\begin{equation}- t \log p - (1 - t) \log (1 - p)\end{equation}
而$n$次方之后的loss就变成了
\begin{equation}- t \log p^n - (1 - t) \log (1 - p^n)\end{equation}
注意到$- t \log p^n = -nt \log p$,所以当标签为1时,相当于放大了loss的权重,而标签为0时,$(1 - p^n)$更接近于1,所以对应的loss $\log(1 - p^n)$更小(梯度也更小)。因此,这算是一种自适应调节loss权重(梯度权重)的思路了。
相比于focal loss或人工调节类权重,这种方法的好处是不改变原来内积($p$通常是内积加sigmoid得到的)的分布就能使得分布更加贴近目标,而不改变内积分布通常来说对优化更加友好。
源码效果 #
Github:task_relation_extraction.py
在没有任何前处理和后处理的情况下,最终在验证集上的f1为0.822,基本上比之前的DGCNN模型都要好。注意这是没有任何前后处理的,如果加上一些前后处理,估计可以f1达到0.83。
同时,我们可以发现训练集和验证集的标注有不少错漏之处,而当初我们做比赛的时候,线上测试集的标注质量比训练集和验证集都要高(更规范、更完整),所以当时提交测试的f1基本上要比线下验证集的f1高4%~5%,也就是说,加上一些规则修正后,这个结果如果提交到当时的排行榜上,单模型估计有0.87的f1。
值得注意 #
开头已经提到了,之前用keras-bert就写过一个用bert来抽三元组的例子了,而这里主要谈谈本文模型跟之前的例子不同之处以及一些值得注意的地方。
第一个不同之处是,当时仅仅是简单的尝试,所以仅仅是将s的向量加到编码序列中,然后做o、p的预测,而不是像本文一样用到条件Layer Norm;条件Layer Norm的方案有更好的表达能力,效果略微有提升。
第二个不同之处,也是值得留意的地方,就是本文的模型用的是标准的bert的tokenizer,而之前的例子是直接按字切分。标准的tokenizer出来的序列,并不是简单地按字切分的,尤其是函数英文和数字的情况下,输出的分词结果跟原始序列的字并非对齐的,所以在构建训练样本和输出结果时,都要格外留意这一点。
读者可能会疑问:那为什么不用回原来的按字切分的方式呢?笔者觉得,既然用了bert,应该按照bert的tokenizer,就算不对齐其实也有办法处理好的;而之前的按字切分,只是笔者当时还不够熟悉bert所导致的不规范用法,是不值得提倡的;遵循bert的tokenizer,还有可能比自己强行按字切分获得更好的finetune效果。
此外,笔者还发现一个有点意外的事实,就是中文bert所带的字表(vocab.txt)是不全的,比如“符箓”的“箓”字就不在bert的vocab.txt里边,所以要输出最终结果的时候,最好别用tokenizer自带的decode方法,而是直接对应到原始序列,在原始序列中切片输出。
最后,这一版模型的训练还加入了权重滑动平均,它可以稳定模型的训练,甚至能轻微提升模型的效果。关于权重滑动平均的相关介绍,可以参考这里。
文章小结 #
本文给出了用bert4keras来做三元组抽取的一个例子,并且指出了一些值得注意的事情,欢迎大家参考试用。
转载到请包括本文地址:https://kexue.fm/archives/7161
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jan. 03, 2020). 《用bert4keras做三元组抽取 》[Blog post]. Retrieved from https://kexue.fm/archives/7161
@online{kexuefm-7161,
title={用bert4keras做三元组抽取},
author={苏剑林},
year={2020},
month={Jan},
url={\url{https://kexue.fm/archives/7161}},
}

January 15th, 2020
剑林,你好!关于类别不均衡,概率值取n次方的问题,如何确定n的取值呢?
最耐得住考验的方法当然是实验决定。下面提供一种参考的计算,但我没实际验证过~
我们可以假设初始状态为$p=\frac{1}{2}$,以此为标准确定$n$。
当$n=1$时,$\text{正}:\text{负}=\left(-\log \frac{1}{2}\right):\left(-\log \left(1-\frac{1}{2}\right)\right)=1:1$,此时适用于正负样本比例为1:1的情况;
当$n=2$时,$\text{正}:\text{负}=\left(-\log \frac{1}{2^2}\right):\left(-\log \left(1-\frac{1}{2^2}\right)\right)\approx 5:1$,此时适用于正负样本比例为1:5的情况;
当$n=3$时,$\text{正}:\text{负}=\left(-\log \frac{1}{2^3}\right):\left(-\log \left(1-\frac{1}{2^3}\right)\right)\approx 16:1$,此时适用于正负样本比例为1:16的情况;
依此类推。
能依据样本的实际正负样本情况确定n的值,不失为一种好的方法。感谢解惑!
February 12th, 2020
苏神,你好!请问你为什么不直接利用S,O来一并预测P呢,还有您代码里面的概率阈值,为什么头实体的阈值设为0.5,尾实体的阈值0.6,具体这两个值是怎么确定的?
1、你说的是先找s,然后利用s找o,再利用s、o来找p?这样不是显然不够直接么?
2、实验测出来的。
我说的是先找出来S和O,在利用这两个一起来找P
那s、o怎么找出来?ner?
这里分析了样本特点:
https://kexue.fm/archives/6671#%E6%A0%B7%E6%9C%AC%E7%89%B9%E7%82%B9
先ner然后关系抽取是不够好的,对于不同的s、p,对应的o可能会有交集。
比如“《ABC》由北京出版社出版”,并且假设关系集合里边有“出版社”、“出版城市”,那么需要抽取出(ABC, 出版社, 北京出版社)和(ABC, 出版城市, 北京)。先ner再抽取关系无法处理这种情况,因为常规的ner只能识别出“北京出版社”或“北京”之一(除非可以做到层次识别的ner)。
March 9th, 2020
你好,我是新手所以问个可能有些傻的问题。
在task_relation_extraction中
train_data = load_data('/root/kg/datasets/train_data.json')
valid_data = load_data('/root/kg/datasets/dev_data.json')
这个数据从哪里得到呀
March 10th, 2020
苏神,请教一下你的句子的maxlength设置为128,是怎么得出来的,是根据那个测试集或者训练集的三元组句子的最大长度还是因为跟bert的config里面的max_position_embedding里面的512推出来的,按照128,256这些数字是演出来的?个人感觉不像batch_size那样大家有公式,句子长度就这个百度抽取大赛,看过几个人的代码,都不一样,有的取120,有的取50,可否告知一下你的trick
拍脑袋的,没比较过。
March 15th, 2020
start = np.where(subject_preds[0, :, 0] > 0.6)[0]
end = np.where(subject_preds[0, :, 1] > 0.5)[0]
你好,这两句是不是不要再取[0],否则不是得到一个标量了,应该是保留所有长度上的概率吧
哦,不好意思看错了
March 22nd, 2020
我在用您写的bert做预训练模型时,我发现一个现象,就是我之前用的一个小数据集做测试,后来换成一个测试集大一点的数据集做测试,前后两个数据集大小不太一样,前面的训练集60000多句子,测试集300多,后面的大数据集它是训练集50000多个句子,测试集5000多个,无论怎么调参,大数据似乎记住了之前小数据的学习参数,因为我发现前面的数据集的训练集和后面数据集的测试集有重合的,所以即使我已经删掉了前面的所有训练的生成参数,预测结果包括前面的数据集,后面的数据集依然学到了非常好的前面的数据集的参数,导致测试集效果出奇的高。但是我已经把微调的参数best_weight跟预测结果一并删除了,是不是存在bert缓存的地方,还是说微调的参数跟bert的一起存进去了checkpoint?因为网上说google的bert存在缓存,是不是您写的这部分也有什么缓存,麻烦告知一下
1、你究竟是在做预训练还是做finetune?做预训练的话,哪来的测试集?
2、Google的bert和我这里的bert4keras都没什么缓存,请往自己的操作上找原因。
March 25th, 2020
subject_preds = Lambda(lambda x: x**2)(output)
output = Lambda(lambda x: x**4)(output)
请问下这个2和4是代表什么?是正度样本比例吗?百度数据里面没有空关系,请问这个是如何得到的,谢谢
“直觉+瞎蒙”
March 30th, 2020
你好,有些不懂的想请教一下
为什么这里维度是
object_preds = Reshape((-1, len(predicate2id), 2))(output)
而不是
object_preds = Reshape((-1, maxlen, len(predicate2id), 2))(output)(-1是batch_size吧?)
这样岂不是和先前的维度不一样,在提供的实例中的extract_spoes(text)方法里,对object_pred遍历时是已经是一个一个地抽取所以您的代码才是
start = np.where(object_pred[:, :, 0] > 0.6)
end = np.where(object_pred[:, :, 1] > 0.5)
Keras的Reshape不用传入batch_size维度,默认保持batch_size不变。
April 2nd, 2020
我运行如下代码:
tokenizer = Tokenizer(dict_path, do_lower_case=True)
tokenizer.tokenize('Keras是什么')
得到
['[CLS]', 'k', '##era', '##s', '是', '什', '么', '[SEP]']
这个结果感觉是WordpieceTokenizer而不是BasicTokenizer
想问下怎么获取BasicTokenizer的结果呢?还是我代码哪里调用有误?
哪个BasicTokenizer?就只有bert自带的tokenizer呀~
https://github.com/google-research/bert/blob/master/tokenization.py里面有三个类,WordpieceTokenizer和BasicTokenizer和FullTokenizer。
我看https://blog.csdn.net/u010099080/article/details/102587954这篇博客的内容,感觉得到的结果是WordpieceTokenizer的分词
那你这个需求是不是要想Google提为好?或者直接用Google的BERT源码?我这里只提供最终bert的完整tokenizier,你的需求跟我没关系呀。
那我在制作训练数据的时候,是不是要用tokenizer.tokenize的分词结果来标注我的标签。比如一句话是“Keras是什么”,其中Keras是标签B,“是”,“什”,“么”都是标签O。
那么我的训练数据应该是k-B,era-B,s-B,是-O,什-O,么-O这样的吗?
是的
April 3rd, 2020
您好,在s的抽取步骤中,Bert后面加一个CRF,是否会对提高performance更有帮助呢?我看这篇文章是这么干的(BERT-Based Multi-Head Selection for Joint Entity-Relation Extraction)
是不是因为加CRF的话就不能处理subject实体之间有overlap这种情况呢
其实选择哪个还是看爱好,至于换掉之后有没有提升,这需要实验来回答,我也不确定。
感谢回复,还有个小问题。如果我想评估某个样本被预测的不确定性,如何计算某个特定标签的头向量或者尾向量出现的概率呢?我本来想的是一个句子中每个字的sigmoid输出值相乘,后来想着好像不太对?
“某个特定标签的头向量或者尾向量出现的概率”不就是模型的预测结果吗?