






17
Sep
变分自编码器(四):一步到位的聚类方案
By 苏剑林 | 2018-09-17 | 485234位读者 |由于VAE中既有编码器又有解码器(生成器),同时隐变量分布又被近似编码为标准正态分布,因此VAE既是一个生成模型,又是一个特征提取器。在图像领域中,由于VAE生成的图片偏模糊,因此大家通常更关心VAE作为图像特征提取器的作用。提取特征都是为了下一步的任务准备的,而下一步的任务可能有很多,比如分类、聚类等。本文来关心“聚类”这个任务。
一般来说,用AE或者VAE做聚类都是分步来进行的,即先训练一个普通的VAE,然后得到原始数据的隐变量,接着对隐变量做一个K-Means或GMM之类的。但是这样的思路的整体感显然不够,而且聚类方法的选择也让我们纠结。本文介绍基于VAE的一个“一步到位”的聚类思路,它同时允许我们完成无监督地完成聚类和条件生成。
理论 #
一般框架 #
回顾VAE的loss(如果没印象请参考《变分自编码器(二):从贝叶斯观点出发》):
$$KL\Big(p(x,z)\Big\Vert q(x,z)\Big) = \iint p(z|x)\tilde{p}(x)\ln \frac{p(z|x)\tilde{p}(x)}{q(x|z)q(z)} dzdx\tag{1}$$
通常来说,我们会假设$q(z)$是标准正态分布,$p(z|x),q(x|z)$是条件正态分布,然后代入计算,就得到了普通的VAE的loss。
然而,也没有谁规定隐变量一定是连续变量吧?这里我们就将隐变量定为$(z, y)$,其中$z$是一个连续变量,代表编码向量;$y$是离散的变量,代表类别。直接把$(1)$中的$z$替换为$(z,y)$,就得到
$$KL\Big(p(x,z,y)\Big\Vert q(x,z,y)\Big) = \sum_y \iint p(z,y|x)\tilde{p}(x)\ln \frac{p(z,y|x)\tilde{p}(x)}{q(x|z,y)q(z,y)} dzdx\tag{2}$$
这就是用来做聚类的VAE的loss了。
分步假设 #
啥?就完事了?呃,是的,如果只考虑一般化的框架,$(2)$确实就完事了。
不过落实到实践中,$(2)$可以有很多不同的实践方案,这里介绍比较简单的一种。首先我们要明确,在$(2)$中,我们只知道$\tilde{p}(x)$(通过一批数据给出的经验分布),其他都是没有明确下来的。于是为了求解$(2)$,我们需要设定一些形式。一种选取方案为
$$p(z,y|x)=p(y|z)p(z|x),\quad q(x|z,y)=q(x|z),\quad q(z,y)=q(z|y)q(y)\tag{3}$$
代入$(2)$得到
$$KL\Big(p(x,z,y)\Big\Vert q(x,z,y)\Big) = \sum_y \iint p(y|z)p(z|x)\tilde{p}(x)\ln \frac{p(y|z)p(z|x)\tilde{p}(x)}{q(x|z)q(z|y)q(y)} dzdx\tag{4}$$
其实$(4)$式还是相当直观的,它分布描述了编码和生成过程:
1、从原始数据中采样到$x$,然后通过$p(z|x)$可以得到编码特征$z$,然后通过分类器$p(y|z)$对编码特征进行分类,从而得到类别;
2、从分布$q(y)$中选取一个类别$y$,然后从分布$q(z|y)$中选取一个随机隐变量$z$,然后通过生成器$q(x|z)$解码为原始样本。
具体模型 #
$(4)$式其实已经很具体了,我们只需要沿用以往VAE的做法:$p(z|x)$一般假设为均值为$\mu(x)$方差为$\sigma^2(x)$的正态分布,$q(x|z)$一般假设为均值为$G(z)$方差为常数的正态分布(等价于用MSE作为loss),$q(z|y)$可以假设为均值为$\mu_y$方差为1的正态分布,至于剩下的$q(y),p(y|z)$,$q(y)$可以假设为均匀分布(它就是个常数),也就是希望每个类大致均衡,而$p(y|z)$是对隐变量的分类器,随便用个softmax的网络就可以拟合了。
最后,可以形象地将$(4)$改写为
$$\mathbb{E}_{x\sim\tilde{p}(x)}\Big[-\log q(x|z) + \sum_y p(y|z) \log \frac{p(z|x)}{q(z|y)} + KL\big(p(y|z)\big\Vert q(y)\big)\Big],\quad z\sim p(z|x) \tag{5}$$
其中$z\sim p(z|x)$是重参数操作,而方括号中的三项loss,各有各的含义:
1、$-\log q(x|z)$希望重构误差越小越好,也就是$z$尽量保留完整的信息;
2、$\sum_y p(y|z) \log \frac{p(z|x)}{q(z|y)}$希望$z$能尽量对齐某个类别的“专属”的正态分布,就是这一步起到聚类的作用;
3、$KL\big(p(y|z)\big\Vert q(y)\big)$希望每个类的分布尽量均衡,不会发生两个几乎重合的情况(坍缩为一个类)。当然,有时候可能不需要这个先验要求,那就可以去掉这一项。
实验 #
实验代码自然是Keras完成的了(^_^),在mnist和fashion-mnist上做了实验,表现都还可以。实验环境:Keras 2.2 + tensorflow 1.8 + Python 2.7。
代码实现 #
代码位于:https://github.com/bojone/vae/blob/master/vae_keras_cluster.py
其实注释应该比较清楚了,而且相比普通的VAE改动不大。可能稍微有难度的是$\sum_y p(y|z) \log \frac{p(z|x)}{q(z|y)}$这个怎么实现。首先我们代入
$$\begin{aligned}p(z|x)&=\frac{1}{\prod\limits_{i=1}^d\sqrt{2\pi\sigma_i^2(x)}}\exp\left\{-\frac{1}{2}\left\Vert\frac{z - \mu(x)}{\sigma(x)}\right\Vert^2\right\}\\
q(z|y)&=\frac{1}{(2\pi)^{d/2}}\exp\left\{-\frac{1}{2}\left\Vert z - \mu_y\right\Vert^2\right\}\end{aligned}\tag{6}$$
得到
$$\log \frac{p(z|x)}{q(z|y)}=-\frac{1}{2}\sum_{i=1}^d \log \sigma_i^2(x)-\frac{1}{2}\left\Vert\frac{z - \mu(x)}{\sigma(x)}\right\Vert^2 + \frac{1}{2}\left\Vert z - \mu_y\right\Vert^2 \tag{7}$$
注意其实第二项是多余的,因为重参数操作告诉我们$z = \varepsilon\otimes \sigma(x) + \mu(x),\,\varepsilon\sim \mathcal{N}(0,1)$,所以第二项实际上只是$-\Vert \varepsilon\Vert^2/2$,跟参数无关,所以$$\log \frac{p(z|x)}{q(z|y)}\sim -\frac{1}{2}\sum_{i=1}^d \log \sigma_i^2(x) + \frac{1}{2}\left\Vert z - \mu_y\right\Vert^2 \tag{8}$$
然后因为$y$是离散的,所以事实上$\sum_y p(y|z) \log \frac{p(z|x)}{q(z|y)}$就是一个矩阵乘法(相乘然后对某个公共变量求和,就是矩阵乘法的一般形式),用K.batch_dot实现。
其他的话,读者应该清楚普通的VAE的实现过程,然后才看本文的内容和代码,不然估计是一脸懵的。
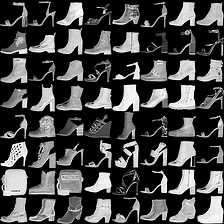
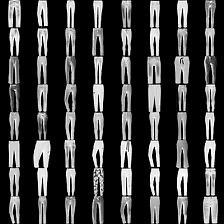
mnist #
这里是mnist的实验结果图示,包括类内样本图示和按类采样图示。最后还简单估算了一下,以每一类对应的数目最多的那个真实标签为类标签的话,最终的test准确率大约有83%,对比这篇文章《Unsupervised Deep Embedding for Clustering Analysis》的结果(最高也是84%左右),感觉应该很不错了。
聚类图示 #

聚类类别_0
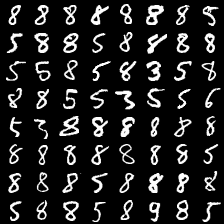
聚类类别_1
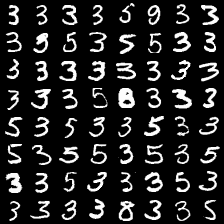
聚类类别_2
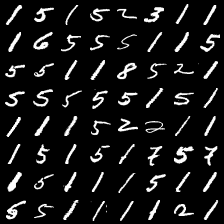
聚类类别_3
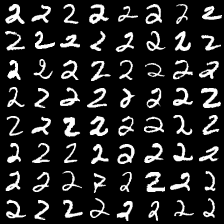
聚类类别_4
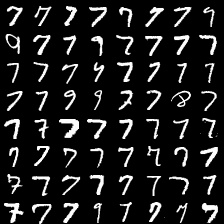
聚类类别_5
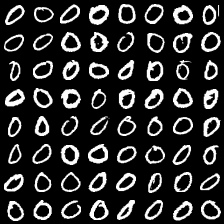
聚类类别_6
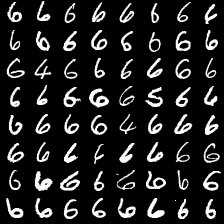
聚类类别_7

聚类类别_8
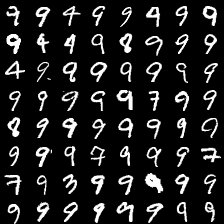
聚类类别_9
按类采样 #

类别采样_0

类别采样_1

类别采样_2

类别采样_3

类别采样_4

类别采样_5

类别采样_6

类别采样_7

类别采样_8

类别采样_9
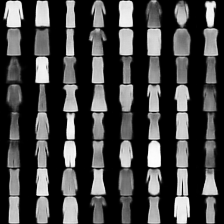
fashion-mnist #
这里是fashion-mnist的实验结果图示,包括类内样本图示和按类采样图示,最终的test准确率大约有58.5%。
聚类图示 #

聚类类别_0
聚类类别_1

聚类类别_2

聚类类别_3

聚类类别_4

聚类类别_5
聚类类别_6

聚类类别_7

聚类类别_8

聚类类别_9
按类采样 #
类别采样_0
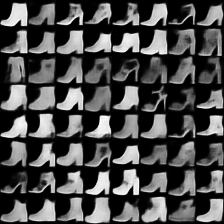
类别采样_1

类别采样_2

类别采样_3

类别采样_4

类别采样_5

类别采样_6

类别采样_7
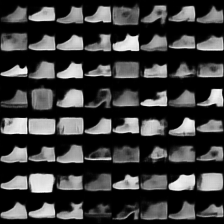
类别采样_8

类别采样_9
总结 #
文章简单地实现了一下基于VAE的聚类算法,算法的特点就是一步到位,结合“编码”、“聚类”和“生成”三个任务同时完成,思想是对VAE的loss的一般化。
感觉还有一定的提升空间,比如式$(4)$只是式$(2)$的一个例子,还可以考虑更加一般的情况。代码中的encoder和decoder也都没有经过仔细调优,仅仅是验证想法所用。
转载到请包括本文地址:https://kexue.fm/archives/5887
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Sep. 17, 2018). 《变分自编码器(四):一步到位的聚类方案 》[Blog post]. Retrieved from https://kexue.fm/archives/5887
@online{kexuefm-5887,
title={变分自编码器(四):一步到位的聚类方案},
author={苏剑林},
year={2018},
month={Sep},
url={\url{https://kexue.fm/archives/5887}},
}

December 25th, 2019
里面涉及到了分类器,聚类过程中使用分类可以吗?这样就不是传统意义上的分类了吗?
不知道你想表达的意思是什么?什么叫做“聚类过程中使用分类”?聚类不就是无监督地将数据归类么?还在乎用什么方法?
我看见代码vae = Model(x, [x_recon, z_prior_mean, y])中有个y,y是由分类器创建的,这个不就等于是三个loss中有了分类器的loss,分类器都是有监督的训练,这个模型出现了分类器,聚类等于是有用到分类标签的过程
可以仔细看一下代码,并没有用到标签,虽然名字是classifier,但是loss是无监督的,没有标签的参与,根据推导出的loss,softmax层的输出就是聚类标签
哪条法律规定分类器就一定是有监督训练的呢?
这种分类是指定分类的个数是10个,是对应正确的分类数。 是否可以理解这种为半监督的训练,因为在实际场景中有时候都不知道实际的分类个数?
如果指定类别数目就叫做半监督,那么K-Means也叫做半监督吗?如果是,那也无所谓了,反正就是个名字罢了。
天下没有免费的午餐,任何算法都会有一定的超参数,聚类也是如此。有些聚类算法不需要指定类别数,但其实就是转化为了其他形式的超参数。
February 23rd, 2020
博主,我觉得这样得想法可以发文章了啊。有点可惜啊,虽然本质上的创新博主写出来了就不觉得什么了,但是单看5式这个loss函数是很新颖的,顶会很有戏啊
谢谢你的肯定。
不过,类似的想法好像已经写成过论文了,比如《Variational Deep Embedding:An Unsupervised and Generative Approach to Clustering》。此外,就算本文真有什么创新之处,不发顶会也不算什么可惜的事情呀,知识能为人知道并传播,就已经实现了它的价值。
March 16th, 2020
大神您好,请问公式(3)这种选取方案是怎么得到的?前两个公式p(z,y|x)=p(y|z) p(z|x), q(x|z,y)=q(x|z)是怎么得到的?是假设x与y之间有独立的关系吗?期待您的回复。
等式就是假设本身,不需要其他二次解释。
换句话说,就是假设$p(z,y|x)=p(y|z)p(z|x),\quad q(x|z,y)=q(x|z),\quad q(z,y)=q(z|y)q(y)$,而不是由其他假设得到这两个等式。
March 16th, 2020
苏老师您好,每次看您的文章都让我受益匪浅。请问如果我按照《Variational Deep Embedding:An Unsupervised and Generative Approach to Clustering》将潜变量假设为混合高斯,但是是在监督分类的任务中使用,且每个高斯Component对应一个类,那么我可以把VAE中KL(P(z|x)||N(0,1))直接换成KL(p(z,c|x)||N($\mu_{c},\sigma_{c}$))吗? 这也能推导得出类似 KL(P(z|x)||N(0,1)) 的一个 closed解吗?
试试不就行了?
August 12th, 2020
您好,苏老师,您提到的q(z|y)是均值为uy,方差为1的正太分布,那这个uy是怎么得到呢?是从q(y)这个均匀分布采样一个值,然后这个值作为uy吗?
作为待优化参数让模型自己学习呀
October 9th, 2020
请教一下,可以用这个做文本的聚类吗? 生成模型 q(x|z)应该怎么选择? 可以写成下面这样方式吗? z = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_var])
x = Dense(latent_dim*maxlen,activation='relu')(z)
x_recon = Dense(len(char2id), activation='softmax')(x)
不大好做,因为这个模型本质上是VAE的推广,而文本VAE模型本身就不好训练,更不用说自然地聚类了。
October 12th, 2020
请问如果是做分类任务的话,是不是在现有的loss的基础上,额外增加一个对聚类结果p(y|z)的监督的loss就可以了呢?比如增加一个交叉熵作为loss,label是x的类别。
是的,可以这样做。
谢谢!想再问一下除了额外加这么一个loss这样做之外还有别的方法吗?我暂时只能想到这一个,但是听起来应该还是有别的方法的?
其实也没有什么好方法了。可以试试无标签数据直接训练$(5)$,有标签数据则不算$p(y|z)$,直接把这一步用真实标签代替(也就是有标签数据不训练$p(y|z)$了,而是用真实标签训练$q(x|z),q(z|y),p(z|x)$)。
好的,感谢!
December 4th, 2020
苏老师,请教您几个问题。
我想用VAE来替代K-means聚类。我的数据只有700多个图,分为正常人和病人两类。请问用VAE是否可行? 因为我只是希望对全部数据聚类,替代kmeans聚类,是不是可以将全部数据就看成训练集,不用再分测试集?另外,我聚类时,两个类的数量不是均衡的,是否需要去掉公式(5)三项loss的最后一项?
谢谢。
上面的问题请忽略,我想我应该知道答案了,谢谢
好的。
January 21st, 2021
苏老师,我用你提供的方法进行聚类。输入数据是正常人和病人的脑功能连接矩阵(每个矩阵大小112*112),训练集有2万多个脑功能连接矩阵(病人数稍微多于正常人),验证集有750个脑功能连接矩阵(病人数稍微多于正常人)。我直接用了您的模型,模型方面我就修改了num_classes = 2
img_dim = 112,其他部分都没有改。我现在用您的方法得到的聚类正确率只有50%多,请问我应该从哪里找原因?
现在我能想到的一个原因是病人和正常人的脑功能连接矩阵有较大的相似性,只有部分位置存在差异。现在我是把整个矩阵输入到您的这个代码中的。
我也不清楚,具体例子具体分析吧。
苏老师,请问您,您模型中的那些参数,包括卷积滤波器filters个数,模型层数怎么设置,和数据量大小等有什么关系,关于设置这些参数,您有没有推荐的资料?我刚刚开始做机器学习方面的工作,对这方面了解很少,谢谢您。
没有,你可能需要好好入门一段时间再来做应用。
谢谢您的回复,您能否推荐一些入门资料,不好意思,麻烦您了
你可以按时间顺序来阅读本博客文章。其他资料我也没有了。
January 29th, 2021
苏老师,关于loss的问题向您请教。
1.您的代码中:lamb = 2.5 # 这是重构误差的权重,它的相反数就是重构方差,越大意味着方差越小。请问这个lamb值的选择有什么依据,是从图像数据中估计出来的吗?
2.xent_loss,kl_loss,cat_loss这3个loss最终要达到大概什么样的比例,聚类的效果会好?
请您指点一二,谢谢
1、拍脑袋调的;
2、理论上总的loss越小越好。