






20
Nov
跟风玩玩目前最大的中文GPT2模型(bert4keras)
By 苏剑林 | 2020-11-20 | 94304位读者 | 引用相信不少读者这几天都看到了清华大学与智源人工智能研究院一起搞的“清源计划”(相关链接《中文版GPT-3来了?智源研究院发布清源 CPM —— 以中文为核心的大规模预训练模型》),里边开源了目前最大的中文GPT2模型CPM-LM(26亿参数),据说未来还会开源200亿甚至1000亿参数的模型,要打造“中文界的GPT3”。

官方给出的CPM-LM的Few Shot效果演示图
我们知道,GPT3不需要finetune就可以实现Few Shot,而目前CPM-LM的演示例子中,Few Shot的效果也是相当不错的,让人跃跃欲试,笔者也不例外。既然要尝试,肯定要将它适配到自己的bert4keras中才顺手,于是适配工作便开始了。本以为这是一件很轻松的事情,谁知道踩坑踩了快3天才把它搞好,在此把踩坑与测试的过程稍微记录一下。
11
Nov
当GPT遇上中国象棋:写过文章解过题,要不再来下盘棋?
By 苏剑林 | 2020-11-11 | 77194位读者 | 引用
中国象棋
不知道读者有没有看过量子位年初的文章《最强写作AI竟然学会象棋和作曲,语言模型跨界操作引热议,在线求战》,里边提到有网友用GPT2模型训练了一个下国际象棋的模型。笔者一直在想,这么有趣的事情怎么可以没有中文版呢?对于国际象棋来说,其中文版自然就是中国象棋了,于是我一直有想着把它的结果在中国象棋上面复现一下。拖了大半年,在最近几天终于把这个事情完成了,在此跟大家分享一下。
象棋谱式
将军不离九宫内,士止相随不出官。
象飞四方营四角,马行一步一尖冲。
炮须隔子打一子,车行直路任西东。
唯卒只能行一步,过河横进退无踪。
6
Nov
那个屠榜的T5模型,现在可以在中文上玩玩了
By 苏剑林 | 2020-11-06 | 186691位读者 | 引用不知道大家对Google去年的屠榜之作T5还有没有印象?就是那个打着“万事皆可Seq2Seq”的旗号、最大搞了110亿参数、一举刷新了GLUE、SuperGLUE等多个NLP榜单的模型,而且过去一年了,T5仍然是SuperGLUE榜单上的第一,目前还稳妥地拉开着第二名2%的差距。然而,对于中文界的朋友来说,T5可能没有什么存在感,原因很简单:没有中文版T5可用。不过这个现状要改变了,因为Google最近放出了多国语言版的T5(mT5),里边当然是包含了中文语言。虽然不是纯正的中文版,但也能凑合着用一下。
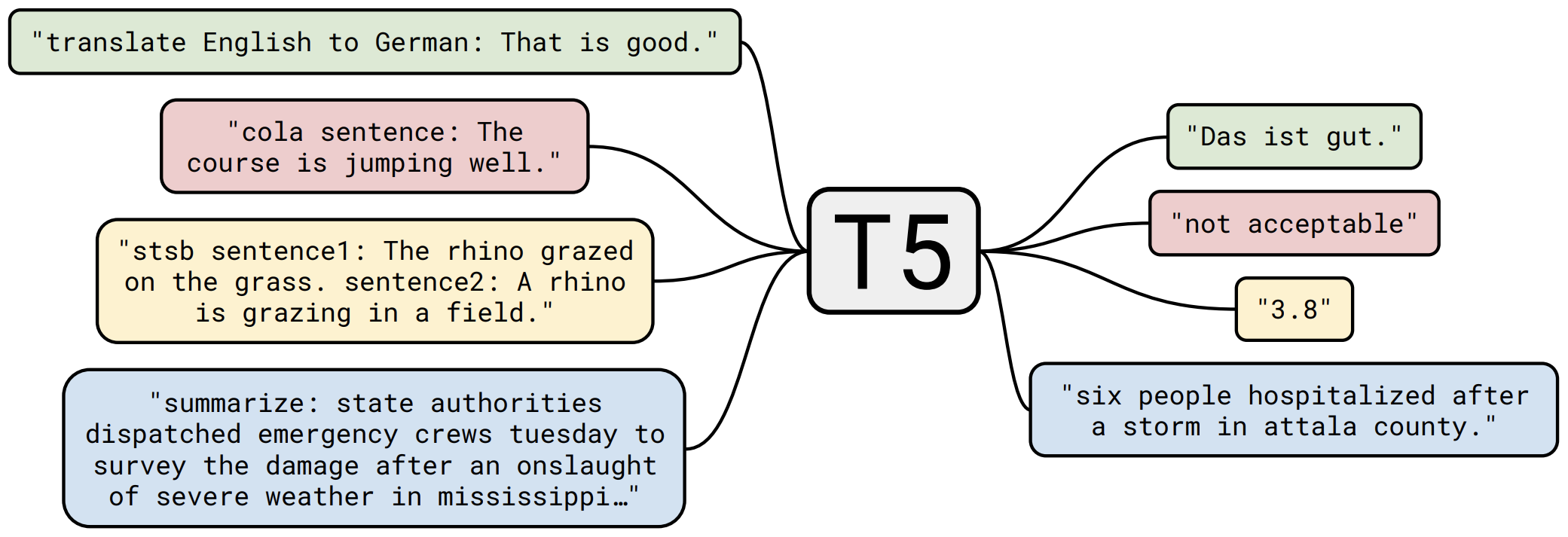
“万事皆可Seq2Seq”的T5
本文将会对T5模型做一个简单的回顾与介绍,然后再介绍一下如何在bert4keras中调用mT5模型来做中文任务。作为一个原生的Seq2Seq预训练模型,mT5在文本生成任务上的表现还是相当不错的,非常值得一试。
29
Oct
用ALBERT和ELECTRA之前,请确认你真的了解它们
By 苏剑林 | 2020-10-29 | 96646位读者 | 引用在预训练语言模型中,ALBERT和ELECTRA算是继BERT之后的两个“后起之秀”。它们从不同的角度入手对BERT进行了改进,最终提升了效果(至少在不少公开评测数据集上是这样),因此也赢得了一定的口碑。但在平时的交流学习中,笔者发现不少朋友对这两个模型存在一些误解,以至于在使用过程中浪费了不必要的时间。在此,笔者试图对这两个模型的一些关键之处做下总结,供大家参考,希望大家能在使用这两个模型的时候少走一些弯路。

ALBERT与ELECTRA
(注:本文中的“BERT”一词既指开始发布的BERT模型,也指后来的改进版RoBERTa,我们可以将BERT理解为没充分训练的RoBERTa,将RoBERTa理解为更充分训练的BERT。本文主要指的是它跟ALBERT和ELECTRA的对比,因此不区分BERT和RoBERTa。)
18
Sep
提速不掉点:基于词颗粒度的中文WoBERT
By 苏剑林 | 2020-09-18 | 153733位读者 | 引用当前,大部分中文预训练模型都是以字为基本单位的,也就是说中文语句会被拆分为一个个字。中文也有一些多颗粒度的语言模型,比如创新工场的ZEN和字节跳动的AMBERT,但这类模型的基本单位还是字,只不过想办法融合了词信息。目前以词为单位的中文预训练模型很少,据笔者所了解到就只有腾讯UER开源了一个以词为颗粒度的BERT模型,但实测效果并不好。
那么,纯粹以词为单位的中文预训练模型效果究竟如何呢?有没有它的存在价值呢?最近,我们预训练并开源了以词为单位的中文BERT模型,称之为WoBERT(Word-based BERT,我的BERT!),实验显示基于词的WoBERT在不少任务上有它独特的优势,比如速度明显的提升,同时效果基本不降甚至也有提升。在此对我们的工作做一个总结。
7
Sep
动手做个DialoGPT:基于LM的生成式多轮对话模型
By 苏剑林 | 2020-09-07 | 177511位读者 | 引用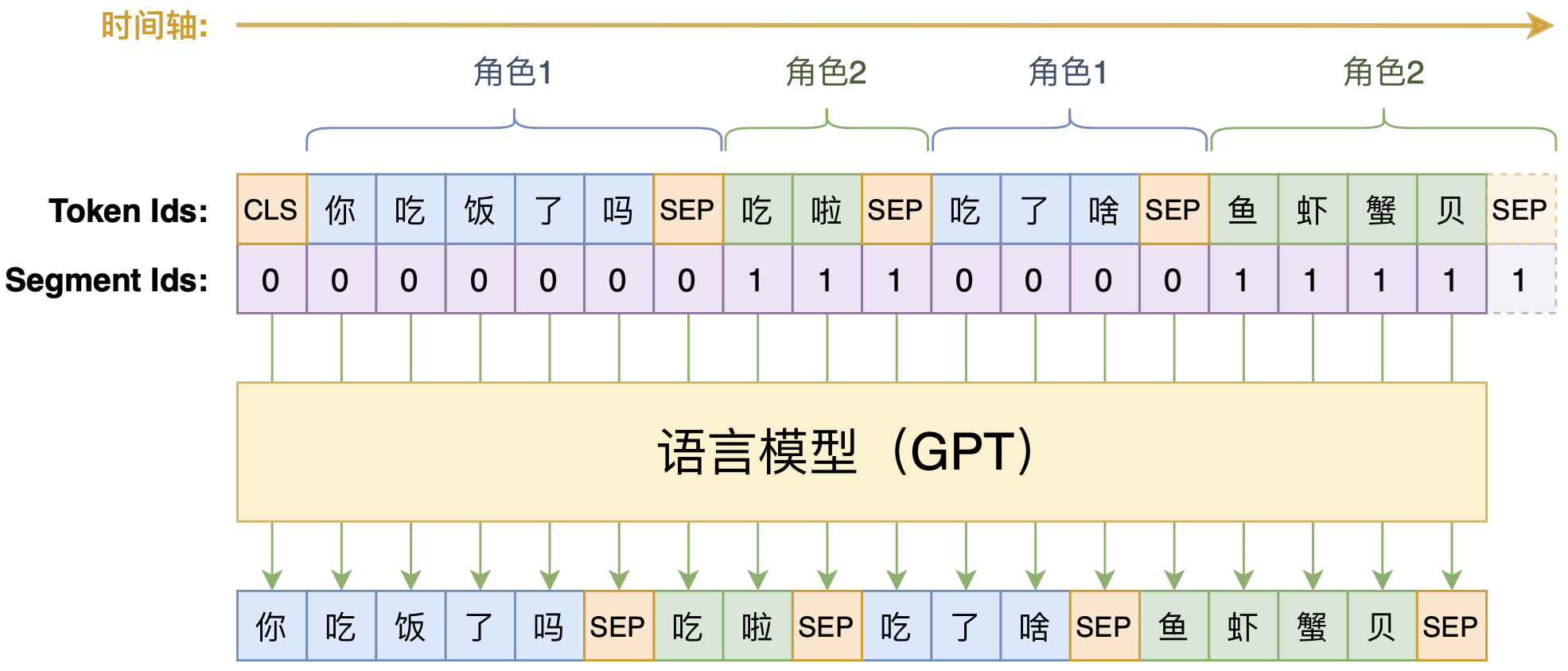
7
Aug
修改Transformer结构,设计一个更快更好的MLM模型
By 苏剑林 | 2020-08-07 | 80162位读者 | 引用大家都知道,MLM(Masked Language Model)是BERT、RoBERTa的预训练方式,顾名思义,就是mask掉原始序列的一些token,然后让模型去预测这些被mask掉的token。随着研究的深入,大家发现MLM不单单可以作为预训练方式,还能有很丰富的应用价值,比如笔者之前就发现直接加载BERT的MLM权重就可以当作UniLM来做Seq2Seq任务(参考这里),又比如发表在ACL 2020的《Spelling Error Correction with Soft-Masked BERT》将MLM模型用于文本纠错。
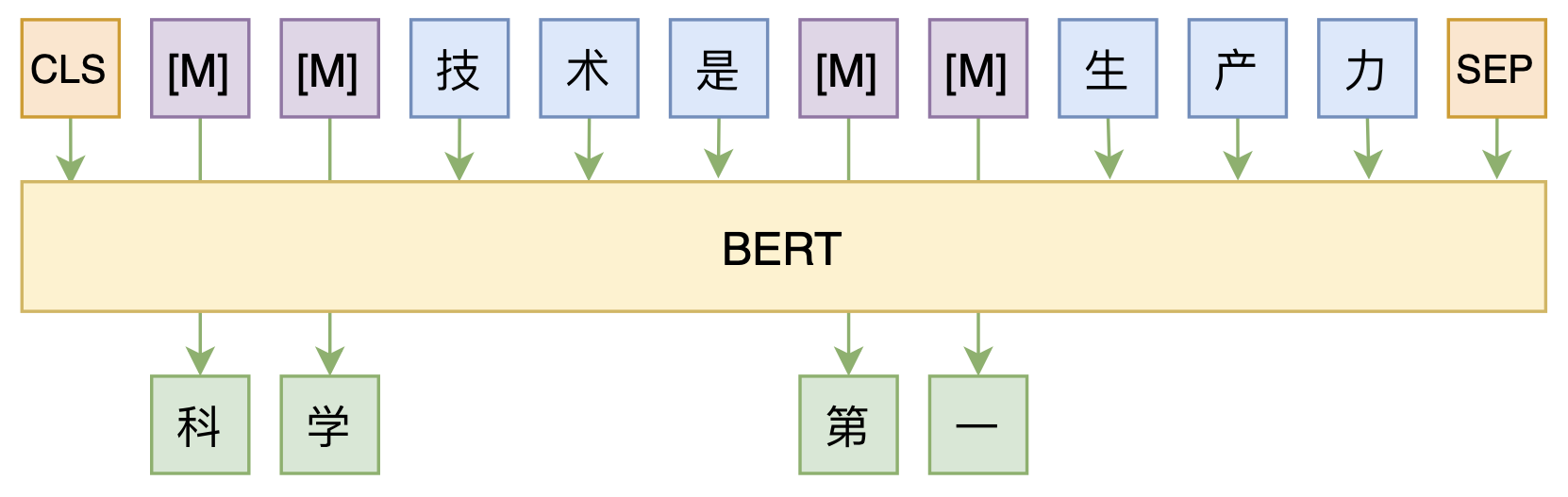
MLM任务示意图
然而,仔细读过BERT的论文或者亲自尝试过的读者应该都知道,原始的MLM的训练效率是比较低的,因为每次只能mask掉一小部分的token来训练。ACL 2020的论文《Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning》也思考了这个问题,并且提出了一种新的MLM模型设计,能够有更高的训练效率和更好的效果。
17
Jul
BERT-of-Theseus:基于模块替换的模型压缩方法
By 苏剑林 | 2020-07-17 | 124752位读者 | 引用最近了解到一种称为“BERT-of-Theseus”的BERT模型压缩方法,来自论文《BERT-of-Theseus: Compressing BERT by Progressive Module Replacing》。这是一种以“可替换性”为出发点所构建的模型压缩方案,相比常规的剪枝、蒸馏等手段,它整个流程显得更为优雅、简洁。本文将对该方法做一个简要的介绍,给出一个基于bert4keras的实现,并验证它的有效性。

BERT-of-Theseus,原作配图
模型压缩
首先,我们简要介绍一下模型压缩。不过由于笔者并非专门做模型压缩的,也没有经过特别系统的调研,所以该介绍可能显得不专业,请读者理解。

最近评论