






1
Dec
Performer:用随机投影将Attention的复杂度线性化
By 苏剑林 | 2020-12-01 | 88224位读者 | 引用Attention机制的$\mathcal{O}(n^2)$复杂度是一个老大难问题了,改变这一复杂度的思路主要有两种:一是走稀疏化的思路,比如我们以往介绍过的Sparse Attention以及Google前几个月搞出来的Big Bird,等等;二是走线性化的思路,这部分工作我们之前总结在《线性Attention的探索:Attention必须有个Softmax吗?》中,读者可以翻看一下。本文则介绍一项新的改进工作Performer,出自Google的文章《Rethinking Attention with Performers》,它的目标相当霸气:通过随机投影,在不损失精度的情况下,将Attention的复杂度线性化。
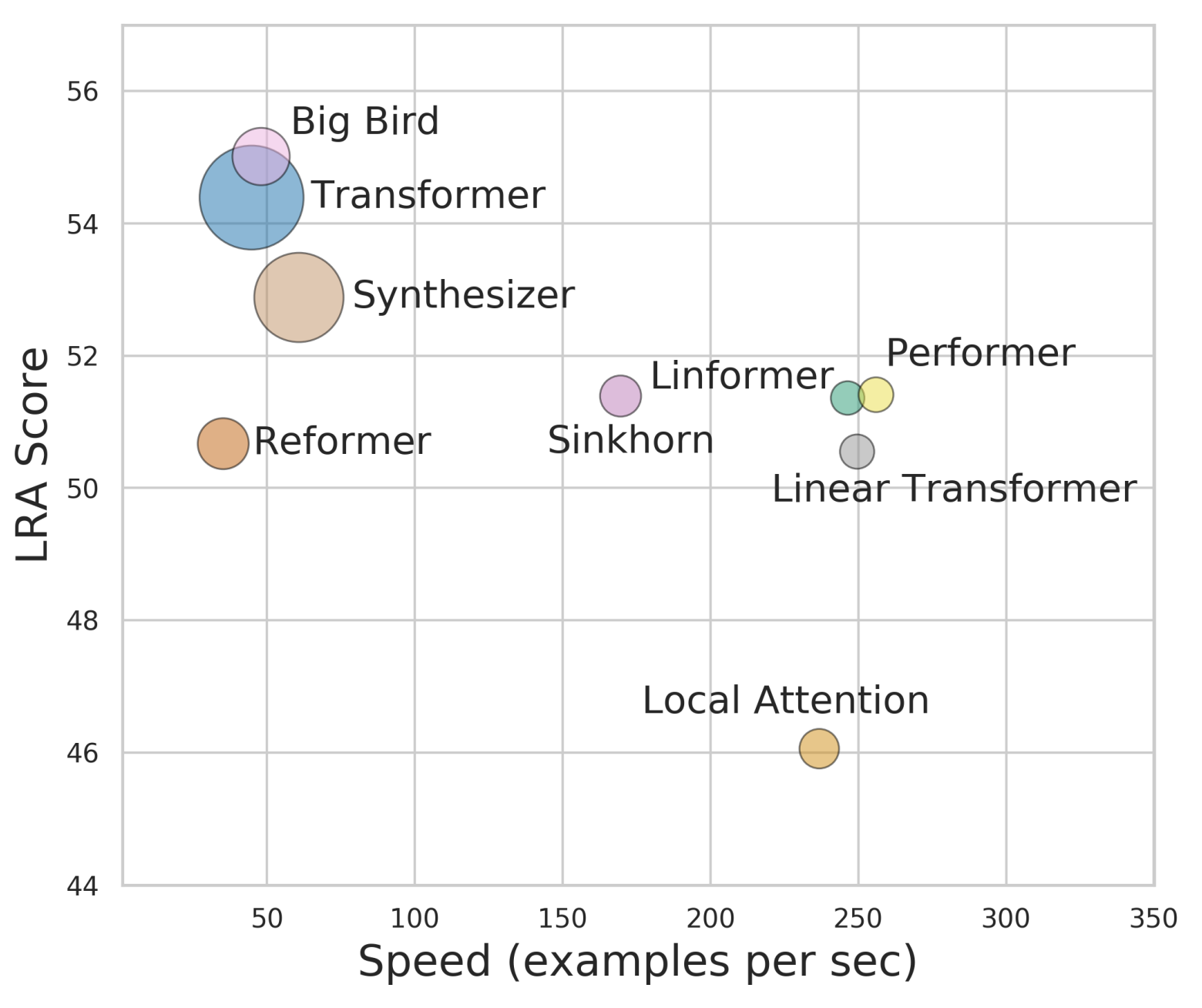
各个Transformer模型的“效果-速度-显存”图,纵轴是效果,横轴是速度,圆圈的大小代表所需要的显存。理论上来说,越靠近右上方的模型越好,圆圈越小的模型越好
说直接点,就是理想情况下我们可以不用重新训练模型,输出结果也不会有明显变化,但是复杂度降到了$\mathcal{O}(n)$!看起来真的是“天上掉馅饼”般的改进了,真的有这么美好吗?
24
Dec
RealFormer:把残差转移到Attention矩阵上面去
By 苏剑林 | 2020-12-24 | 104806位读者 | 引用大家知道Layer Normalization是Transformer模型的重要组成之一,它的用法有PostLN和PreLN两种,论文《On Layer Normalization in the Transformer Architecture》中有对两者比较详细的分析。简单来说,就是PreLN对梯度下降更加友好,收敛更快,对训练时的超参数如学习率等更加鲁棒等,反正一切都好但就有一点硬伤:PreLN的性能似乎总略差于PostLN。最近Google的一篇论文《RealFormer: Transformer Likes Residual Attention》提出了RealFormer设计,成功地弥补了这个Gap,使得模型拥有PreLN一样的优化友好性,并且效果比PostLN还好,可谓“鱼与熊掌兼得”了。
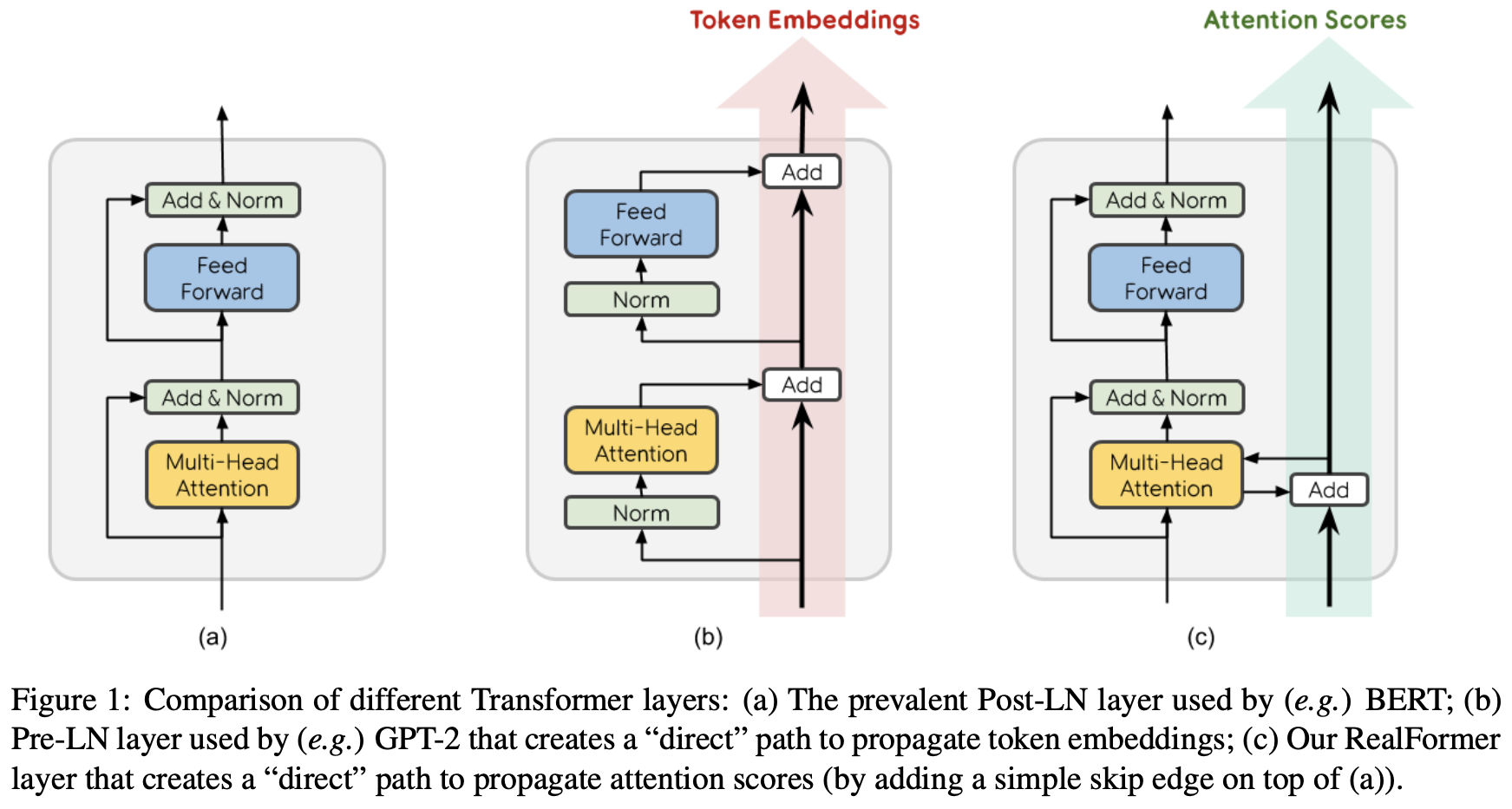
PostLN、PreLN和RealFormer结构示意图
8
Jul
两个多元正态分布的KL散度、巴氏距离和W距离
By 苏剑林 | 2021-07-08 | 114435位读者 | 引用正态分布是最常见的连续型概率分布之一。它是给定均值和协方差后的最大熵分布(参考《“熵”不起:从熵、最大熵原理到最大熵模型(二)》),也可以看作任意连续型分布的二阶近似,它的地位就相当于一般函数的线性近似。从这个角度来看,正态分布算得上是最简单的连续型分布了。也正因为简单,所以对于很多估计量来说,它都能写出解析解来。
本文主要来计算两个多元正态分布的几种度量,包括KL散度、巴氏距离和W距离,它们都有显式解析解。
正态分布
这里简单回顾一下正态分布的一些基础知识。注意,仅仅是回顾,这还不足以作为正态分布的入门教程。
概率密度
正态分布,也即高斯分布,是定义在$\mathbb{R}^n$上的连续型概率分布,其概率密度函数为
\begin{equation}p(\boldsymbol{x})=\frac{1}{\sqrt{(2\pi)^n \det(\boldsymbol{\Sigma})}}\exp\left\{-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{\top}\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right\}\end{equation}
26
Apr
中文任务还是SOTA吗?我们给SimCSE补充了一些实验
By 苏剑林 | 2021-04-26 | 247552位读者 | 引用今年年初,笔者受到BERT-flow的启发,构思了成为“BERT-whitening”的方法,并一度成为了语义相似度的新SOTA(参考《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》,论文为《Whitening Sentence Representations for Better Semantics and Faster Retrieval》)。然而“好景不长”,在BERT-whitening提交到Arxiv的不久之后,Arxiv上出现了至少有两篇结果明显优于BERT-whitening的新论文。
第一篇是《Generating Datasets with Pretrained Language Models》,这篇借助模板从GPT2_XL中无监督地构造了数据对来训练相似度模型,个人认为虽然有一定的启发而且效果还可以,但是复现的成本和变数都太大。另一篇则是本文的主角《SimCSE: Simple Contrastive Learning of Sentence Embeddings》,它提出的SimCSE在英文数据上显著超过了BERT-flow和BERT-whitening,并且方法特别简单~
那么,SimCSE在中文上同样有效吗?能大幅提高中文语义相似度的效果吗?本文就来做些补充实验。
17
Jun
对比学习可以使用梯度累积吗?
By 苏剑林 | 2021-06-17 | 65434位读者 | 引用在之前的文章《用时间换取效果:Keras梯度累积优化器》中,我们介绍过“梯度累积”,它是在有限显存下实现大batch_size效果的一种技巧。一般来说,梯度累积适用的是loss是独立同分布的场景,换言之每个样本单独计算loss,然后总loss是所有单个loss的平均或求和。然而,并不是所有任务都满足这个条件的,比如最近比较热门的对比学习,每个样本的loss还跟其他样本有关。
那么,在对比学习场景,我们还可以使用梯度累积来达到大batch_size的效果吗?本文就来分析这个问题。
简介
一般情况下,对比学习的loss可以写为
\begin{equation}\mathcal{L}=-\sum_{i,j=1}^b t_{i,j}\log p_{i,j} = -\sum_{i,j=1}^b t_{i,j}\log \frac{e^{s_{i,j}}}{\sum\limits_j e^{s_{i,j}}}=-\sum_{i,j=1}^b t_{i,j}s_{i,j} + \sum_{i=1}^b \log\sum_{j=1}^b e^{s_{i,j}}\label{eq:loss}\end{equation}
这里的$b$是batch_size;$t_{i,j}$是事先给定的标签,满足$t_{i,j}=t_{j,i}$,它是一个one hot矩阵,每一列只有一个1,其余都为0;而$s_{i,j}$是样本$i$和样本$j$的相似度,满足$s_{i,j}=s_{j,i}$,一般情况下还有个温度参数,这里假设温度参数已经整合到$s_{i,j}$中,从而简化记号。模型参数存在于$s_{i,j}$中,假设为$\theta$。
31
Oct
bert4keras在手,baseline我有:CLUE基准代码
By 苏剑林 | 2021-10-31 | 82942位读者 | 引用CLUE(Chinese GLUE)是中文自然语言处理的一个评价基准,目前也已经得到了较多团队的认可。CLUE官方Github提供了tensorflow和pytorch的baseline,但并不易读,而且也不方便调试。事实上,不管是tensorflow还是pytorch,不管是CLUE还是GLUE,笔者认为能找到的baseline代码,都很难称得上人性化,试图去理解它们是一件相当痛苦的事情。
所以,笔者决定基于bert4keras实现一套CLUE的baseline。经过一段时间的测试,基本上复现了官方宣称的基准成绩,并且有些任务还更优。最重要的是,所有代码尽量保持了清晰易读的特点,真·“Deep Learning for Humans”。
代码简介
下面简单介绍一下该代码中各个任务baseline的构建思路。在阅读文章和代码之前,请读者自行先观察一下每个任务的数据格式,这里不对任务数据进行详细介绍。
8
Sep
有限内存下全局打乱几百G文件(Python)
By 苏剑林 | 2021-09-08 | 76681位读者 | 引用这篇文章我们来做一道编程题:
如何在有限内存下全局随机打乱(Shuffle)几百G的文本文件?
题目背景其实很明朗,现在预训练模型动辄就几十甚至几百G语料了,为了让模型能更好地进行预训练,对训练语料进行一次全局的随机打乱是很有必要的。但对于很多人来说,几百G的语料往往比内存还要大,所以如何能在有限内存下做到全局的随机打乱,便是一个很值得研究的问题了。
已有工具
假设我们的文件是按行存储的,也就是一行代表一个样本,我们要做的就是按行随机打乱文件。假设我们只有一个文件,并且这个文件大小明显小于内存,那么我们可以用linux自带的shuf命令:
shuf input.txt -o output.txt
6
Jan
CoSENT(一):比Sentence-BERT更有效的句向量方案
By 苏剑林 | 2022-01-06 | 246112位读者 | 引用学习句向量的方案大致上可以分为无监督和有监督两大类,其中有监督句向量比较主流的方案是Facebook提出的“InferSent”,而后的“Sentence-BERT”进一步在BERT上肯定了它的有效性。然而,不管是InferSent还是Sentence-BERT,它们在理论上依然相当令人迷惑,因为它们虽然有效,但存在训练和预测不一致的问题,而如果直接优化预测目标cos值,效果往往特别差。
最近,笔者再次思考了这个问题,经过近一周的分析和实验,大致上确定了InferSent有效以及直接优化cos值无效的原因,并提出了一个优化cos值的新方案CoSENT(Cosine Sentence)。实验显示,CoSENT在收敛速度和最终效果上普遍都比InferSent和Sentence-BERT要好。
朴素思路
本文的场景是利用文本匹配的标注数据来构建句向量模型,其中所利用到的标注数据是常见的句子对样本,即每条样本是“(句子1, 句子2, 标签)”的格式,它们又大致上可以分类“是非类型”、“NLI类型”、“打分类型”三种,参考《用开源的人工标注数据来增强RoFormer-Sim》中的“分门别类”一节。
失效的Cos
简单起见,我们可以先只考虑“是非类型”的数据,即“(句子1, 句子2, 是否相似)”的样本。假设两个句子经过编码模型后分别得到向量$u,v$,由于检索阶段计算的是余弦相似度$\cos(u,v)=\frac{\langle u,v\rangle}{\Vert u\Vert \Vert v\Vert}$,所以比较自然的想法是设计基于$\cos(u,v)$的损失函数,比如
\begin{align}t\cdot (1 - \cos(u, v)) + (1 - t) \cdot (1 + \cos(u,v))\label{eq:cos-1}\\
t\cdot (1 - \cos(u, v))^2 + (1 - t) \cdot \cos^2(u,v)\label{eq:cos-2}
\end{align}

最近评论