






24
Dec
RealFormer:把残差转移到Attention矩阵上面去
By 苏剑林 | 2020-12-24 | 163364位读者 |大家知道Layer Normalization是Transformer模型的重要组成之一,它的用法有PostLN和PreLN两种,论文《On Layer Normalization in the Transformer Architecture》中有对两者比较详细的分析。简单来说,就是PreLN对梯度下降更加友好,收敛更快,对训练时的超参数如学习率等更加鲁棒等,反正一切都好但就有一点硬伤:PreLN的性能似乎总略差于PostLN。最近Google的一篇论文《RealFormer: Transformer Likes Residual Attention》提出了RealFormer设计,成功地弥补了这个Gap,使得模型拥有PreLN一样的优化友好性,并且效果比PostLN还好,可谓“鱼与熊掌兼得”了。
形式 #
RealFormer全称为“Residual Attention Layer Transformer”,即“残差式Attention层的Transformer模型”,顾名思义就是把残差放到了Attention里边了。
关于这个名字,还有个小插曲。这篇博客发布的时候,RealFormer其实叫做Informer,全称为“Residual Attention Transformer”,原论文名为《Informer: Transformer Likes Informed Attention》,显然从Informer这个名字我们很难想象它的全称,为此笔者还吐槽了Google在起名方面的生硬和任性。隔了一天之后,发现它改名为RealFormer了,遂做了同步。不知道是因为作者大佬看到了笔者的吐槽,还是因为Informer这个名字跟再早几天的一篇论文《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》重名了,哈哈~
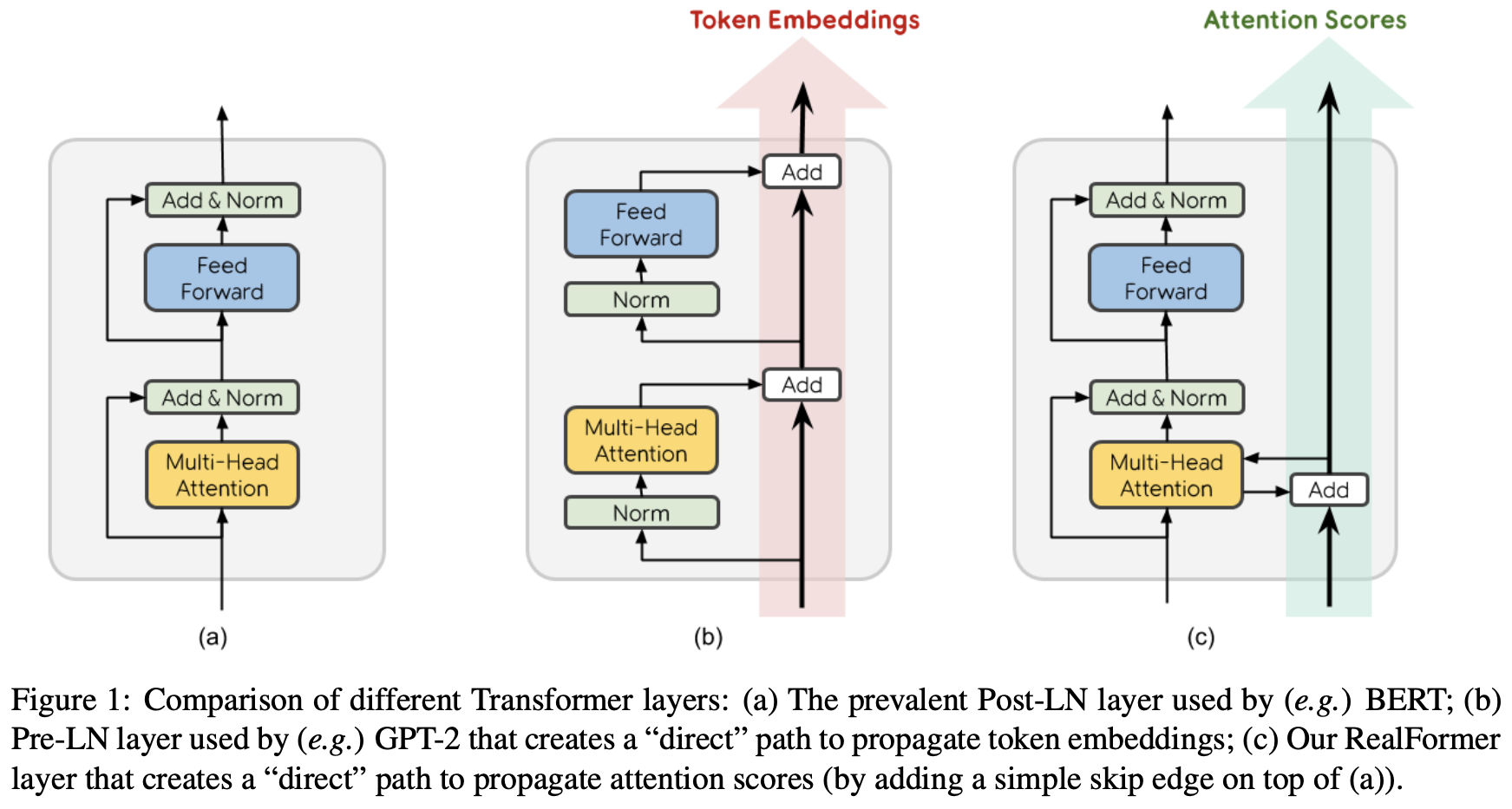
PostLN、PreLN和RealFormer结构示意图
说回模型,如上图所示,RealFormer主要是把残差放到了Attention矩阵上面了,而整体依然保持了PostLN的结构,因此既保持了PostLN的性能,又融合了残差的友好。具体来说,就是原来第$n$层的Attention为
\begin{equation}Attention(\boldsymbol{Q}_n,\boldsymbol{K}_n,\boldsymbol{V}_n) = softmax\left(\boldsymbol{A}_n\right)\boldsymbol{V}_n,\quad \boldsymbol{A}_n=\frac{\boldsymbol{Q}_n\boldsymbol{K}_n^{\top}}{\sqrt{d_k}}\end{equation}
现在改为了
\begin{equation}Attention(\boldsymbol{Q}_n,\boldsymbol{K}_n,\boldsymbol{V}_n) = softmax\left(\boldsymbol{A}_n\right)\boldsymbol{V}_n,\quad \boldsymbol{A}_n=\frac{\boldsymbol{Q}_n\boldsymbol{K}_n^{\top}}{\sqrt{d_k}} + \boldsymbol{A}_{n-1}\end{equation}
而已。全文终。
实验 #
当然,那么快就“全文终”是不可能的,好歹也得做做实验看看效果,但只看改动的话,确实已经终了,就那么简单。原论文做的实验很多,基本上所有的实验结果都显示在效果上:
$$\text{RealFormer}\geq \text{PostLN} \geq \text{PreLN}$$
看来,这次PostLN也许真的可以退场了。部分实验结果如下:

MLM准确率对比

SQuAD评测对比
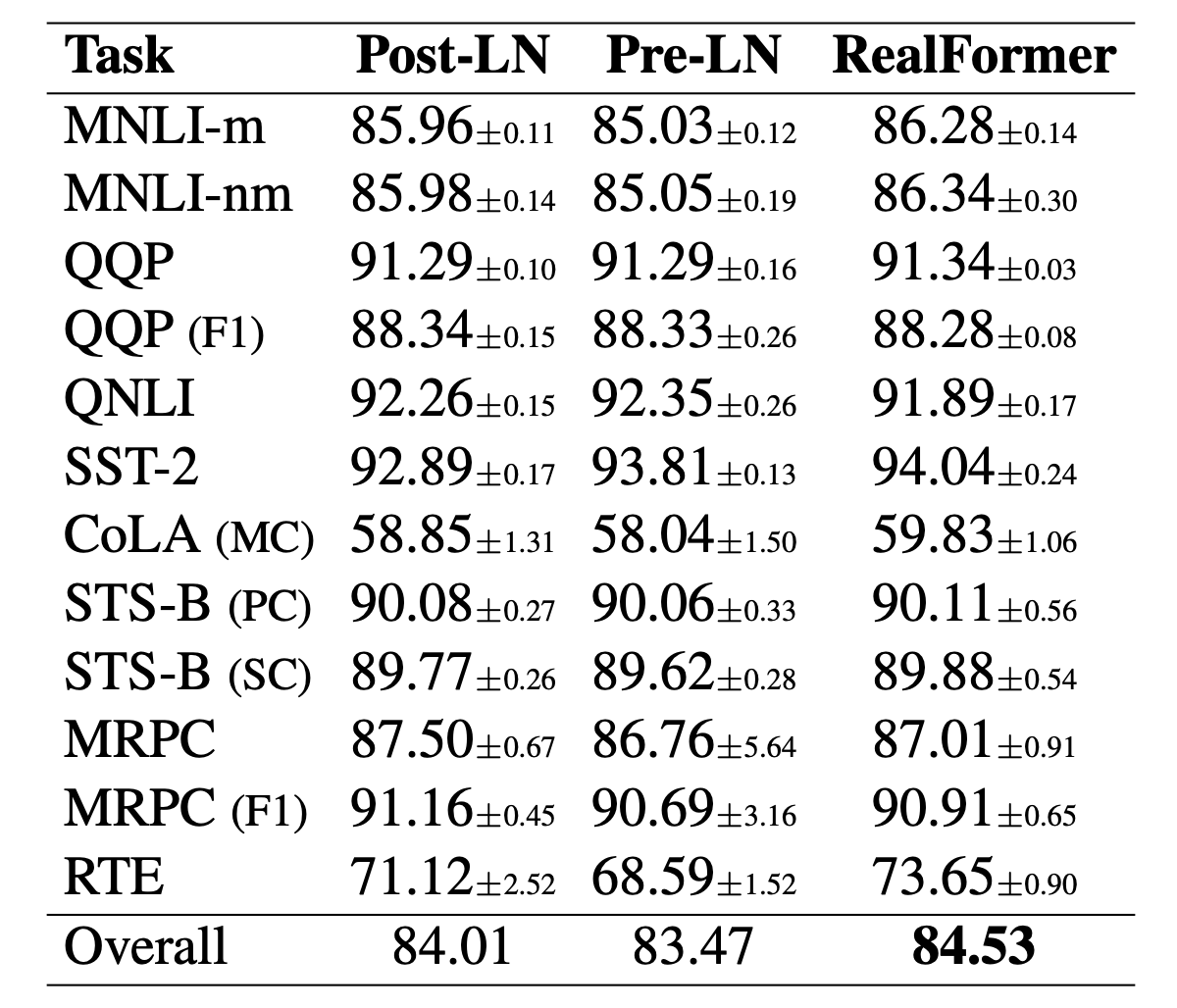
GLUE评测对比

不同训练步数效果对比
值得特别指出的是第一张图和第四张图。从第一张图我们可以看到,对于RealFormer结构,加大模型规模(large到xlarge)可以带来性能的明显提升,而ALBERT论文曾经提到加大BERT的模型规模并不能带来明显受益,结合两者说明这可能是PostLN的毛病而不是BERT的固有毛病,换成RealFormer可以改善这一点。从第四张图我们可以看到,RealFormer结构训练50万步,效果就相当于PostLN训练100万步,这表明RealFormer有着很高的训练效率。
除了上述实验外,论文还对比了不同学习率、不同Dropout比例的效果,表明RealFormer确实对这些参数是比较鲁棒的。原论文还分析了RealFormer的Attention值分布,表明RealFormer的Attention结果更加合理。
分析 #
这一节我们对RealFormer做一个简单的思考分析。
RealFormer对梯度下降更加友好,这不难理解,因为$\boldsymbol{A}_n=\frac{\boldsymbol{Q}_n\boldsymbol{K}_n^{\top}}{\sqrt{d_k}} + \boldsymbol{A}_{n-1}$的设计确实提供了一条直通路,使得第一层的Attention能够直通最后一层,自然就没有什么梯度消失的风险了。相比之下,PostLN是$\text{LayerNorm}(x + f(x))$的结构,看上去$x+f(x)$防止了梯度消失,但是$\text{LayerNorm}$这一步会重新增加了梯度消失风险,造成的后果是初始阶段前面的层梯度很小,后面的层梯度很大,如果用大学习率,后面的层容易崩,如果用小学习率,前面的层学不好,因此PostLN更难训练,需要用小的学习率加warmup慢慢训。
那么PreLN改善了梯度状况,为什么又比不上PostLN呢?按照笔者的猜测,PreLN每一步都是$x+f(x)$的形式,到了最后一层就变成了$x + f_1(x) + f_2(x) + \cdots + f_n(x)$的形式,一层层累加,可能导致数值和方差都很大,所以最后“迫不得已”会强制加一层Layer Norm让输出稳定下来。这样,尽管PreLN改善了梯度状况,但它本身设计上就存在一些不稳定因素,也许这就是它效果略差的原因。
事实上,很早就有人注意到残差的这个特点会造成不稳定,笔者之前研究GAN的时候,就发现《Which Training Methods for GANs do actually Converge?》一文中的实现就把$x + f(x)$换成了$x + 0.1 f(x)$。受到他们实现的启发,笔者也试过将$x + f(x)$换成$x + \alpha f(x)$,其中$\alpha$是初始化为0的可训练标量参数,也取得不错的效果。今年年初的论文《ReZero is All You Need: Fast Convergence at Large Depth》则正式地提出了这个方法,命名为ReZero,里边的实验表明用ReZero可以干脆去掉Layer Norm。遗憾的是,ReZero的论文没有对Transformer做更多的实验,而RealFormer也没有比较它与ReZero的效果差别。
读者可能会反驳,既然PreLN存在问题,那RealFormer的$\boldsymbol{A}_n=\frac{\boldsymbol{Q}_n\boldsymbol{K}_n^{\top}}{\sqrt{d_k}} + \boldsymbol{A}_{n-1}$不也是存在同样的叠加问题吗?如果只看$\boldsymbol{A}$,那么确实会有这样的问题,但别忘了$\boldsymbol{A}$后面还要做个softmax归一化后才参与运算,也就是说,模型对矩阵$\boldsymbol{A}$是自带归一化功能的,所以它不会有数值发散的风险。而且刚刚相反,随着层数的增加,$\boldsymbol{A}$的叠加会使得$\boldsymbol{A}$的元素绝对值可能越来越大,Attention逐渐趋于one hot形式,造成后面的层梯度消失,但是别忘了,我们刚才说PostLN前面的层梯度小后面的层梯度大,而现在也进一步缩小了后面层的梯度,反而使得两者更同步从而更好优化了;另一方面,Attention的概率值可能会有趋同的趋势,也就是说Attention的模式可能越来越稳定,带来类似ALBERT参数共享的正则化效应,这对模型效果来说可能是有利的。同时,直觉上来想,用RealFormer结构去做FastBERT之类的自适应层数的改进,效果会更好,因为RealFormer的Attention本身会有趋同趋势,更加符合FastBERT设计的出发点。
此外,我们也可以将RealFormer理解为还是使用了常规的残差结构,但是残差结构只用在$\boldsymbol{Q}, \boldsymbol{K}$而没有用在$\boldsymbol{V}$上:
\begin{equation}\begin{aligned}
&Attention(\boldsymbol{Q}_n,\boldsymbol{K}_n,\boldsymbol{V}_n) = softmax\left(\boldsymbol{A}_n\right)\boldsymbol{V}_n\\
&\boldsymbol{A}_n=\frac{\tilde{\boldsymbol{Q}}_n\tilde{\boldsymbol{K}}_n^{\top}}{\sqrt{d_k}},\quad\tilde{\boldsymbol{Q}}_n = \boldsymbol{Q}_n + \tilde{\boldsymbol{Q}}_{n-1}, \quad\tilde{\boldsymbol{K}}_n = \boldsymbol{K}_n + \tilde{\boldsymbol{K}}_{n-1}
\end{aligned}\end{equation}
这在一定程度上与$\boldsymbol{A}_n=\frac{\boldsymbol{Q}_n\boldsymbol{K}_n^{\top}}{\sqrt{d_k}} + \boldsymbol{A}_{n-1}$是等价的,而PreLN相当于$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$都加了残差。为啥$\boldsymbol{V}$“不值得”一个残差呢?从近来的一些相对位置编码的改进中,笔者发现似乎有一个共同的趋势,那就是去掉了$\boldsymbol{V}$的偏置,比如像NEZHA的相对位置编码,是同时在Attention矩阵(即$\boldsymbol{Q},\boldsymbol{K}$)和$\boldsymbol{V}$上施加的,而较新的XLNET和T5的相对位置编码则只施加在Attention矩阵上,所以,似乎去掉$\boldsymbol{V}$的不必要的偏置是一个比较好的选择,而RealFormer再次体现了这一点。
总结 #
本文介绍了Google对Transformer的新设计RealFormer,并给出了笔者自己的思考分析。实验结果表明,RealFormer同时有着PostLN和PreLN的优点,甚至比两者更好,是一个值得使用的改进点。
转载到请包括本文地址:https://kexue.fm/archives/8027
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Dec. 24, 2020). 《RealFormer:把残差转移到Attention矩阵上面去 》[Blog post]. Retrieved from https://kexue.fm/archives/8027
@online{kexuefm-8027,
title={RealFormer:把残差转移到Attention矩阵上面去},
author={苏剑林},
year={2020},
month={Dec},
url={\url{https://kexue.fm/archives/8027}},
}

February 3rd, 2021
大佬您好,您在文中提出的问题“为啥V‘不值得’一个残差呢?”后,给出了一些新模型去掉v的残差的证据,但好像并没有从您的观点来给出为什么这样做。在这里特地请教一下您认为为啥V‘不值得’一个残差呢?
那是因为我没有什么自己的观点呀~非要编一个的话,那就是感觉$V$上加偏置过于“显式”了,对梯度的干扰过于明显?而位置信息本身不应该那么明显?
我编的是“可能是想要一个纯净的$V$”~
September 16th, 2021
...但是LayerNorm这一步会重新增加了梯度消失风险,造成的后果是初始阶段前面的层梯度很小,后面的层梯度很大...
你好,怎么理解这句话呢?为什么LayerNorm的引入会导致梯度在不同层大小不一致呢?尤其是为什么是前面层梯度小,后面层梯度大。
能理解PreNorm时由于有一条通路使梯度不衰减。但这里有点疑惑。
可以参考这里的解释:
https://kexue.fm/archives/8620#%E6%AE%8B%E5%B7%AE%E8%BF%9E%E6%8E%A5
January 8th, 2022
[...]其次,梯度消失也不全是“坏处”,其实对于Finetune阶段来说,它反而是好处。在Finetune的时候,我们通常希望优先调整靠近输出层的参数,不要过度调整靠近输入层的参数,以免严重破坏预训练效果。而梯度消失意味着越靠近输入层,其结果对最终输出的影响越弱,这正好是Finetune时所希望的。所以,预训练好的Post Norm模型,往往比Pre Norm模型有更好的Finetune效果,这我们在《R[...]
January 11th, 2022
苏神,bert4keras已经支持residual_attention_scores了,那RealFormer+RoFormer是不是效果更好呢?后续会尝试吗?
RealFormer似乎会加大显存消耗,所以暂时没考虑。
January 22nd, 2024
請教一下,那 $A_0$ 應該是甚麼呢?一開始沒有任何 attention score,就直接輸入0矩陣嗎?
对,全零。或者理解为第二个Attention矩阵开始才有残差。
我做了實驗,發現 $\boldsymbol{A}_n=\frac{\boldsymbol{Q}_n\boldsymbol{K}_n^{\top}}{\sqrt{d_k}} + \boldsymbol{A}_{n-1}$ 最後似乎每一層得出的 weight 都會趨同?也就是
$softmax(A_n) \sim softmax(A_{n-1})$
會出現這結果似乎可以理解,如果模型只用第一層的 attention,忽略到中間層,就會有 $A_n = A_{n-1}$,因為沒有限制 $\boldsymbol{Q}_n\boldsymbol{K}_n^{\top}$ 不能為 0 ,只要QK後的兩個 Dense layer 通通輸出0,結果就退化了。
想到一個簡單的作法,直接在 QK 後面的 Dense 加上 $noise \sim 0.5*truncated(N(0, 1), [-2,2])$,就可避免$\boldsymbol{Q}_n\boldsymbol{K}_n^{\top}$ 為0,讓每一層 attention 不太一樣。
可能有这种情况,而且logits越来越大,大概率softmax会退化为one hot,另外,但序列很长时,Attention矩阵很大,残差Attention矩阵太费显存,这些也许都是realformer没流行起来的主要原因。
April 17th, 2024
大佬您好!您提到“那么PreLN改善了梯度状况,为什么又比不上PostLN呢?按照笔者的猜测,PreLN每一步都是x+f(x)
的形式,到了最后一层就变成了x+f1(x)+f2(x)+⋯+fn(x)
的形式,一层层累加,可能导致数值和方差都很大,所以最后“迫不得已”会强制加一层Layer Norm让输出稳定下来”,PreLN的思想不是来自于ResNet吗?那这么说几乎所有的ResNet都会出现最终数值和方差都很大这样的情况吗?
ResNet也有啊,但ResNet最后一层是Global Pooling到单个向量,这个操作一定程度上消除了方差。