






27
Aug
自己实现了一个bert4keras
By 苏剑林 | 2019-08-27 | 188482位读者 | 引用分享个人实现的bert4keras:
25
May
Google新作Synthesizer:我们还不够了解自注意力
By 苏剑林 | 2020-05-25 | 98066位读者 | 引用深度学习这个箱子,远比我们想象的要黑。
写在开头
据说物理学家费曼说过一句话[来源]:“谁要是说他懂得量子力学,那他就是真的不懂量子力学。”我现在越来越觉得,这句话中的“量子力学”也可以替换为“深度学习”。尽管深度学习已经在越来越多的领域证明了其有效性,但我们对它的解释性依然相当无力。当然,这几年来已经有不少工作致力于打开深度学习这个黑箱,但是很无奈,这些工作基本都是“马后炮”式的,也就是在已有的实验结果基础上提出一些勉强能说服自己的解释,无法做到自上而下的构建和理解模型的原理,更不用说提出一些前瞻性的预测。
本文关注的是自注意力机制。直观上来看,自注意力机制算是解释性比较强的模型之一了,它通过自己与自己的Attention来自动捕捉了token与token之间的关联,事实上在《Attention is All You Need》那篇论文中,就给出了如下的看上去挺合理的可视化效果:
《Attention is All You Need》一文中对Attention的可视化例子
但自注意力机制真的是这样生效的吗?这种“token对token”的注意力是必须的吗?前不久Google的新论文《Synthesizer: Rethinking Self-Attention in Transformer Models》对自注意力机制做了一些“异想天开”的探索,里边的结果也许会颠覆我们对自注意力的认知。
16
Apr
搜狐文本匹配:基于条件LayerNorm的多任务baseline
By 苏剑林 | 2021-04-16 | 96081位读者 | 引用前段时间看到了“2021搜狐校园文本匹配算法大赛”,觉得赛题颇有意思,便尝试了一下,不过由于比赛本身只是面向在校学生,所以笔者是不能作为正式参赛人员参赛的,因此把自己的做法开源出来,作为比赛baseline供大家参考。
赛题介绍
顾名思义,比赛的任务是文本匹配,即判断两个文本是否相似,本来是比较常规的任务,但有意思的是它分了多个子任务。具体来说,它分A、B两大类,A类匹配标准宽松一些,B类匹配标准严格一些,然后每个大类下又分为“短短匹配”、“短长匹配”、“长长匹配”3个小类,因此,虽然任务类型相同,但严格来看它是六个不同的子任务。
13
Nov
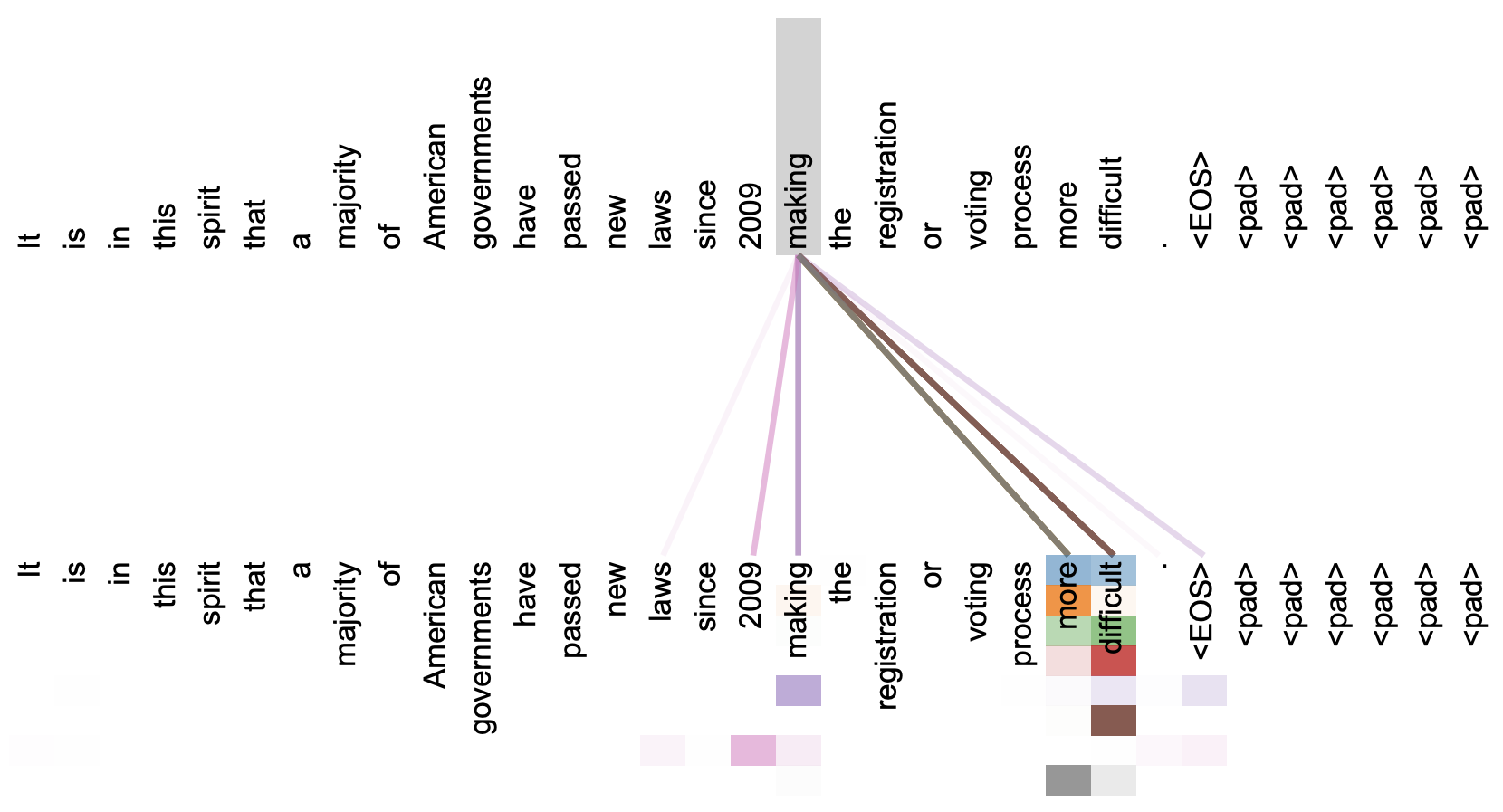
也来谈谈RNN的梯度消失/爆炸问题
By 苏剑林 | 2020-11-13 | 96510位读者 | 引用尽管Transformer类的模型已经攻占了NLP的多数领域,但诸如LSTM、GRU之类的RNN模型依然在某些场景下有它的独特价值,所以RNN依然是值得我们好好学习的模型。而对于RNN梯度的相关分析,则是一个从优化角度思考分析模型的优秀例子,值得大家仔细琢磨理解。君不见,诸如“LSTM为什么能解决梯度消失/爆炸”等问题依然是目前流行的面试题之一...
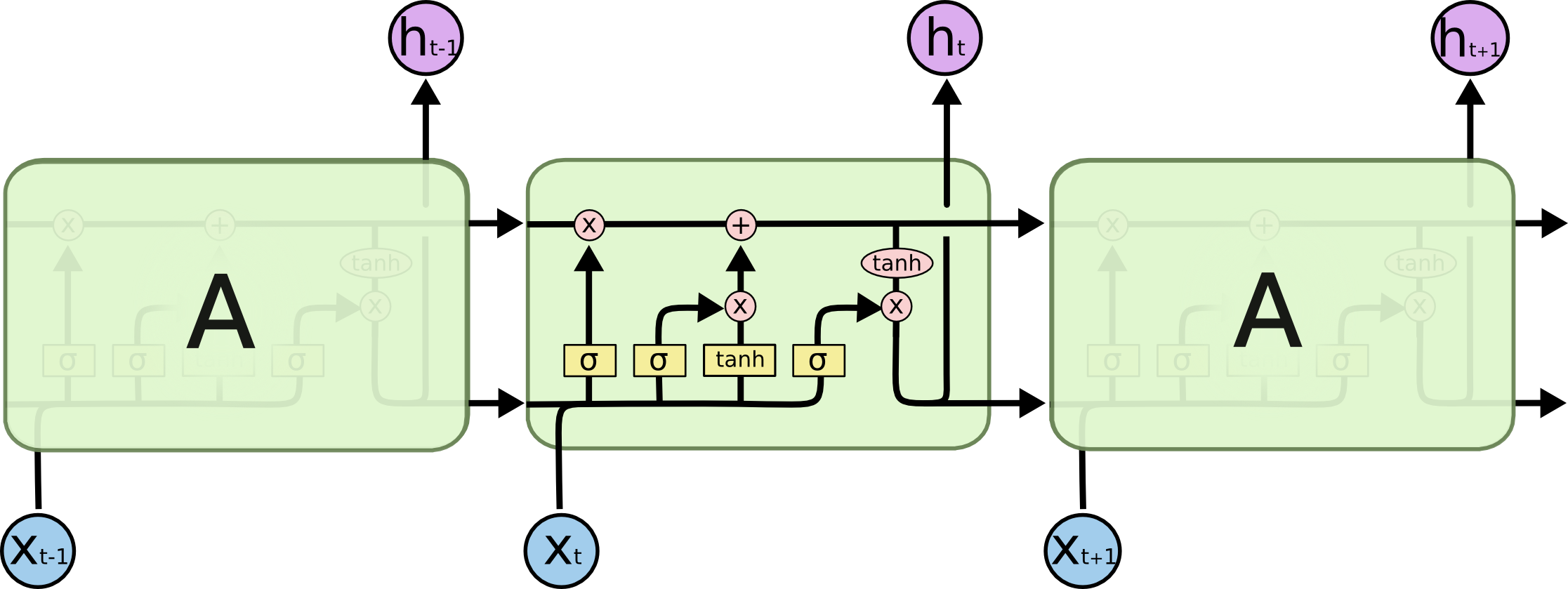
经典的LSTM
关于此类问题,已有不少网友做出过回答,然而笔者查找了一些文章(包括知乎上的部分回答、专栏以及经典的英文博客),发现没有找到比较好的答案:有些推导记号本身就混乱不堪,有些论述过程没有突出重点,整体而言感觉不够清晰自洽。为此,笔者也尝试给出自己的理解,供大家参考。
1
Jul
又是Dropout两次!这次它做到了有监督任务的SOTA
By 苏剑林 | 2021-07-01 | 228364位读者 | 引用关注NLP新进展的读者,想必对四月份发布的SimCSE印象颇深,它通过简单的“Dropout两次”来构造正样本进行对比学习,达到了无监督语义相似度任务的全面SOTA。无独有偶,最近的论文《R-Drop: Regularized Dropout for Neural Networks》提出了R-Drop,它将“Dropout两次”的思想用到了有监督任务中,每个实验结果几乎都取得了明显的提升。此外,笔者在自己的实验还发现,它在半监督任务上也能有不俗的表现。
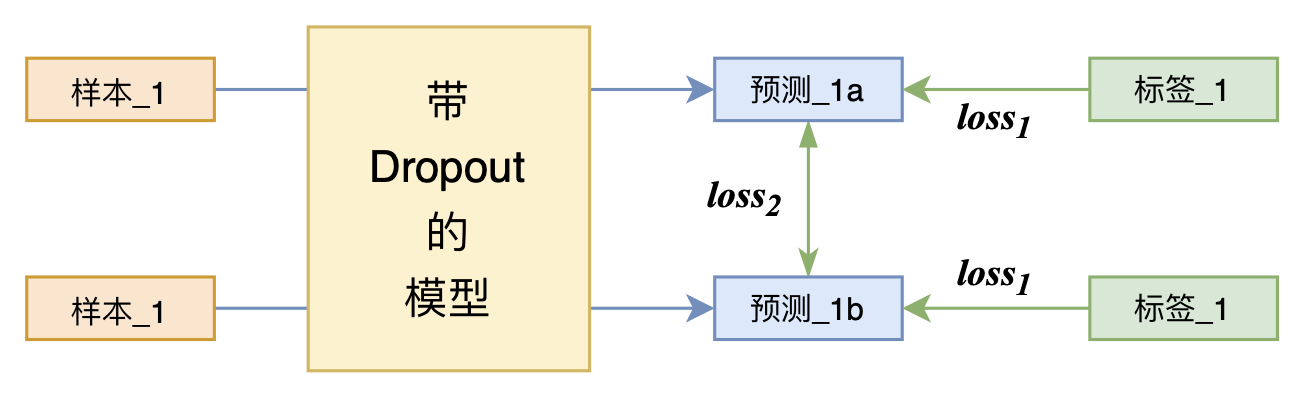
R-Drop示意图
小小的“Dropout两次”,居然跑出了“五项全能”的感觉,不得不令人惊讶。本文来介绍一下R-Drop,并分享一下笔者对它背后原理的思考。
21
Dec
从熵不变性看Attention的Scale操作
By 苏剑林 | 2021-12-21 | 127845位读者 | 引用当前Transformer架构用的最多的注意力机制,全称为“Scaled Dot-Product Attention”,其中“Scaled”是因为在$Q,K$转置相乘之后还要除以一个$\sqrt{d}$再做Softmax(下面均不失一般性地假设$Q,K,V\in\mathbb{R}^{n\times d}$):
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{QK^{\top}}{\sqrt{d}}\right)V\label{eq:std}\end{equation}
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经初步解释了除以$\sqrt{d}$的缘由。而在这篇文章中,笔者将从“熵不变性”的角度来理解这个缩放操作,并且得到一个新的缩放因子。在MLM的实验显示,新的缩放因子具有更好的长度外推性能。
熵不变性
我们将一般的Scaled Dot-Product Attention改写成
\begin{equation}\boldsymbol{o}_i = \sum_{j=1}^n a_{i,j}\boldsymbol{v}_j,\quad a_{i,j}=\frac{e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}{\sum\limits_{j=1}^n e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}\end{equation}
其中$\lambda$是缩放因子,它跟$\boldsymbol{q}_i,\boldsymbol{k}_j$无关,但原则上可以跟长度$n$、维度$d$等参数有关,目前主流的就是$\lambda=1/\sqrt{d}$。
11
Mar
门控注意力单元(GAU)还需要Warmup吗?
By 苏剑林 | 2022-03-11 | 48425位读者 | 引用在文章《训练1000层的Transformer究竟有什么困难?》发布之后,很快就有读者问到如果将其用到《FLASH:可能是近来最有意思的高效Transformer设计》中的“门控注意力单元(GAU)”,那结果是怎样的?跟标准Transformer的结果有何不同?本文就来讨论这个问题。
先说结论
事实上,GAU是非常容易训练的模型,哪怕我们不加调整地直接使用“Post Norm + Xavier初始化”,也能轻松训练个几十层的GAU,并且还不用Warmup。所以关于标准Transformer的很多训练技巧,到了GAU这里可能就无用武之地了...
为什么GAU能做到这些?很简单,因为在默认设置之下,理论上$\text{GAU}(\boldsymbol{x}_l)$相比$\boldsymbol{x}_l$几乎小了两个数量级,所以
\begin{equation}\boldsymbol{x}_{l+1} = \text{LN}(\boldsymbol{x}_l + \text{GAU}(\boldsymbol{x}_l))\approx \boldsymbol{x}_l\end{equation}
21
Mar
RoFormerV2:自然语言理解的极限探索
By 苏剑林 | 2022-03-21 | 64113位读者 | 引用大概在1年前,我们提出了旋转位置编码(RoPE),并发布了对应的预训练模型RoFormer。随着时间的推移,RoFormer非常幸运地得到了越来越多的关注和认可,比如EleutherAI新发布的60亿和200亿参数的GPT模型中就用上了RoPE位置编码,Google新提出的FLASH模型论文中则明确指出了RoPE对Transformer效果有明显的提升作用。
与此同时,我们也一直在尝试继续加强RoFormer模型,试图让RoFormer的性能“更上一层楼”。经过近半年的努力,我们自认为取得了还不错的成果,因此将其作为“RoFormerV2”正式发布:
关于站长
智能搜索
支持整句搜索!网站自动使用结巴分词进行分词,并结合ngrams排序算法给出合理的搜索结果。

最近评论