






23
May
NBCE:使用朴素贝叶斯扩展LLM的Context处理长度
By 苏剑林 | 2023-05-23 | 96003位读者 | 引用在LLM时代还玩朴素贝叶斯(Naive Bayes)?
这可能是许多读者在看到标题后的首个想法。确实如此,当古老的朴素贝叶斯与前沿的LLM相遇时,产生了令人惊讶的效果——我们可以直接扩展现有LLM模型的Context处理长度,无需对模型进行微调,也不依赖于模型架构,具有线性效率,而且效果看起来还不错——这就是本文所提出的NBCE(Naive Bayes-based Context Extension)方法。
摸石过河
假设$T$为要生成的token序列,$S_1,S_2,\cdots,S_n$是给定的若干个相对独立的Context集合(比如$n$个不同的段落,至少不是一个句子被分割为两个片段那种),假设它们的总长度已经超过了训练长度,而单个$S_k$加$T$还在训练长度内。我们需要根据$S_1,S_2,\cdots,S_n$生成$T$,即估计$p(T|S_1, S_2,\cdots,S_n)$。
26
Jan
Transformer升级之路:16、“复盘”长度外推技术
By 苏剑林 | 2024-01-26 | 97607位读者 | 引用回过头来看,才发现从第7篇《Transformer升级之路:7、长度外推性与局部注意力》开始,“Transformer升级之路”这个系列就跟长度外推“杠”上了,接连9篇文章(不算本文)都是围绕长度外推展开的。如今,距离第7篇文章刚好是一年多一点,在这一年间,开源社区关于长度外推的研究有了显著进展,笔者也逐渐有了一些自己的理解,比如其实这个问题远不像一开始想象那么简单,以往很多基于局部注意力的工作也不总是有效,这暗示着很多旧的分析工作并没触及问题的核心。
在这篇文章中,笔者尝试结合自己的发现和认识,去“复盘”一下主流的长度外推结果,并试图从中发现免训练长度外推的关键之处。
问题定义
顾名思义,免训练长度外推,就是不需要用长序列数据进行额外的训练,只用短序列语料对模型进行训练,就可以得到一个能够处理和预测长序列的模型,即“Train Short, Test Long”。那么如何判断一个模型能否用于长序列呢?最基本的指标就是模型的长序列Loss或者PPL不会爆炸,更加符合实践的评测则是输入足够长的Context,让模型去预测答案,然后跟真实答案做对比,算BLEU、ROUGE等,LongBench就是就属于这类榜单。
18
Mar
时空之章:将Attention视为平方复杂度的RNN
By 苏剑林 | 2024-03-18 | 56822位读者 | 引用近年来,RNN由于其线性的训练和推理效率,重新吸引了不少研究人员和用户的兴趣,隐约有“文艺复兴”之势,其代表作有RWKV、RetNet、Mamba等。当将RNN用于语言模型时,其典型特点就是每步生成都是常数的空间复杂度和时间复杂度,从整个序列看来就是常数的空间复杂度和线性的时间复杂度。当然,任何事情都有两面性,相比于Attention动态增长的KV Cache,RNN的常数空间复杂度通常也让人怀疑记忆容量有限,在Long Context上的效果很难比得上Attention。
在这篇文章中,我们表明Causal Attention可以重写成RNN的形式,并且它的每一步生成理论上也能够以$\mathcal{O}(1)$的空间复杂度进行(代价是时间复杂度非常高,远超平方级)。这表明Attention的优势(如果有的话)是靠计算堆出来的,而不是直觉上的堆内存,它跟RNN一样本质上都是常数量级的记忆容量(记忆瓶颈)。
23
Apr
生成扩散模型漫谈(二十四):少走捷径,更快到达
By 苏剑林 | 2024-04-23 | 38571位读者 | 引用如何减少采样步数同时保证生成质量,是扩散模型应用层面的一个关键问题。其中,《生成扩散模型漫谈(四):DDIM = 高观点DDPM》介绍的DDIM可谓是加速采样的第一次尝试。后来,《生成扩散模型漫谈(五):一般框架之SDE篇》、《生成扩散模型漫谈(五):一般框架之ODE篇》等所介绍的工作将扩散模型与SDE、ODE联系了起来,于是相应的数值积分技术也被直接用于扩散模型的采样加速,其中又以相对简单的ODE加速技术最为丰富,我们在《生成扩散模型漫谈(二十一):中值定理加速ODE采样》也介绍过一例。
这篇文章我们介绍另一个特别简单有效的加速技巧——Skip Tuning,出自论文《The Surprising Effectiveness of Skip-Tuning in Diffusion Sampling》,准确来说它是配合已有的加速技巧使用,来一步提高采样质量,这就意味着在保持相同采样质量的情况下,它可以进一步压缩采样步数,从而实现加速。
24
Jul
Monarch矩阵:计算高效的稀疏型矩阵分解
By 苏剑林 | 2024-07-24 | 31883位读者 | 引用在矩阵压缩这个问题上,我们通常有两个策略可以选择,分别是低秩化和稀疏化。低秩化通过寻找矩阵的低秩近似来减少矩阵尺寸,而稀疏化则是通过减少矩阵中的非零元素来降低矩阵的复杂性。如果说SVD是奔着矩阵的低秩近似去的,那么相应地寻找矩阵稀疏近似的算法又是什么呢?
接下来我们要学习的是论文《Monarch: Expressive Structured Matrices for Efficient and Accurate Training》,它为上述问题给出了一个答案——“Monarch矩阵”,这是一簇能够分解为若干置换矩阵与稀疏矩阵乘积的矩阵,同时具备计算高效且表达能力强的特点,论文还讨论了如何求一般矩阵的Monarch近似,以及利用Monarch矩阵参数化LLM来提高LLM速度等内容。
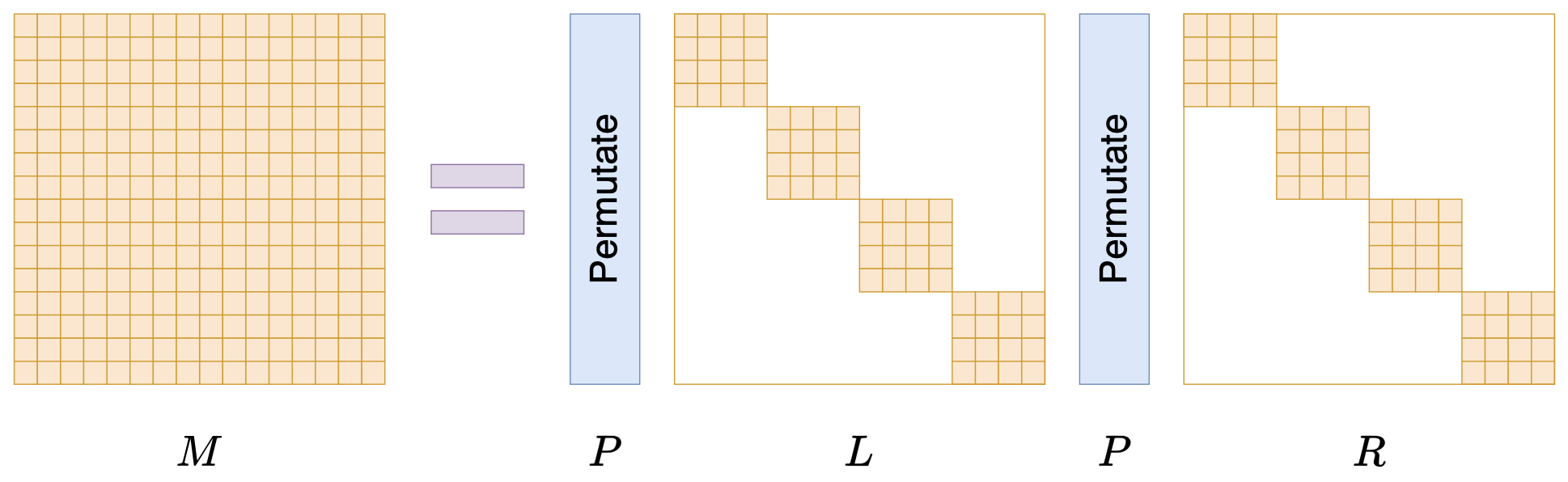
Monarch矩阵形式M=PLPR
值得指出的是,该论文的作者也正是著名的Flash Attention的作者Tri Dao,其工作几乎都在致力于改进LLM的性能,这篇Monarch也是他主页上特意展示的几篇论文之一,单从这一点看就非常值得学习一番。
13
Mar
初探muP:超参数的跨模型尺度迁移规律
By 苏剑林 | 2025-03-13 | 11429位读者 | 引用众所周知,完整训练一次大型LLM的成本是昂贵的,这就决定了我们不可能直接在大型LLM上反复测试超参数。一个很自然的想法是希望可以在同结构的小模型上仔细搜索超参数,找到最优组合后直接迁移到大模型上。尽管这个想法很朴素,但要实现它并不平凡,它需要我们了解常见的超参数与模型尺度之间的缩放规律,而muP正是这个想法的一个实践。
muP,有时也写$\mu P$,全名是Maximal Update Parametrization,出自论文《Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer》,随着LLM训练的普及,它逐渐已经成为了科学炼丹的事实标配之一。
方法大意
在接入主题之前,必须先吐槽一下muP原论文写得实在太过晦涩,并且结论的表达也不够清晰,平白增加了不少理解难度,所以接下来笔者尽量以一种(自认为)简明扼要的方式来复现muP的结论。

最近评论