






20
Aug
开源一版DGCNN阅读理解问答模型(Keras版)
By 苏剑林 | 2019-08-20 | 79241位读者 | 引用去年写过《基于CNN的阅读理解式问答模型:DGCNN》,介绍了一个纯卷积的简单的问答模型。当时是用Tensorflow实现的,而且没有开源,这几天抽空用Keras复现了一下,决定开源。
模型综述
关于DGCNN的基本介绍,这里不再赘述。本文的模型并不是之前模型的重复实现,而是有所改动,这里只介绍一下被改动的地方。
1、这里放出的模型,线下验证集的分数大概是0.72(之前大约是0.75);
2、本次模型以字为单位,使用笔者之前探索出来的“字词混合Embedding”(之前是以词为单位);
3、本次模型完全去掉了人工特征(之前用了8个人工特征);
4、本次模型去掉了位置Embedding(之前将位置Embedding拼接到输入上);
5、模型架构和训练细节有所微调。
29
Apr
节省显存的重计算技巧也有了Keras版了
By 苏剑林 | 2020-04-29 | 53673位读者 | 引用不少读者最近可能留意到了公众号文章《BERT重计算:用22.5%的训练时间节省5倍的显存开销(附代码)》,里边介绍了一个叫做“重计算”的技巧,简单来说就是用来省显存的方法,让平均训练速度慢一点,但batch_size可以增大好几倍。该技巧首先发布于论文《Training Deep Nets with Sublinear Memory Cost》,其实在2016年就已经提出了,只不过似乎还没有特别流行起来。
探索
公众号文章提到该技巧在pytorch和paddlepaddle都有原生实现了,但tensorflow还没有。但事实上从tensorflow 1.8开始,tensorflow就已经自带了该功能了,当时被列入了tf.contrib这个子库中,而从tensorflow 1.15开始,它就被内置为tensorflow的主函数之一,那就是tf.recompute_grad。
找到tf.recompute_grad之后,笔者就琢磨了一下它的用法,经过一番折腾,最终居然真的成功地用起来了,居然成功地让batch_size从48增加到了144!然而,在继续整理测试的过程中,发现这玩意居然在tensorflow 2.x是失效的...于是再折腾了两天,查找了各种资料并反复调试,最终算是成功地补充了这一缺陷。
最后是笔者自己的开源实现:
该实现已经内置在bert4keras中,使用bert4keras的读者可以升级到最新版本(0.7.5+)来测试该功能。
31
Oct
bert4keras在手,baseline我有:CLUE基准代码
By 苏剑林 | 2021-10-31 | 87084位读者 | 引用CLUE(Chinese GLUE)是中文自然语言处理的一个评价基准,目前也已经得到了较多团队的认可。CLUE官方Github提供了tensorflow和pytorch的baseline,但并不易读,而且也不方便调试。事实上,不管是tensorflow还是pytorch,不管是CLUE还是GLUE,笔者认为能找到的baseline代码,都很难称得上人性化,试图去理解它们是一件相当痛苦的事情。
所以,笔者决定基于bert4keras实现一套CLUE的baseline。经过一段时间的测试,基本上复现了官方宣称的基准成绩,并且有些任务还更优。最重要的是,所有代码尽量保持了清晰易读的特点,真·“Deep Learning for Humans”。
代码简介
下面简单介绍一下该代码中各个任务baseline的构建思路。在阅读文章和代码之前,请读者自行先观察一下每个任务的数据格式,这里不对任务数据进行详细介绍。
16
Mar
现在可以用Keras玩中文GPT2了(GPT2_ML)
By 苏剑林 | 2020-03-16 | 102961位读者 | 引用前段时间留意到有大牛开源了一个中文的GPT2模型,是最大的15亿参数规模的,看作者给的demo,生成效果还是蛮惊艳的,就想着加载到自己的bert4keras来玩玩。不过早期的bert4keras整体架构写得比较“死”,集成多个不同的模型很不方便。前两周终于看不下去了,把bert4keras的整体结构重写了一遍,现在的bert4keras总能算比较灵活地编写各种Transformer结构的模型了,比如GPT2、T5等都已经集成在里边了。
GPT2科普
GPT,相信很多读者都听说过它了,简单来说,它就是一个基于Transformer结构的语言模型,源自论文《GPT:Improving Language Understanding by Generative Pre-Training》,但它又不是为了做语言模型而生,它是通过语言模型来预训练自身,然后在下游任务微调,提高下游任务的表现。它是“Transformer + 预训练 + 微调”这种模式的先驱者,相对而言,BERT都算是它的“后辈”,而GPT2,则是GPT的升级版——模型更大,训练数据更多——模型最大版的参数量达到了15亿。
19
Dec
让炼丹更科学一些(一):SGD的平均损失收敛
By 苏剑林 | 2023-12-19 | 40271位读者 | 引用很多时候我们将深度学习模型的训练过程戏称为“炼丹”,因为整个过程跟古代的炼丹术一样,看上去有一定的科学依据,但整体却给人一种“玄之又玄”的感觉。尽管本站之前也关注过一些优化器相关的工作,甚至也写过《从动力学角度看优化算法》系列,但都是比较表面的介绍,并没有涉及到更深入的理论。为了让以后的炼丹更科学一些,笔者决定去补习一些优化相关的理论结果,争取让炼丹之路多点理论支撑。
在本文中,我们将学习随机梯度下降(SGD)的一个非常基础的收敛结论。虽然现在看来,该结论显得很粗糙且不实用,但它是优化器收敛性证明的一次非常重要的尝试,特别是它考虑了我们实际使用的是随机梯度下降(SGD)而不是全量梯度下降(GD)这一特性,使得结论更加具有参考意义。
问题设置
设损失函数是$L(\boldsymbol{x},\boldsymbol{\theta})$,其实$\boldsymbol{x}$是训练集,而$\boldsymbol{\theta}\in\mathbb{R}^d$是训练参数。受限于算力,我们通常只能执行随机梯度下降(SGD),即每步只能采样一个训练子集来计算损失函数并更新参数,假设采样是独立同分布的,第$t$步采样到的子集为$\boldsymbol{x}_t$,那么我们可以合理地认为实际优化的最终目标是
\begin{equation}L(\boldsymbol{\theta}) = \lim_{T\to\infty}\frac{1}{T}\sum_{t=1}^T L(\boldsymbol{x}_t,\boldsymbol{\theta})\label{eq:loss}\end{equation}
29
Nov
Dropout视角下的MLM和MAE:一些新的启发
By 苏剑林 | 2021-11-29 | 83645位读者 | 引用大家都知道,BERT的MLM(Masked Language Model)任务在预训练和微调时的不一致,也就是预训练出现了[MASK]而下游任务微调时没有[MASK],是经常被吐槽的问题,很多工作都认为这是影响BERT微调性能的重要原因,并针对性地提出了很多改进,如XL-NET、ELECTRA、MacBERT等。本文我们将从Dropout的角度来分析MLM的这种不一致性,并且提出一种简单的操作来修正这种不一致性。
同样的分析还可以用于何凯明最近提出的比较热门的MAE(Masked Autoencoder)模型,结果是MAE相比MLM确实具有更好的一致性,由此我们可以引出一种可以能加快训练速度的正则化手段。
Dropout
首先,我们重温一下Dropout。从数学上来看,Dropout是通过伯努利分布来为模型引入随机噪声的操作,所以我们也简单复习一下伯努利分布。
4
Dec
层次分解位置编码,让BERT可以处理超长文本
By 苏剑林 | 2020-12-04 | 139467位读者 | 引用大家都知道,目前的主流的BERT模型最多能处理512个token的文本。导致这一瓶颈的根本原因是BERT使用了从随机初始化训练出来的绝对位置编码,一般的最大位置设为了512,因此顶多只能处理512个token,多出来的部分就没有位置编码可用了。当然,还有一个重要的原因是Attention的$\mathcal{O}(n^2)$复杂度,导致长序列时显存用量大大增加,一般显卡也finetune不了。
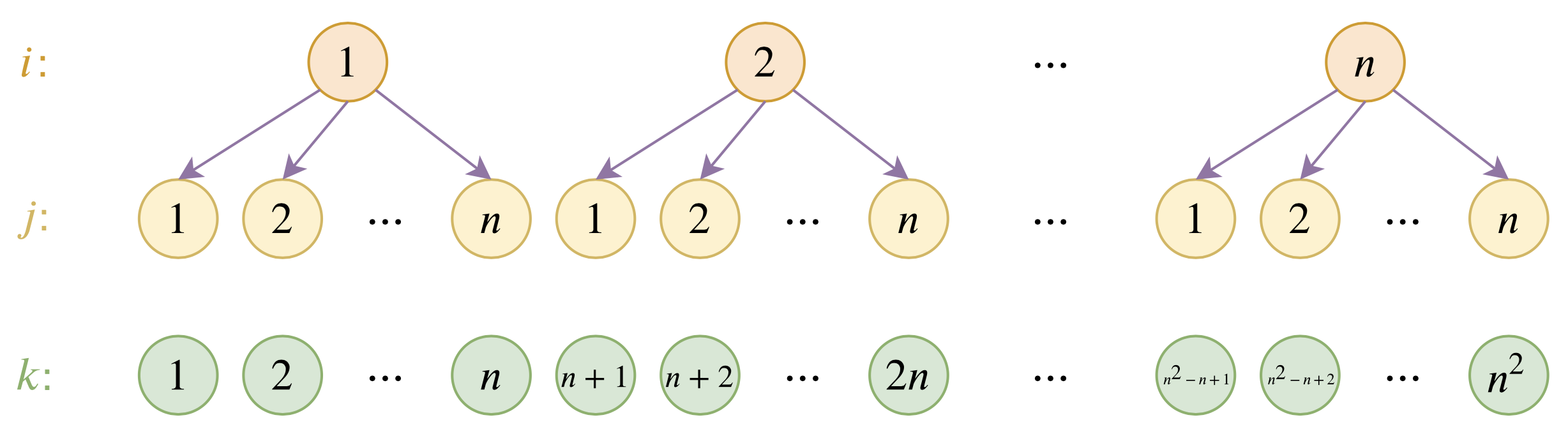
位置编码的层次分解示意图
本文主要面向前一个原因,即假设有足够多的显存前提下,如何简单修改当前最大长度为512的BERT模型,使得它可以直接处理更长的文本,主要思路是层次分解已经训练好的绝对位置编码,使得它可以延拓到更长的位置。
27
Oct
TeaForN:让Teacher Forcing更有“远见”一些
By 苏剑林 | 2020-10-27 | 45486位读者 | 引用Teacher Forcing是Seq2Seq模型的经典训练方式,而Exposure Bias则是Teacher Forcing的经典缺陷,这对于搞文本生成的同学来说应该是耳熟能详的事实了。笔者之前也曾写过博文《Seq2Seq中Exposure Bias现象的浅析与对策》,初步地分析过Exposure Bias问题。
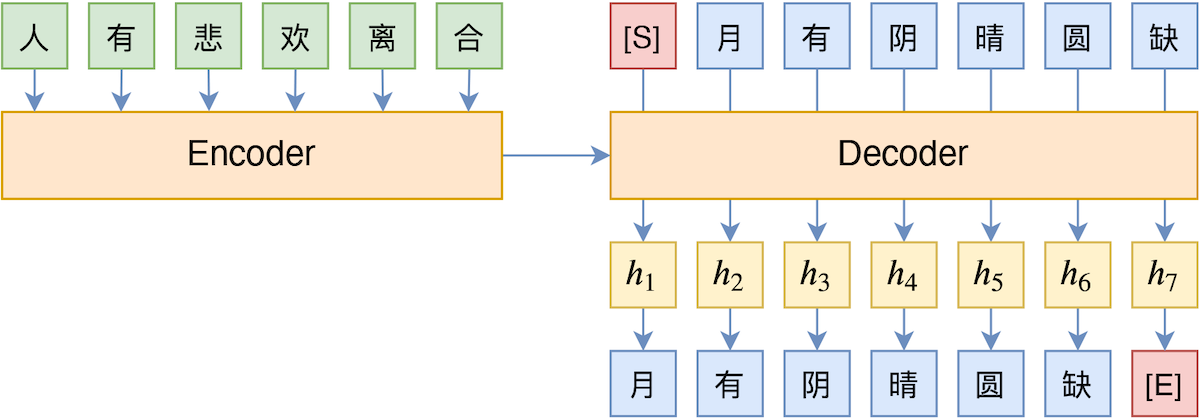
Teacher Forcing示意图
本文则介绍Google新提出的一种名为“TeaForN”的缓解Exposure Bias现象的方案,来自论文《TeaForN: Teacher-Forcing with N-grams》,它通过嵌套迭代的方式,让模型能提前预估到后$N$个token(而不仅仅是当前要预测的token),其处理思路上颇有可圈可点之处,值得我们学习。
(注:为了尽量跟本博客旧文章保持一致,本文的记号与原论文的记号有所不同,请大家以理解符号含义为主,不要强记符号形式。)

最近评论