






12
Aug
生成扩散模型漫谈(七):最优扩散方差估计(上)
By 苏剑林 | 2022-08-12 | 85426位读者 | 引用对于生成扩散模型来说,一个很关键的问题是生成过程的方差应该怎么选择,因为不同的方差会明显影响生成效果。
在《生成扩散模型漫谈(二):DDPM = 自回归式VAE》我们提到,DDPM分别假设数据服从两种特殊分布推出了两个可用的结果;《生成扩散模型漫谈(四):DDIM = 高观点DDPM》中的DDIM则调整了生成过程,将方差变为超参数,甚至允许零方差生成,但方差为0的DDIM的生成效果普遍差于方差非0的DDPM;而《生成扩散模型漫谈(五):一般框架之SDE篇》显示前、反向SDE的方差应该是一致的,但这原则上在$\Delta t\to 0$时才成立;《Improved Denoising Diffusion Probabilistic Models》则提出将它视为可训练参数来学习,但会增加训练难度。
所以,生成过程的方差究竟该怎么设置呢?今年的两篇论文《Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models》和《Estimating the Optimal Covariance with Imperfect Mean in Diffusion Probabilistic Models》算是给这个问题提供了比较完美的答案。接下来我们一起欣赏一下它们的结果。
16
Feb
Google新搜出的优化器Lion:效率与效果兼得的“训练狮”
By 苏剑林 | 2023-02-16 | 55812位读者 | 引用昨天在Arixv上发现了Google新发的一篇论文《Symbolic Discovery of Optimization Algorithms》,主要是讲自动搜索优化器的,咋看上去没啥意思,因为类似的工作也有不少,大多数结果都索然无味。然而,细读之下才发现别有洞天,原来作者们通过数千TPU小时的算力搜索并结合人工干预,得到了一个速度更快、显存更省的优化器Lion(EvoLved Sign Momentum,不得不吐槽这名字起得真勉强),并在图像分类、图文匹配、扩散模型、语言模型预训练和微调等诸多任务上做了充分的实验,多数任务都显示Lion比目前主流的AdamW等优化器有着更好的效果。
更省显存还更好效果,真可谓是鱼与熊掌都兼得了,什么样的优化器能有这么强悍的性能?本文一起来欣赏一下论文的成果。
先说结果
本文主要关心搜索出来的优化器本身,所以关于搜索过程的细节就不讨论了,对此有兴趣读者自行看原论文就好。Lion优化器的更新过程为
\begin{equation}\text{Lion}:=\left\{\begin{aligned}
&\boldsymbol{u}_t = \text{sign}\big(\beta_1 \boldsymbol{m}_{t-1} + \left(1 - \beta_1\right) \boldsymbol{g}_t\big) \\
&\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t (\boldsymbol{u}_t \color{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}}) \\
&\boldsymbol{m}_t = \beta_2 \boldsymbol{m}_{t-1} + \left(1 - \beta_2\right) \boldsymbol{g}_t
\end{aligned}\right.\end{equation}
7
Mar
Tiger:一个“抠”到极致的优化器
By 苏剑林 | 2023-03-07 | 49580位读者 | 引用这段时间笔者一直在实验《Google新搜出的优化器Lion:效率与效果兼得的“训练狮”》所介绍的Lion优化器。之所以对Lion饶有兴致,是因为它跟笔者之前的关于理想优化器的一些想法不谋而合,但当时笔者没有调出好的效果,而Lion则做好了。
相比标准的Lion,笔者更感兴趣的是它在$\beta_1=\beta_2$时的特殊例子,这里称之为“Tiger”。Tiger只用到了动量来构建更新量,根据《隐藏在动量中的梯度累积:少更新几步,效果反而更好?》的结论,此时我们不新增一组参数来“无感”地实现梯度累积!这也意味着在我们有梯度累积需求时,Tiger已经达到了显存占用的最优解,这也是“Tiger”这个名字的来源(Tight-fisted Optimizer,抠门的优化器,不舍得多花一点显存)。
此外,Tiger还加入了我们的一些超参数调节经验,以及提出了一个防止模型出现NaN(尤其是混合精度训练下)的简单策略。我们的初步实验显示,Tiger的这些改动,能够更加友好地完成模型(尤其是大模型)的训练。
21
Feb
“闭门造车”之多模态思路浅谈(一):无损输入
By 苏剑林 | 2024-02-21 | 165020位读者 | 引用这篇文章分享一下笔者关于多模态模型架构的一些闭门造车的想法,或者说一些猜测。
最近Google的Gemini 1.5和OpenAI的Sora再次点燃了不少人对多模态的热情,只言片语的技术报告也引起了大家对其背后模型架构的热烈猜测。不过,本文并非是为了凑这个热闹才发出来的,事实上其中的一些思考由来已久,最近才勉强捋顺了一下,遂想写出来跟大家交流一波,刚好碰上了两者的发布。
事先声明,“闭门造车”一词并非自谦,笔者的大模型实践本就“乏善可陈”,而多模态实践更是几乎“一片空白”,本文确实只是根据以往文本生成和图像生成的一些经验所做的“主观臆测”。
问题背景
首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗?
13
Aug
两个惊艳的python库:tqdm和retry
By 苏剑林 | 2016-08-13 | 69142位读者 | 引用Python基本是我目前工作、计算、数据挖掘的唯一编程语言(除了符号计算用Mathematica外)。当然,基本的Python功能并不是很强大,但它胜在有巨量的第三方扩展库。在选用Python的第三方库时,我都会经过仔细考虑,希望能挑选出最简单的、最直观的一个(因为本人比较笨,太复杂用不了)。在数据处理方面,我用得最多的是Numpy和Pandas,这两个绝对称得上王者级别的库,当然不能不提的是Scipy,但我很少直接用它,一般会通过Pandas间接调用了;可视化方面不用说是Matplotlib了;在建模方面,我会用Keras,直接上深度学习模型,Keras已经成为相当流行的深度学习框架了,如果做文本挖掘,通常还会用到jieba(分词)、Gensim(主题建模,包含了诸如word2vec之类的模型),机器学习库还有流行的Scikit Learn,但我很少用;网络方面,写爬虫我用requests,这是个人性化的网络库,如果写网站,我会用bottle,这是个单文件版的迷你框架,一切由自己定义,当然,我也不会去写什么大型网站,我就写一个简单的的接口那样而已;最后如果要并行的话,一般直接用multiprocessing。
不过,以上都不是本文要推荐的,本文要推荐的是两个可以渗透到日常写代码的库,它实现了我们平时很多时候都需要的功能,但是不用增加什么代码,绝对让人眼前一亮。
24
Jul
基于Xception的腾讯验证码识别(样本+代码)
By 苏剑林 | 2017-07-24 | 96674位读者 | 引用去年的时候,有幸得到网友提供的一批腾讯验证码样本,因此也研究了一下,过程记录在《端到端的腾讯验证码识别(46%正确率)》中。
后来,这篇文章引起了不少读者的兴趣,有求样本的,有求模型的,有一起讨论的,让我比较意外。事实上,原来的模型做得比较粗糙,尤其是准确率难登大雅之台,参考价值不大。这几天重新折腾了一下,弄了个准确率高一点的模型,同时也把样本公开给大家。
模型的思路跟《端到端的腾讯验证码识别(46%正确率)》是一样的,只不过把CNN部分换成了现成的Xception结构,当然,读者也可以换VGG、Resnet50等玩玩,事实上对验证码识别来说,这些模型都能够胜任。我挑选Xception,是因为它层数不多,模型权重也较小,我比较喜欢而已。
代码
22
Feb
巧断梯度:单个loss实现GAN模型
By 苏剑林 | 2019-02-22 | 47964位读者 | 引用我们知道普通的模型都是搭好架构,然后定义好loss,直接扔给优化器训练就行了。但是GAN不一样,一般来说它涉及有两个不同的loss,这两个loss需要交替优化。现在主流的方案是判别器和生成器都按照1:1的次数交替训练(各训练一次,必要时可以给两者设置不同的学习率,即TTUR),交替优化就意味我们需要传入两次数据(从内存传到显存)、执行两次前向传播和反向传播。
如果我们能把这两步合并起来,作为一步去优化,那么肯定能节省时间的,这也就是GAN的同步训练。
(注:本文不是介绍新的GAN,而是介绍GAN的新写法,这只是一道编程题,不是一道算法题~)
如果在TF中
10
Jun
无监督分词和句法分析!原来BERT还可以这样用
By 苏剑林 | 2020-06-10 | 90175位读者 | 引用BERT的一般用法就是加载其预训练权重,再接一小部分新层,然后在下游任务上进行finetune,换句话说一般的用法都是有监督训练的。基于这个流程,我们可以做中文的分词、NER甚至句法分析,这些想必大家就算没做过也会有所听闻。但如果说直接从预训练的BERT(不finetune)就可以对句子进行分词,甚至析出其句法结构出来,那应该会让人感觉到意外和有趣了。
本文介绍ACL 2020的论文《Perturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT》,里边提供了直接利用Masked Language Model(MLM)来分析和解释BERT的思路,而利用这种思路,我们可以无监督地做到分词甚至句法分析。
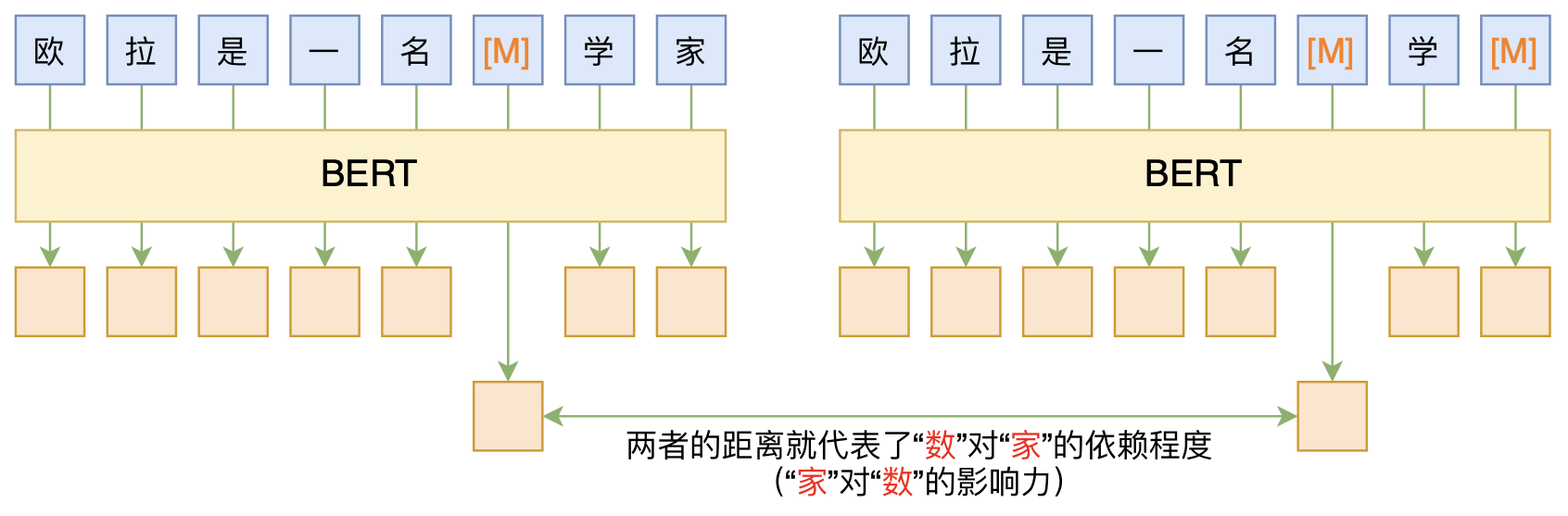
基于BERT的“token-token”相关度计算图示

最近评论