






13
Nov
也来谈谈RNN的梯度消失/爆炸问题
By 苏剑林 | 2020-11-13 | 96463位读者 | 引用尽管Transformer类的模型已经攻占了NLP的多数领域,但诸如LSTM、GRU之类的RNN模型依然在某些场景下有它的独特价值,所以RNN依然是值得我们好好学习的模型。而对于RNN梯度的相关分析,则是一个从优化角度思考分析模型的优秀例子,值得大家仔细琢磨理解。君不见,诸如“LSTM为什么能解决梯度消失/爆炸”等问题依然是目前流行的面试题之一...
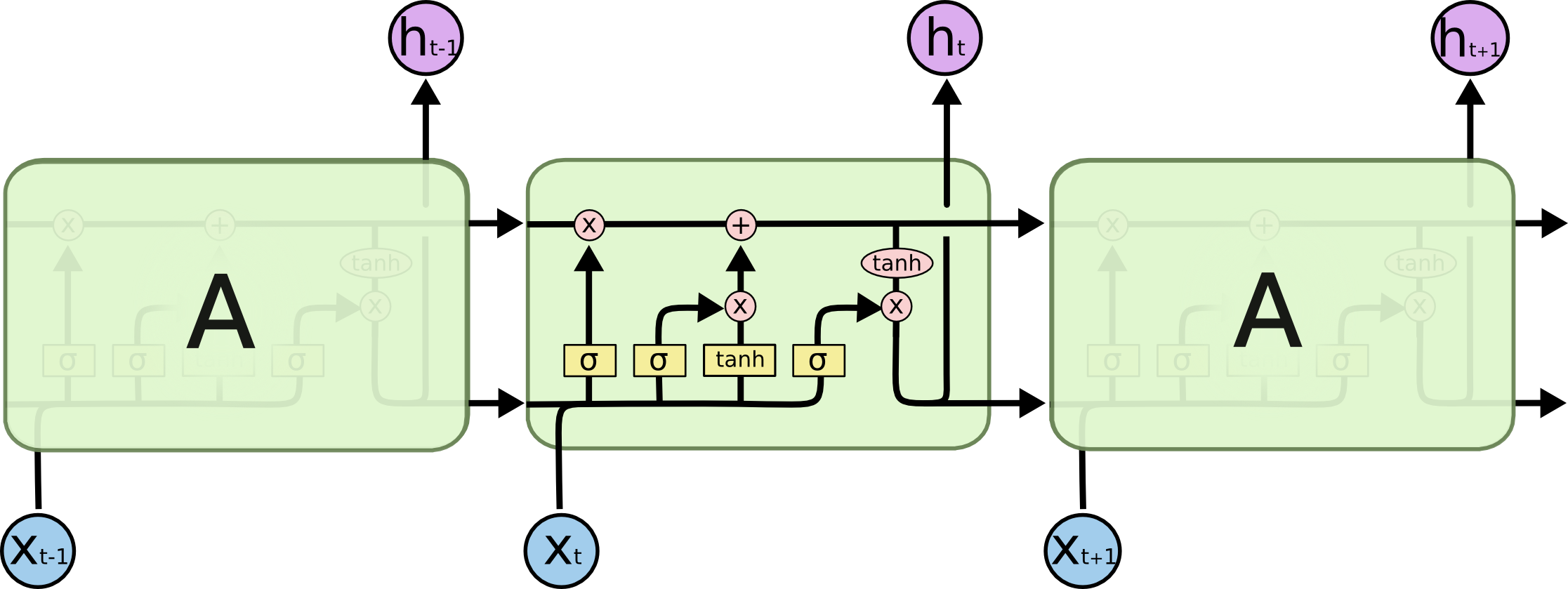
经典的LSTM
关于此类问题,已有不少网友做出过回答,然而笔者查找了一些文章(包括知乎上的部分回答、专栏以及经典的英文博客),发现没有找到比较好的答案:有些推导记号本身就混乱不堪,有些论述过程没有突出重点,整体而言感觉不够清晰自洽。为此,笔者也尝试给出自己的理解,供大家参考。
20
Nov
跟风玩玩目前最大的中文GPT2模型(bert4keras)
By 苏剑林 | 2020-11-20 | 76560位读者 | 引用相信不少读者这几天都看到了清华大学与智源人工智能研究院一起搞的“清源计划”(相关链接《中文版GPT-3来了?智源研究院发布清源 CPM —— 以中文为核心的大规模预训练模型》),里边开源了目前最大的中文GPT2模型CPM-LM(26亿参数),据说未来还会开源200亿甚至1000亿参数的模型,要打造“中文界的GPT3”。

官方给出的CPM-LM的Few Shot效果演示图
我们知道,GPT3不需要finetune就可以实现Few Shot,而目前CPM-LM的演示例子中,Few Shot的效果也是相当不错的,让人跃跃欲试,笔者也不例外。既然要尝试,肯定要将它适配到自己的bert4keras中才顺手,于是适配工作便开始了。本以为这是一件很轻松的事情,谁知道踩坑踩了快3天才把它搞好,在此把踩坑与测试的过程稍微记录一下。
24
Nov
exp(x)在x=0处的偶次泰勒展开式总是正的
By 苏剑林 | 2020-11-24 | 37888位读者 | 引用刚看到一个有意思的结论:
对于任意实数$x$及偶数$n$,总有$\sum\limits_{k=0}^n \frac{x^k}{k!} > 0$,即$e^x$在$x=0$处的偶次泰勒展开式总是正的。
下面我们来看一下这个结论的证明,以及它在寻找softmax替代品中的应用。
证明过程
看上去这是一个很强的结果,证明会不会很复杂?其实证明非常简单,记
\begin{equation}f_n(x) = \sum\limits_{k=0}^n \frac{x^k}{k!}\end{equation}
当$n$是偶数时,我们有$\lim\limits_{x\to\pm\infty} f_n(x)=+\infty$,即整体是开口向上的,所以我们只需要证明它的最小值大于0就行了,又因为它是一个光滑连续的多项式函数,所以最小值点必然是某个极小值点。那么换个角度想,我们只需要证明它所有的极值点(不管是极大还是极小)所对应的函数值都大于0。
1
Dec
Performer:用随机投影将Attention的复杂度线性化
By 苏剑林 | 2020-12-01 | 88650位读者 | 引用Attention机制的$\mathcal{O}(n^2)$复杂度是一个老大难问题了,改变这一复杂度的思路主要有两种:一是走稀疏化的思路,比如我们以往介绍过的Sparse Attention以及Google前几个月搞出来的Big Bird,等等;二是走线性化的思路,这部分工作我们之前总结在《线性Attention的探索:Attention必须有个Softmax吗?》中,读者可以翻看一下。本文则介绍一项新的改进工作Performer,出自Google的文章《Rethinking Attention with Performers》,它的目标相当霸气:通过随机投影,在不损失精度的情况下,将Attention的复杂度线性化。
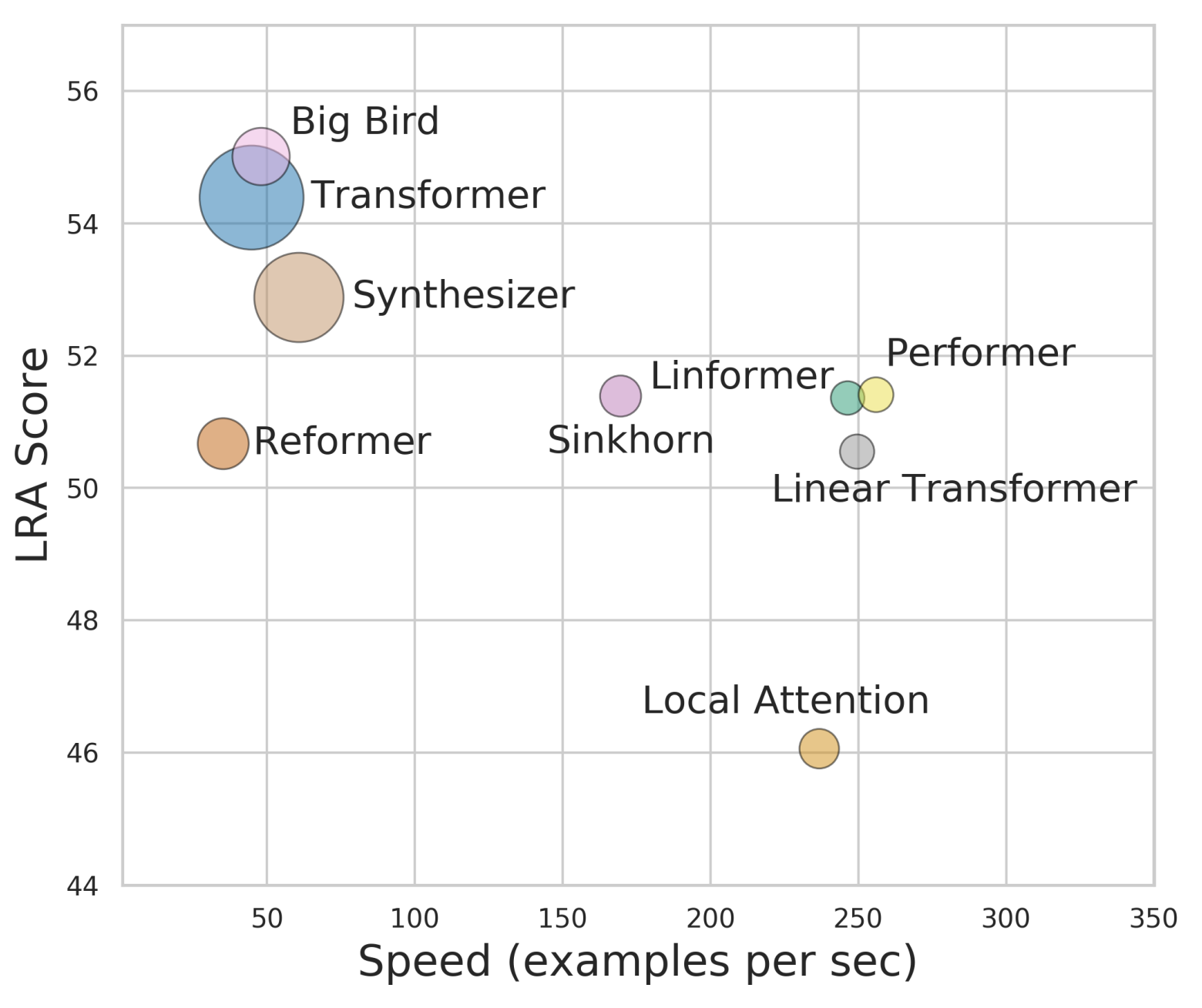
各个Transformer模型的“效果-速度-显存”图,纵轴是效果,横轴是速度,圆圈的大小代表所需要的显存。理论上来说,越靠近右上方的模型越好,圆圈越小的模型越好
说直接点,就是理想情况下我们可以不用重新训练模型,输出结果也不会有明显变化,但是复杂度降到了$\mathcal{O}(n)$!看起来真的是“天上掉馅饼”般的改进了,真的有这么美好吗?
7
Dec
【龟鱼记】全陶粒的同程底滤生态缸
By 苏剑林 | 2020-12-07 | 62017位读者 | 引用
14
Dec
Mitchell近似:乘法变为加法,误差不超过1/9
By 苏剑林 | 2020-12-14 | 43229位读者 | 引用今天给大家介绍一篇1962年的论文《Computer Multiplication and Division Using Binary Logarithms》,作者是John N. Mitchell,他在里边提出了一个相当有意思的算法:在二进制下,可以完全通过加法来近似完成两个数的相乘,最大误差不超过1/9。整个算法相当巧妙,更有意思的是它还有着非常简洁的编程实现,让人拍案叫绝。然而,笔者发现网上居然找不到介绍这个算法的网页,所以在此介绍一番。
你以为这只是过时的玩意?那你就错了,前不久才有人利用它发了一篇NeurIPS 2020呢!所以,确定不来了解一下吗?
21
Dec
从动力学角度看优化算法(七):SGD ≈ SVM?
By 苏剑林 | 2020-12-21 | 38919位读者 | 引用众所周知,在深度学习之前,机器学习是SVM(Support Vector Machine,支持向量机)的天下,曾经的它可谓红遍机器学习的大江南北,迷倒万千研究人员,直至今日,“手撕SVM”仍然是大厂流行的面试题之一。然而,时过境迁,当深度学习流行起来之后,第一个革的就是SVM的命,现在只有在某些特别追求效率的场景以及大厂的面试题里边,才能看到SVM的踪迹了。
峰回路转的是,最近Arxiv上的一篇论文《Every Model Learned by Gradient Descent Is Approximately a Kernel Machine》做了一个非常“霸气”的宣言:
任何由梯度下降算法学出来的模型,都是可以近似看成是一个SVM!
这结论真不可谓不“霸气”,因为它已经不只是针对深度学习了,而是只要你用梯度下降优化的,都不过是一个SVM(的近似)。笔者看了一下原论文的分析,感觉确实挺有意思也挺合理的,有助于加深我们对很多模型的理解,遂跟大家分享一下。
7
Jan
【搜出来的文本】⋅(一)从文本生成到搜索采样
By 苏剑林 | 2021-01-07 | 68776位读者 | 引用最近,笔者入了一个新坑:基于离散优化的思想做一些文本生成任务。简单来说,就是把我们要生成文本的目标量化地写下来,构建一个分布,然后搜索这个分布的最大值点或者从这个分布中进行采样,这个过程通常不需要标签数据的训练。由于语言是离散的,因此梯度下降之类的连续函数优化方法不可用,并且由于这个分布通常没有容易采样的形式,直接采样也不可行,因此需要一些特别设计的采样算法,比如拒绝采样(Rejection Sampling)、MCMC(Markov Chain Monte Carlo)、MH采样(Metropolis-Hastings Sampling)、吉布斯采样(Gibbs Sampling),等等。
有些读者可能会觉得有些眼熟,似乎回到了让人头大的学习LDA(Latent Dirichlet Allocation)的那些年?没错,上述采样算法其实也是理解LDA模型的必备基础。本文我们就来回顾这些形形色色的采样算法,它们将会出现在后面要介绍的丰富的文本生成应用中。

最近评论