






7
Mar
轻微的扰动——摄动法简介(3)
By 苏剑林 | 2013-03-07 | 41770位读者 | 引用微分方程领域大放光彩
虽然微分方程在各个计算领域都能一展才华,不过它最辉煌的光芒无疑绽放于微分方程领域,包括常微分方程和偏微分方程。海王星——“笔尖上发现的行星”——就是摄动法的著名成果,类似的还有冥王星的发现。天体力学家用一颗假设的行星的引力摄动来解释已知行星的异常运动,并由此反推未知行星的轨道。我们已不止一次提到过,一般的三体问题是混沌的,没有精确的解析解。这就要求我们考虑一些近似的方法,这样的方法发展起来就成为了摄动理论。
跟解代数方程一样,摄动法解带有小参数或者大参数的微分方程的基本思想,就是将微分方程的解表达为小参数或大参数的幂级数。当然,这是最直接的,也相当好理解,不过所求得的级数解有可能存在一些性态不好的情况,比如有时原解应该是一个周期运动,但是级数解却出现了诸如$t \sin t$的“长期项”,这是相当不利的,因此也发展出各种技巧来消除这些项。可见,摄动理论是一门应用广泛、集众家所大成的实用理论。下面我们将通过一些实际的例子来阐述这个技巧。
20
Jan
《方程与宇宙》:三体问题和它的初积分(六)
By 苏剑林 | 2011-01-20 | 67149位读者 | 引用The Three Body Problem and its Classical Integration
很多天文爱好者都已经接触到了“二体问题”(我们在高中学习到的“开普勒三定律”就是内容之一),由于在太阳系中行星质量相对较小而且距离相对较远,应用“二体问题”的解对天体进行计算、预报等能够满足一定的近似需求。不过,如果需要更高精度的计算,就不能把其他行星的引力给忽略掉了,于是就产生了所谓N体问题(N-Body Problem),即N个质点尽在它们各自引力的相互作用下的运动规律问题。最简单的二体已经被彻底解决,而三体或更多体的问题则与二体大相径庭,因为庞加莱证明了,三体问题不能严格求解,而且这是一个混沌系统,任何微小的扰动都会造成不可预期的效果。
根据牛顿力学,选择惯性参考系,设三个质点分别为$M_1,M_2,M_3$,向径分别为$\vec{r_1},\vec{r_2},\vec{r_3}$,可以列出运动方程(以下的导数都默认是对时间t求导)
23
Jun
貌离神合的RNN与ODE:花式RNN简介
By 苏剑林 | 2018-06-23 | 110313位读者 | 引用本来笔者已经决心不玩RNN了,但是在上个星期思考时忽然意识到RNN实际上对应了ODE(常微分方程)的数值解法,这为我一直以来想做的事情——用深度学习来解决一些纯数学问题——提供了思路。事实上这是一个颇为有趣和有用的结果,遂介绍一翻。顺便地,本文也涉及到了自己动手编写RNN的内容,所以本文也可以作为编写自定义的RNN层的一个简单教程。
注:本文并非前段时间的热点“神经ODE”的介绍(但有一定的联系)。
RNN基本
什么是RNN?
众所周知,RNN是“循环神经网络(Recurrent Neural Network)”,跟CNN不同,RNN可以说是一类模型的总称,而并非单个模型。简单来讲,只要是输入向量序列$(\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_T)$,输出另外一个向量序列$(\boldsymbol{y}_1,\boldsymbol{y}_2,\dots,\boldsymbol{y}_T)$,并且满足如下递归关系
$$\boldsymbol{y}_t=f(\boldsymbol{y}_{t-1}, \boldsymbol{x}_t, t)\tag{1}$$
的模型,都可以称为RNN。也正因为如此,原始的朴素RNN,还有改进的如GRU、LSTM、SRU等模型,我们都称为RNN,因为它们都可以作为上式的一个特例。还有一些看上去与RNN没关的内容,比如前不久介绍的CRF的分母的计算,实际上也是一个简单的RNN。
说白了,RNN其实就是递归计算。
13
Nov
ARXIV数学论文分布:偏微分方程最热门!
By 苏剑林 | 2015-11-13 | 33885位读者 | 引用笔者成功地保研到了中山大学的基础数学专业,这个专业自然是比较理论性的,虽然如此,我还会保持着我对数据分析、计算机等方面的兴趣。这几天兴致来了,想做一下结合我的专业跟数据挖掘相结合的研究,所以就爬取了ARXIV上面近五年(2010年到2014年)的数学论文(包含的数据有:标题、分类、年份、月份),想对这几年来数学的“行情”做一下简单的分析。个人认为,ARVIX作为目前全球最大的论文预印本的电子数据库,对它的数据进行分析,所得到的结论是能够具有一定的代表性的。
当然,本文只是用来练手爬虫和基本数据分析的文章,并没有挖掘出特别有价值的信息。文末附录了笔者爬取到的数据,供有兴趣的读者进一步分析研究。
整体情况
这五年来,ARXIV的数学论文总数为135009篇,平均每年27000篇,或者每天74篇。
12
Nov
特殊的通项公式:二次非线性递推
By 苏剑林 | 2014-11-12 | 65864位读者 | 引用特殊的通项公式
对数学或编程感兴趣的读者,相信都已经很熟悉斐波那契数列了
0, 1, 1, 2, 3, 5, 8, 13, ...
它是由
$$a_{n+2}=a_{n+1}+a_n,\quad a_0=0,a_1=1$$
递推所得。读者或许已经见过它的通项公式
$$a_{n}=\frac{\sqrt{5}}{5} \cdot \left[\left(\frac{1 + \sqrt{5}}{2}\right)^{n} - \left(\frac{1 - \sqrt{5}}{2}\right)^{n}\right]$$
这里假设我们没有如此高的智商可以求出这个复杂的表达式出来,但是我们通过研究数列发现,这个数列越来越大时,相邻两项趋于一个常数,这个常数也就是(假设我们只发现了后面的数值,并没有前面的根式)
$$\beta=\frac{1 + \sqrt{5}}{2}=1.61803398\dots$$
9
Apr
一个非线性差分方程的隐函数解
By 苏剑林 | 2016-04-09 | 44933位读者 | 引用问题来源
笔者经常学习的数学研发论坛曾有一帖讨论下述非线性差分方程的渐近求解:
$$a_{n+1}=a_n+\frac{1}{a_n^2},\, a_1=1$$
原帖子在这里,从这帖子中我获益良多,学习到了很多新技巧。主要思路是通过将两边立方,然后设$x_n=a_n^3$,变为等价的递推问题:
$$x_{n+1}=x_n+3+\frac{3}{x_n}+\frac{1}{x_n^2},\,x_1=1$$
然后可以通过巧妙的技巧得到渐近展开式:
$$x_n = 3n+\ln n+a+\frac{\frac{1}{3}(\ln n+a)-\frac{5}{18}}{n}+\dots$$
具体过程就不提了,读者可以自行到上述帖子学习。
然而,这种形式的解虽然精妙,但存在一些笔者不是很满意的地方:
1、解是渐近的级数,这就意味着实际上收敛半径为0;
2、是$n^{-k}$形式的解,对于较小的$n$难以计算,这都使得高精度计算变得比较困难;
3、当然,题目本来的目的是渐近计算,但是渐近分析似乎又没有必要展开那么多项;
4、里边带有了一个本来就比较难计算的极限值$a$;
5、求解过程似乎稍欠直观。
当然,上面这些缺点,有些是鸡蛋里挑骨头的。不过,也正是这些缺点,促使我寻找更好的形式的解,最终导致了这篇文章。
1
Dec
Performer:用随机投影将Attention的复杂度线性化
By 苏剑林 | 2020-12-01 | 90343位读者 | 引用Attention机制的$\mathcal{O}(n^2)$复杂度是一个老大难问题了,改变这一复杂度的思路主要有两种:一是走稀疏化的思路,比如我们以往介绍过的Sparse Attention以及Google前几个月搞出来的Big Bird,等等;二是走线性化的思路,这部分工作我们之前总结在《线性Attention的探索:Attention必须有个Softmax吗?》中,读者可以翻看一下。本文则介绍一项新的改进工作Performer,出自Google的文章《Rethinking Attention with Performers》,它的目标相当霸气:通过随机投影,在不损失精度的情况下,将Attention的复杂度线性化。
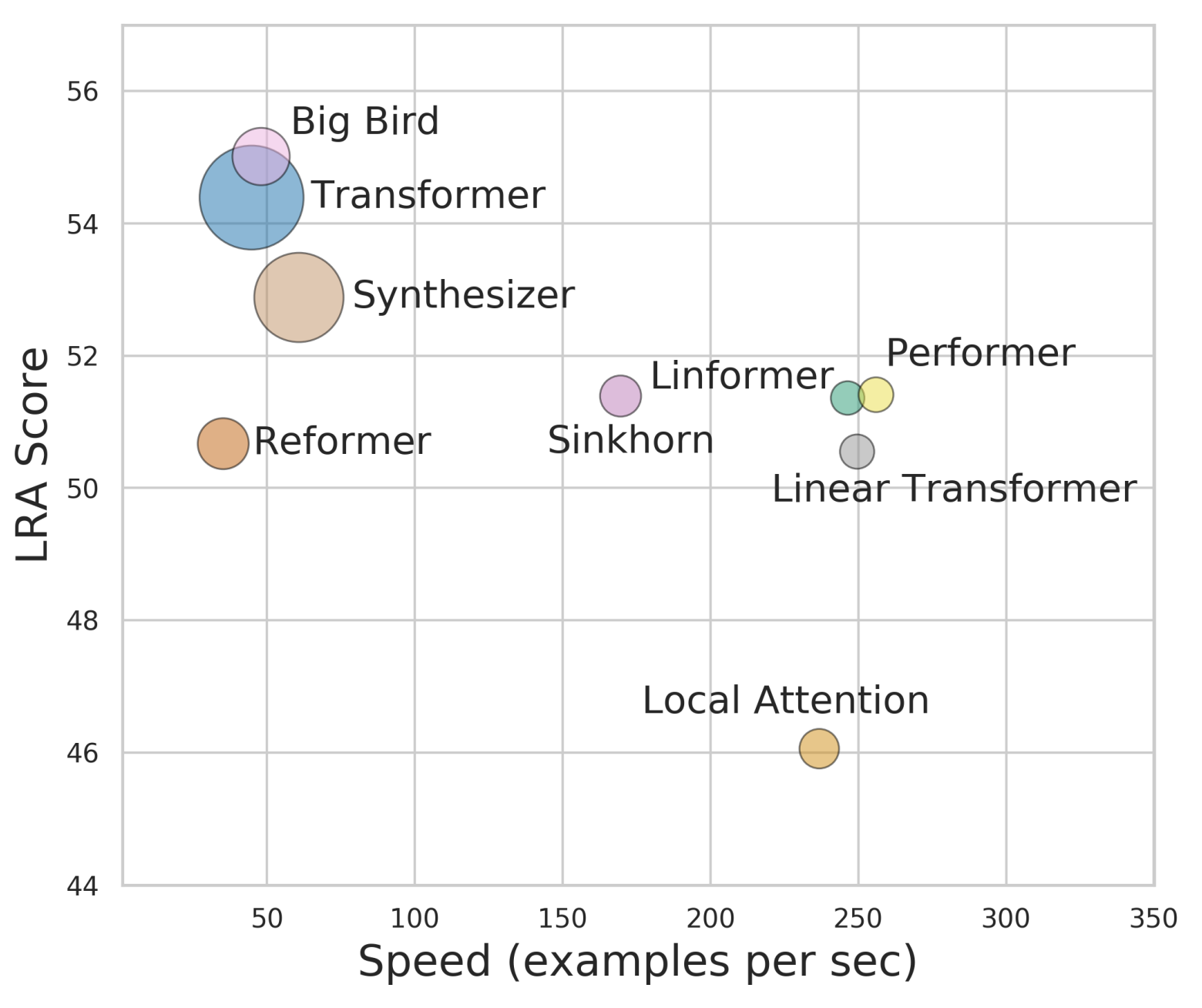
各个Transformer模型的“效果-速度-显存”图,纵轴是效果,横轴是速度,圆圈的大小代表所需要的显存。理论上来说,越靠近右上方的模型越好,圆圈越小的模型越好
说直接点,就是理想情况下我们可以不用重新训练模型,输出结果也不会有明显变化,但是复杂度降到了$\mathcal{O}(n)$!看起来真的是“天上掉馅饼”般的改进了,真的有这么美好吗?
11
Jan
你可能不需要BERT-flow:一个线性变换媲美BERT-flow
By 苏剑林 | 2021-01-11 | 230946位读者 | 引用BERT-flow来自论文《On the Sentence Embeddings from Pre-trained Language Models》,中了EMNLP 2020,主要是用flow模型校正了BERT出来的句向量的分布,从而使得计算出来的cos相似度更为合理一些。由于笔者定时刷Arixv的习惯,早在它放到Arxiv时笔者就看到了它,但并没有什么兴趣,想不到前段时间小火了一把,短时间内公众号、知乎等地出现了不少的解读,相信读者们多多少少都被它刷屏了一下。
从实验结果来看,BERT-flow确实是达到了一个新SOTA,但对于这一结果,笔者的第一感觉是:不大对劲!当然,不是说结果有问题,而是根据笔者的理解,flow模型不大可能发挥关键作用。带着这个直觉,笔者做了一些分析,果不其然,笔者发现尽管BERT-flow的思路没有问题,但只要一个线性变换就可以达到相近的效果,flow模型并不是十分关键。
余弦相似度的假设
一般来说,我们语义相似度比较或检索,都是给每个句子算出一个句向量来,然后算它们的夹角余弦来比较或者排序。那么,我们有没有思考过这样的一个问题:余弦相似度对所输入的向量提出了什么假设呢?或者说,满足什么条件的向量用余弦相似度做比较效果会更好呢?

最近评论