






10
Sep
变分自编码器(六):从几何视角来理解VAE的尝试
By 苏剑林 | 2020-09-10 | 77706位读者 | 引用前段时间公司组织技术分享,轮到笔者时,大家希望我讲讲VAE。鉴于之前笔者也写过变分自编码器系列,所以对笔者来说应该也不是特别难的事情,因此就答应了下来,后来仔细一想才觉得犯难:怎么讲才好呢?
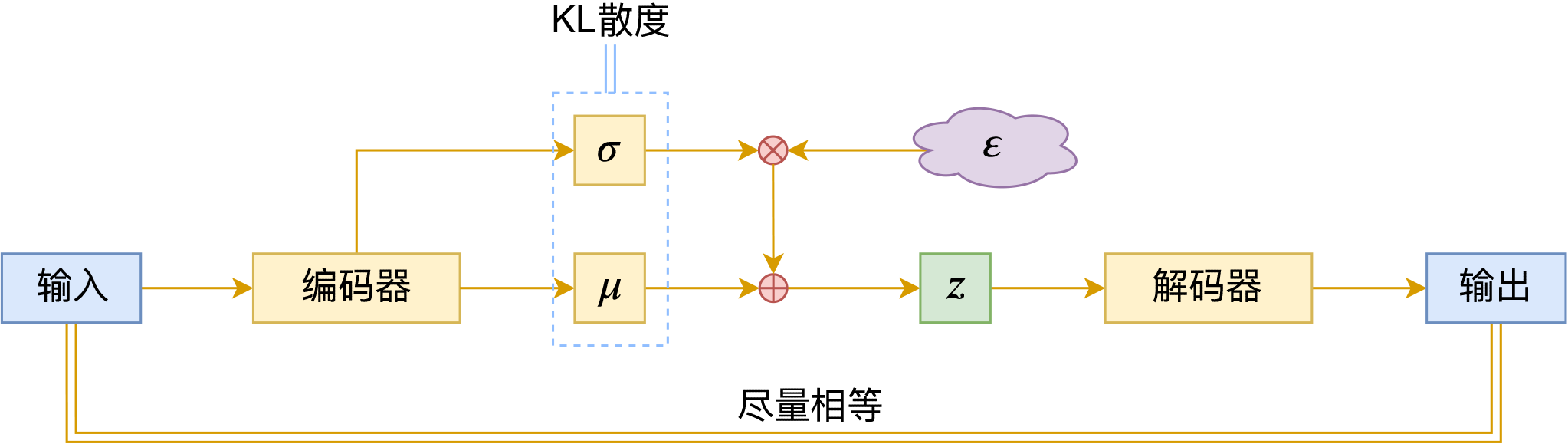
变分自编码器示意图
对于VAE来说,之前笔者有两篇比较系统的介绍:《变分自编码器(一):原来是这么一回事》和《变分自编码器(二):从贝叶斯观点出发》。后者是纯概率推导,对于不做理论研究的人来说其实没什么意义,也不一定能看得懂;前者虽然显浅一点,但也不妥,因为它是从生成模型的角度来讲的,并没有说清楚“为什么需要VAE”(说白了,VAE可以带来生成模型,但是VAE并不一定就为了生成模型),整体风格也不是特别友好。
笔者想了想,对于大多数不了解但是想用VAE的读者来说,他们应该只希望大概了解VAE的形式,然后想要知道“VAE有什么作用”、“VAE相比AE有什么区别”、“什么场景下需要VAE”等问题的答案,对于这种需求,上面两篇文章都无法很好地满足。于是笔者尝试构思了VAE的一种几何图景,试图从几何角度来描绘VAE的关键特性,在此也跟大家分享一下。
2
Jun
我们可以无损放大一个Transformer模型吗(一)
By 苏剑林 | 2021-06-02 | 64276位读者 | 引用看了标题,可能读者会有疑惑,大家不都想着将大模型缩小吗?怎么你想着将小模型放大了?其实背景是这样的:通常来说更大的模型加更多的数据确实能起得更好的效果,然而算力有限的情况下,从零预训练一个大的模型时间成本太大了,如果还要调试几次参数,那么可能几个月就过去了。
这时候“穷人思维”就冒出来了(土豪可以无视):能否先训练一个同样层数的小模型,然后放大后继续训练?这样一来,预训练后的小模型权重经过放大后,就是大模型一个起点很高的初始化权重,那么大模型阶段的训练步数就可以减少了,从而缩短整体的训练时间。
那么,小模型可以无损地放大为一个大模型吗?本文就来从理论上分析这个问题。
含义
有的读者可能想到:这肯定可以呀,大模型的拟合能力肯定大于小模型呀。的确,从拟合能力角度来看,这件事肯定是可以办到的,但这还不是本文关心的“无损放大”的全部。
24
Aug
隐藏在动量中的梯度累积:少更新几步,效果反而更好?
By 苏剑林 | 2021-08-24 | 35277位读者 | 引用我们知道,梯度累积是在有限显存下实现大batch_size训练的常用技巧。在之前的文章《用时间换取效果:Keras梯度累积优化器》中,我们就简单介绍过梯度累积的实现,大致的思路是新增一组参数来缓存梯度,最后用缓存的梯度来更新模型。美中不足的是,新增一组参数会带来额外的显存占用。
这几天笔者在思考优化器的时候,突然意识到:梯度累积其实可以内置在带动量的优化器中!带着这个思路,笔者对优化了进行了一些推导和实验,最后还得到一个有意思但又有点反直觉的结论:少更新几步参数,模型最终效果可能会变好!
注:本文下面的结果,几乎原封不动且没有引用地出现在Google的论文《Combined Scaling for Zero-shot Transfer Learning》中,在此不做过多评价,请读者自行品评。
SGDM
在正式讨论之前,我们定义函数
\begin{equation}\chi_{t/k} = \left\{ \begin{aligned}&1,\quad t \equiv 0\,(\text{mod}\, k) \\
&0,\quad t \not\equiv 0\,(\text{mod}\, k)
\end{aligned}\right.\end{equation}
也就是说,$t$是一个整数,当它是$k$的倍数时,$\chi_{t/k}=1$,否则$\chi_{t/k}=0$,这其实就是一个$t$能否被$k$整除的示性函数。在后面的讨论中,我们将反复用到这个函数。
15
Nov
WGAN新方案:通过梯度归一化来实现L约束
By 苏剑林 | 2021-11-15 | 60182位读者 | 引用当前,WGAN主流的实现方式包括参数裁剪(Weight Clipping)、谱归一化(Spectral Normalization)、梯度惩罚(Gradient Penalty),本来则来介绍一种新的实现方案:梯度归一化(Gradient Normalization),该方案出自两篇有意思的论文,分别是《Gradient Normalization for Generative Adversarial Networks》和《GraN-GAN: Piecewise Gradient Normalization for Generative Adversarial Networks》。
有意思在什么地方呢?从标题可以看到,这两篇论文应该是高度重合的,甚至应该是同一作者的。但事实上,这是两篇不同团队的、大致是同一时期的论文,一篇中了ICCV,一篇中了WACV,它们基于同样的假设推出了几乎一样的解决方案,内容重合度之高让我一直以为是同一篇论文。果然是巧合无处不在啊~
24
Dec
概率分布的熵归一化(Entropy Normalization)
By 苏剑林 | 2021-12-24 | 52470位读者 | 引用在上一篇文章《从熵不变性看Attention的Scale操作》中,我们从熵不变性的角度推导了一个新的Attention Scale,并且实验显示具有熵不变性的新Scale确实能使得Attention的外推性能更好。这时候笔者就有一个很自然的疑问:
有没有类似L2 Normalization之类的操作,可以直接对概率分布进行变换,使得保持原始分布主要特性的同时,让它的熵为指定值?
笔者带着疑问搜索了一番,发现没有类似的研究,于是自己尝试推导了一下,算是得到了一个基本满意的结果,暂称为“熵归一化(Entropy Normalization)”,记录在此,供有需要的读者参考。
幂次变换
首先,假设$n$元分布$(p_1,p_2,\cdots,p_n)$,它的熵定义为
\begin{equation}\mathcal{H} = -\sum_i p_i \log p_i = \mathbb{E}[-\log p_i]\end{equation}
30
Nov
用热传导方程来指导自监督学习
By 苏剑林 | 2022-11-30 | 34728位读者 | 引用用理论物理来卷机器学习已经不是什么新鲜事了,比如上个月介绍的《生成扩散模型漫谈(十三):从万有引力到扩散模型》就是经典一例。最近一篇新出的论文《Self-Supervised Learning based on Heat Equation》,顾名思义,用热传导方程来做(图像领域的)自监督学习,引起了笔者的兴趣。这种物理方程如何在机器学习中发挥作用?同样的思路能否迁移到NLP中?让我们一起来读读论文。
基本方程
如下图,左边是物理中热传导方程的解,右端则是CAM、积分梯度等显著性方法得到的归因热力图,可以看到两者有一定的相似之处,于是作者认为热传导方程可以作为好的视觉特征的一个重要先验。
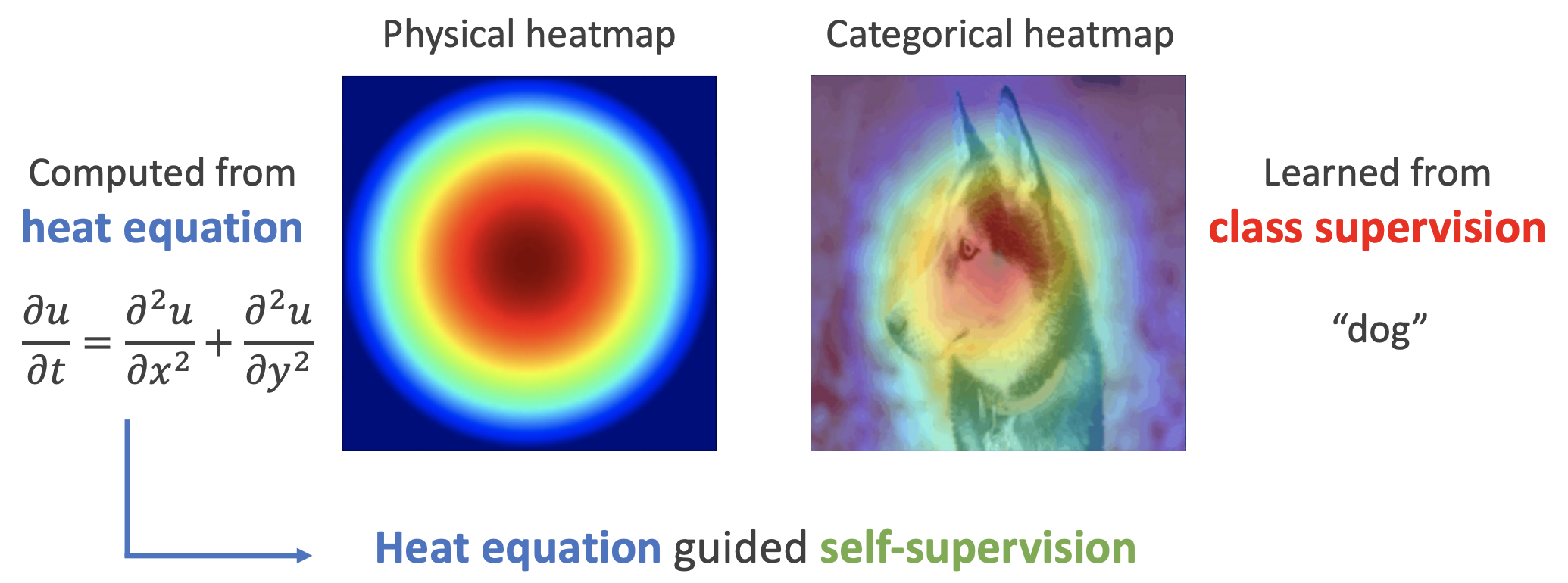
热方程的热力图(左)和视觉模型的热力图(右)
16
Sep
随机分词浅探:从Viterbi Decoding到Viterbi Sampling
By 苏剑林 | 2023-09-16 | 22964位读者 | 引用上一篇文章《大词表语言模型在续写任务上的一个问题及对策》发布后,很快就有读者指出可以在训练阶段引入带有随机性的分词结果来解决同样的问题,并且已经有论文和实现。经过进一步查阅学习,笔者发现这是一个名为Subword Regularization的技巧,最早应用在NMT(机器翻译)中,目前SentencePiece也有相应的实现。看起来这个技巧确实能缓解前述问题,甚至有助于增强语言模型的容错能力,所以就有了将它加进去BytePiece的想法。
那么问题来了,如何将确定性分词改为随机性分词呢?BytePiece是基于Unigram模型的,它通过Viterbi算法找最大概率的分词方案,既然有概率,是否就可以自然地导出随机采样?本文来讨论这个问题,并分享自己的解决方案。
26
Oct
新词发现的信息熵方法与实现
By 苏剑林 | 2015-10-26 | 116959位读者 | 引用在本博客的前面文章中,已经简单提到过中文文本处理与挖掘的问题了,中文数据挖掘与英语同类问题中最大的差别是,中文没有空格,如果要较好地完成语言任务,首先得分词。目前流行的分词方法都是基于词库的,然而重要的问题就来了:词库哪里来?人工可以把一些常用的词语收集到词库中,然而这却应付不了层出不穷的新词,尤其是网络新词等——而这往往是语言任务的关键地方。因此,中文语言处理很核心的一个任务就是完善新词发现算法。
新词发现说的就是不加入任何先验素材,直接从大规模的语料库中,自动发现可能成词的语言片段。前两天我去小虾的公司膜拜,并且试着加入了他们的一个开发项目中,主要任务就是网络文章处理。因此,补习了一下新词发现的算法知识,参考了Matrix67.com的文章《互联网时代的社会语言学:基于SNS的文本数据挖掘》,尤其是里边的信息熵思想,并且根据他的思路,用Python写了个简单的脚本。

最近评论