






1
Jun
泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练
By 苏剑林 | 2020-06-01 | 105168位读者 | 引用提高模型的泛化性能是机器学习致力追求的目标之一。常见的提高泛化性的方法主要有两种:第一种是添加噪声,比如往输入添加高斯噪声、中间层增加Dropout以及进来比较热门的对抗训练等,对图像进行随机平移缩放等数据扩增手段某种意义上也属于此列;第二种是往loss里边添加正则项,比如$L_1, L_2$惩罚、梯度惩罚等。本文试图探索几种常见的提高泛化性能的手段的关联。
随机噪声
我们记模型为$f(x)$,$\mathcal{D}$为训练数据集合,$l(f(x), y)$为单个样本的loss,那么我们的优化目标是
\begin{equation}\mathop{\text{argmin}}_{\theta} L(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}}[l(f(x), y)]\end{equation}
$\theta$是$f(x)$里边的可训练参数。假如往模型输入添加噪声$\varepsilon$,其分布为$q(\varepsilon)$,那么优化目标就变为
\begin{equation}\mathop{\text{argmin}}_{\theta} L_{\varepsilon}(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}, \varepsilon\sim q(\varepsilon)}[l(f(x + \varepsilon), y)]\end{equation}
当然,可以添加噪声的地方不仅仅是输入,也可以是中间层,也可以是权重$\theta$,甚至可以是输出$y$(等价于标签平滑),噪声也不一定是加上去的,比如Dropout是乘上去的。对于加性噪声来说,$q(\varepsilon)$的常见选择是均值为0、方差固定的高斯分布;而对于乘性噪声来说,常见选择是均匀分布$U([0,1])$或者是伯努利分布。
添加随机噪声的目的很直观,就是希望模型能学会抵御一些随机扰动,从而降低对输入或者参数的敏感性,而降低了这种敏感性,通常意味着所得到的模型不再那么依赖训练集,所以有助于提高模型泛化性能。
11
Dec
从动力学角度看优化算法(六):为什么SimSiam不退化?
By 苏剑林 | 2020-12-11 | 89144位读者 | 引用自SimCLR以来,CV中关于无监督特征学习的工作层出不穷,让人眼花缭乱。这些工作大多数都是基于对比学习的,即通过适当的方式构造正负样本进行分类学习的。然而,在众多类似的工作中总有一些特立独行的研究,比如Google的BYOL和最近的SimSiam,它们提出了单靠正样本就可以完成特征学习的方案,让人觉得耳目一新。但是没有负样本的支撑,模型怎么不会退化(坍缩)为一个没有意义的常数模型呢?这便是这两篇论文最值得让人思考和回味的问题了。
其中SimSiam给出了让很多人都点赞的答案,但笔者觉得SimSiam也只是把问题换了种说法,并没有真的解决这个问题。笔者认为,像SimSiam、GAN等模型的成功,很重要的原因是使用了基于梯度的优化器(而非其他更强或者更弱的优化器),所以不结合优化动力学的答案都是不完整的。在这里,笔者尝试结合动力学来分析SimSiam不会退化的原因。
SimSiam
在看SimSiam之前,我们可以先看看BYOL,来自论文《Bootstrap your own latent: A new approach to self-supervised Learning》,其学习过程很简单,就是维护两个编码器Student和Teacher,其中Teacher是Student的滑动平均,Student则又反过来向Teacher学习,有种“左脚踩右脚”就可以飞起来的感觉。示意图如下:
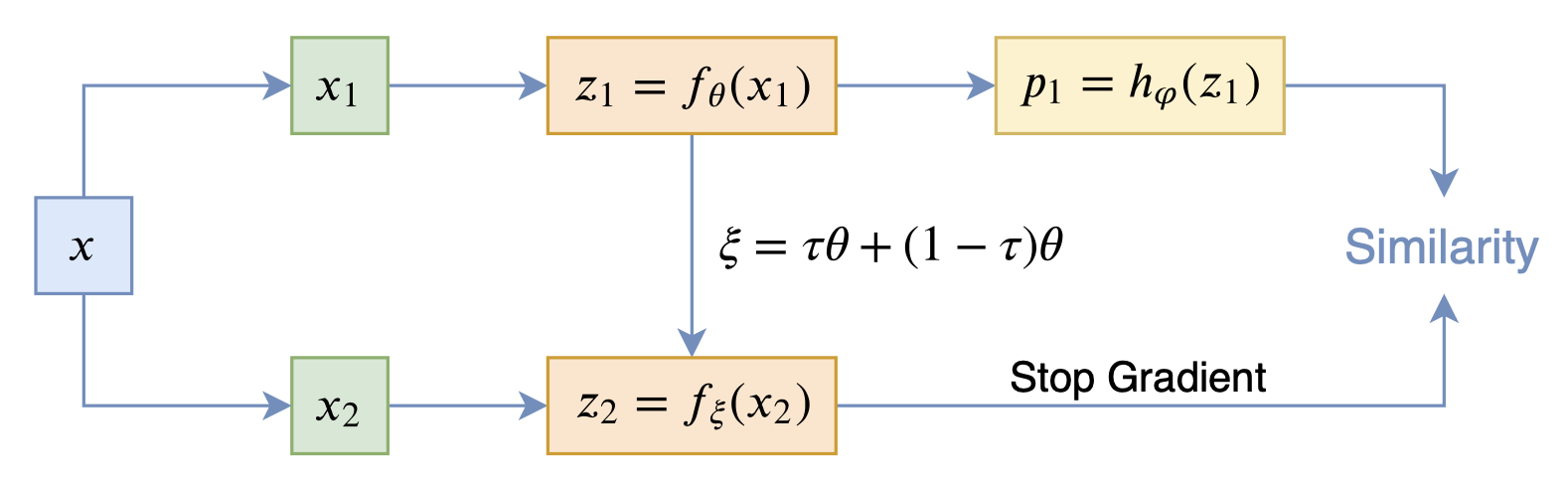
BYOL示意图
3
Apr
P-tuning:自动构建模版,释放语言模型潜能
By 苏剑林 | 2021-04-03 | 162790位读者 | 引用在之前的文章《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》中,我们介绍了一种名为Pattern-Exploiting Training(PET)的方法,它通过人工构建的模版与BERT的MLM模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了。然而,人工构建这样的模版有时候也是比较困难的,而且不同的模版效果差别也很大,如果能够通过少量样本来自动构建模版,也是非常有价值的。
![P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性](/usr/uploads/2021/04/2868831073.png)
P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性
最近Arxiv上的论文《GPT Understands, Too》提出了名为P-tuning的方法,成功地实现了模版的自动构建。不仅如此,借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了一直以来“GPT不擅长NLU”的结论,也是该论文命名的缘由。
26
Jul
FlatNCE:小批次对比学习效果差的原因竟是浮点误差?
By 苏剑林 | 2021-07-26 | 50073位读者 | 引用自SimCLR在视觉无监督学习大放异彩以来,对比学习逐渐在CV乃至NLP中流行了起来,相关研究和工作越来越多。标准的对比学习的一个广为人知的缺点是需要比较大的batch_size(SimCLR在batch_size=4096时效果最佳),小batch_size的时候效果会明显降低,为此,后续工作的改进方向之一就是降低对大batch_size的依赖。那么,一个很自然的问题是:标准的对比学习在小batch_size时效果差的原因究竟是什么呢?
近日,一篇名为《Simpler, Faster, Stronger: Breaking The log-K Curse On Contrastive Learners With FlatNCE》对此问题作出了回答:因为浮点误差。看起来真的很让人难以置信,但论文的分析确实颇有道理,并且所提出的改进FlatNCE确实也工作得更好,让人不得不信服。
细微之处
接下来,笔者将按照自己的理解和记号来介绍原论文的主要内容。对比学习(Contrastive Learning)就不帮大家详细复习了,大体上来说,对于某个样本$x$,我们需要构建$K$个配对样本$y_1,y_2,\cdots,y_K$,其中$y_t$是正样本而其余都是负样本,然后分别给每个样本对$(x, y_i)$打分,分别记为$s_1,s_2,\cdots,s_K$,对比学习希望拉大正负样本对的得分差,通常直接用交叉熵作为损失:
\begin{equation}-\log \frac{e^{s_t}}{\sum\limits_i e^{s_i}} = \log \left(\sum_i e^{s_i}\right) - s_t = \log \left(1 + \sum_{i\neq t} e^{s_i - s_t}\right)\end{equation}
18
Jan
多任务学习漫谈(一):以损失之名
By 苏剑林 | 2022-01-18 | 168951位读者 | 引用能提升模型性能的方法有很多,多任务学习(Multi-Task Learning)也是其中一种。简单来说,多任务学习是希望将多个相关的任务共同训练,希望不同任务之间能够相互补充和促进,从而获得单任务上更好的效果(准确率、鲁棒性等)。然而,多任务学习并不是所有任务堆起来就能生效那么简单,如何平衡每个任务的训练,使得各个任务都尽量获得有益的提升,依然是值得研究的课题。
最近,笔者机缘巧合之下,也进行了一些多任务学习的尝试,借机也学习了相关内容,在此挑部分结果与大家交流和讨论。
加权求和
从损失函数的层面看,多任务学习就是有多个损失函数$\mathcal{L}_1,\mathcal{L}_2,\cdots,\mathcal{L}_n$,一般情况下它们有大量的共享参数、少量的独立参数,而我们的目标是让每个损失函数都尽可能地小。为此,我们引入权重$\alpha_1,\alpha_2,\cdots,\alpha_n\geq 0$,通过加权求和的方式将它转化为如下损失函数的单任务学习
\begin{equation}\mathcal{L} = \sum_{i=1}^n \alpha_i \mathcal{L}_i\label{eq:w-loss}\end{equation}
在这个视角下,多任务学习的主要难点就是如何确定各个$\alpha_i$了。
14
Mar
缓解交叉熵过度自信的一个简明方案
By 苏剑林 | 2023-03-14 | 37313位读者 | 引用众所周知,分类问题的常规评估指标是正确率,而标准的损失函数则是交叉熵,交叉熵有着收敛快的优点,但它并非是正确率的光滑近似,这就带来了训练和预测的不一致性问题。另一方面,当训练样本的预测概率很低时,交叉熵会给出一个非常巨大的损失(趋于$-\log 0^{+}=\infty$),这意味着交叉熵会特别关注预测概率低的样本——哪怕这个样本可能是“脏数据”。所以,交叉熵训练出来的模型往往有过度自信现象,即每个样本都给出较高的预测概率,这会带来两个副作用:一是对脏数据的过度拟合带来的效果下降,二是预测的概率值无法作为不确定性的良好指标。
围绕交叉熵的改进,学术界一直都有持续输出,目前这方面的研究仍处于“八仙过海,各显神通”的状态,没有标准答案。在这篇文章中,我们来学习一下论文《Tailoring Language Generation Models under Total Variation Distance》给出的该问题的又一种简明的候选方案。
31
Jan
幂等生成网络IGN:试图将判别和生成合二为一的GAN
By 苏剑林 | 2024-01-31 | 50176位读者 | 引用前段时间,一个名为“幂等生成网络(Idempotent Generative Network,IGN)”的生成模型引起了一定的关注。它自称是一种独立于已有的VAE、GAN、flow、Diffusion之外的新型生成模型,并且具有单步采样的特点。也许是大家苦于当前主流的扩散模型的多步采样生成过程久矣,因此任何声称可以实现单步采样的“风吹草动”都很容易吸引人们的关注。此外,IGN名称中的“幂等”一词也增加了它的神秘感,进一步扩大了人们的期待,也成功引起了笔者的兴趣,只不过之前一直有别的事情要忙,所以没来得及认真阅读模型细节。
最近闲了一点,想起来还有个IGN没读,于是重新把论文翻了出来,但阅读之后却颇感困惑:这哪里是个新模型,不就是个GAN的变种吗?跟常规GAN不同的是,它将生成器和判别器合二为一了。那这个“合二为一”是不是有什么特别的好处,比如训练更稳定?个人又感觉没有。下面将分享笔者从GAN角度理解IGN的过程和疑问。
生成对抗
关于GAN(Generative Adversarial Network,生成对抗网络),笔者前几年系统地学习过一段时间(查看GAN标签可以查看到相关文章),但近几年没有持续地关注了,因此这里先对GAN做个简单的回顾,也方便后续章节中我们对比GAN与IGN之间的异同。
19
Sep
Softmax后传:寻找Top-K的光滑近似
By 苏剑林 | 2024-09-19 | 34205位读者 | 引用Softmax,顾名思义是“soft的max”,是$\max$算子(准确来说是$\text{argmax}$)的光滑近似,它通过指数归一化将任意向量$\boldsymbol{x}\in\mathbb{R}^n$转化为分量非负且和为1的新向量,并允许我们通过温度参数来调节它与$\text{argmax}$(的one hot形式)的近似程度。除了指数归一化外,我们此前在《通向概率分布之路:盘点Softmax及其替代品》也介绍过其他一些能实现相同效果的方案。
我们知道,最大值通常又称Top-1,它的光滑近似方案看起来已经相当成熟,那读者有没有思考过,一般的Top-$k$的光滑近似又是怎么样的呢?下面让我们一起来探讨一下这个问题。
问题描述
设向量$\boldsymbol{x}=(x_1,x_2,\cdots,x_n)\in\mathbb{R}^n$,简单起见我们假设它们两两不相等,即$i\neq j \Leftrightarrow x_i\neq x_j$。记$\Omega_k(\boldsymbol{x})$为$\boldsymbol{x}$最大的$k$个分量的下标集合,即$|\Omega_k(\boldsymbol{x})|=k$以及$\forall i\in \Omega_k(\boldsymbol{x}), j \not\in \Omega_k(\boldsymbol{x})\Rightarrow x_i > x_j$。我们定义Top-$k$算子$\mathcal{T}_k$为$\mathbb{R}^n\mapsto\{0,1\}^n$的映射:
\begin{equation}
[\mathcal{T}_k(\boldsymbol{x})]_i = \left\{\begin{aligned}1,\,\, i\in \Omega_k(\boldsymbol{x}) \\ 0,\,\, i \not\in \Omega_k(\boldsymbol{x})\end{aligned}\right.
\end{equation}
说白了,如果$x_i$属于最大的$k$个元素之一,那么对应的位置变成1,否则变成0,最终结果是一个Multi-Hot向量,比如$\mathcal{T}_2([3,2,1,4]) = [1,0,0,1]$。

最近评论