






1
Sep
玩转Keras之seq2seq自动生成标题
By 苏剑林 | 2018-09-01 | 378476位读者 | 引用话说自称搞了这么久的NLP,我都还没有真正跑过NLP与深度学习结合的经典之作——seq2seq。这两天兴致来了,决定学习并实践一番seq2seq,当然最后少不了Keras实现了。
seq2seq可以做的事情非常多,我这挑选的是比较简单的根据文章内容生成标题(中文),也可以理解为自动摘要的一种。选择这个任务主要是因为“文章-标题”这样的语料对比较好找,能快速实验一下。
seq2seq简介
所谓seq2seq,就是指一般的序列到序列的转换任务,比如机器翻译、自动文摘等等,这种任务的特点是输入序列和输出序列是不对齐的,如果对齐的话,那么我们称之为序列标注,这就比seq2seq简单很多了。所以尽管序列标注任务也可以理解为序列到序列的转换,但我们在谈到seq2seq时,一般不包含序列标注。
要自己实现seq2seq,关键是搞懂seq2seq的原理和架构,一旦弄清楚了,其实不管哪个框架实现起来都不复杂。早期有一个第三方实现的Keras的seq2seq库,现在作者也已经放弃更新了,也许就是觉得这么简单的事情没必要再建一个库了吧。可以参考的资料还有去年Keras官方博客中写的《A ten-minute introduction to sequence-to-sequence learning in Keras》。
8
Sep
“让Keras更酷一些!”:小众的自定义优化器
By 苏剑林 | 2018-09-08 | 90951位读者 | 引用沿着之前的《“让Keras更酷一些!”:精巧的层与花式的回调》写下去~
今天我们来看一个小众需求:自定义优化器。
细想之下,不管用什么框架,自定义优化器这个需求可谓真的是小众中的小众。一般而言,对于大多数任务我们都可以无脑地直接上Adam,而调参炼丹高手一般会用SGD来调出更好的效果,换言之不管是高手新手,都很少会有自定义优化器的需求。
那这篇文章还有什么价值呢?有些场景下会有一点点作用。比如通过学习Keras中的优化器写法,你可以对梯度下降等算法有进一步的认识,你还可以顺带看到Keras的源码是多么简洁优雅。此外,有时候我们可以通过自定义优化器来实现自己的一些功能,比如给一些简单的模型(例如Word2Vec)重写优化器(直接写死梯度,而不是用自动求导),可以使得算法更快;自定义优化器还可以实现诸如“软batch”的功能。
Keras优化器
我们首先来看Keras中自带优化器的代码,位于:
https://github.com/keras-team/keras/blob/master/keras/optimizers.py
20
Dec
从动力学角度看优化算法(二):自适应学习率算法
By 苏剑林 | 2018-12-20 | 51031位读者 | 引用在《从动力学角度看优化算法(一):从SGD到动量加速》一文中,我们提出SGD优化算法跟常微分方程(ODE)的数值解法其实是对应的,由此还可以很自然地分析SGD算法的收敛性质、动量加速的原理等等内容。
在这篇文章中,我们继续沿着这个思路,去理解优化算法中的自适应学习率算法。
RMSprop
首先,我们看一个非常经典的自适应学习率优化算法:RMSprop。RMSprop虽然不是最早提出的自适应学习率的优化算法,但是它却是相当实用的一种,它是诸如Adam这样的更综合的算法的基石,通过它我们可以观察自适应学习率的优化算法是怎么做的。
算法概览
一般的梯度下降是这样的:
$$\begin{equation}\boldsymbol{\theta}_{n+1}=\boldsymbol{\theta}_{n} - \gamma \nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}_{n})\end{equation}$$
很明显,这里的$\gamma$是一个超参数,便是学习率,它可能需要在不同阶段做不同的调整。
而RMSprop则是
$$\begin{equation}\begin{aligned}\boldsymbol{g}_{n+1} =& \nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}_{n})\\
\boldsymbol{G}_{n+1}=&\lambda \boldsymbol{G}_{n} + (1 - \lambda) \boldsymbol{g}_{n+1}\otimes \boldsymbol{g}_{n+1}\\
\boldsymbol{\theta}_{n+1}=&\boldsymbol{\theta}_{n} - \frac{\tilde{\gamma}}{\sqrt{\boldsymbol{G}_{n+1} + \epsilon}}\otimes \boldsymbol{g}_{n+1}
\end{aligned}\end{equation}$$
18
Feb
恒等式 det(exp(A)) = exp(Tr(A)) 赏析
By 苏剑林 | 2019-02-18 | 71259位读者 | 引用本文的主题是一个有趣的矩阵行列式的恒等式
\begin{equation}\det(\exp(\boldsymbol{A})) = \exp(\text{Tr}(\boldsymbol{A}))\label{eq:main}\end{equation}
这个恒等式在挺多数学和物理的计算中都出现过,笔者都在不同的文献中看到过好几次了。
注意左端是矩阵的指数,然后求行列式,这两步都是计算量非常大的运算;右端仅仅是矩阵的迹(一个标量),然后再做标量的指数。两边的计算量差了不知道多少倍,然而它们居然是相等的!这不得不说是一个神奇的事实。
所以,本文就来好好欣赏一个这个恒等式。
3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 275125位读者 | 引用在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
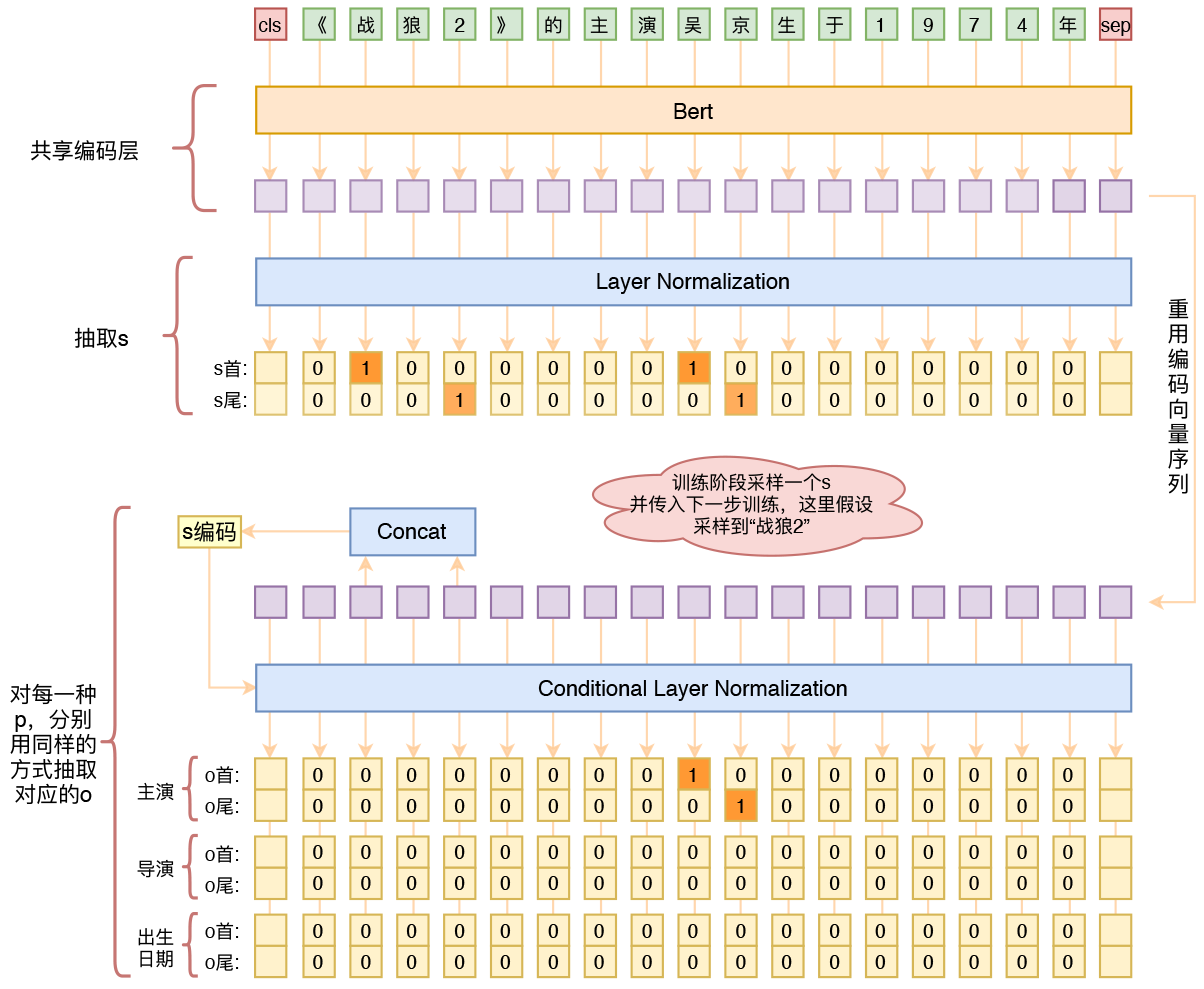
基于Bert的三元组抽取模型结构示意图
26
Dec
“非自回归”也不差:基于MLM的阅读理解问答
By 苏剑林 | 2019-12-26 | 88934位读者 | 引用![用MLM做阅读理解的模型图示(其中[M]表示[MASK]标记)](/usr/uploads/2019/12/1024911876.png)
6
Jul
你跳绳的时候,想过绳子的形状曲线是怎样的吗?
By 苏剑林 | 2019-07-06 | 53345位读者 | 引用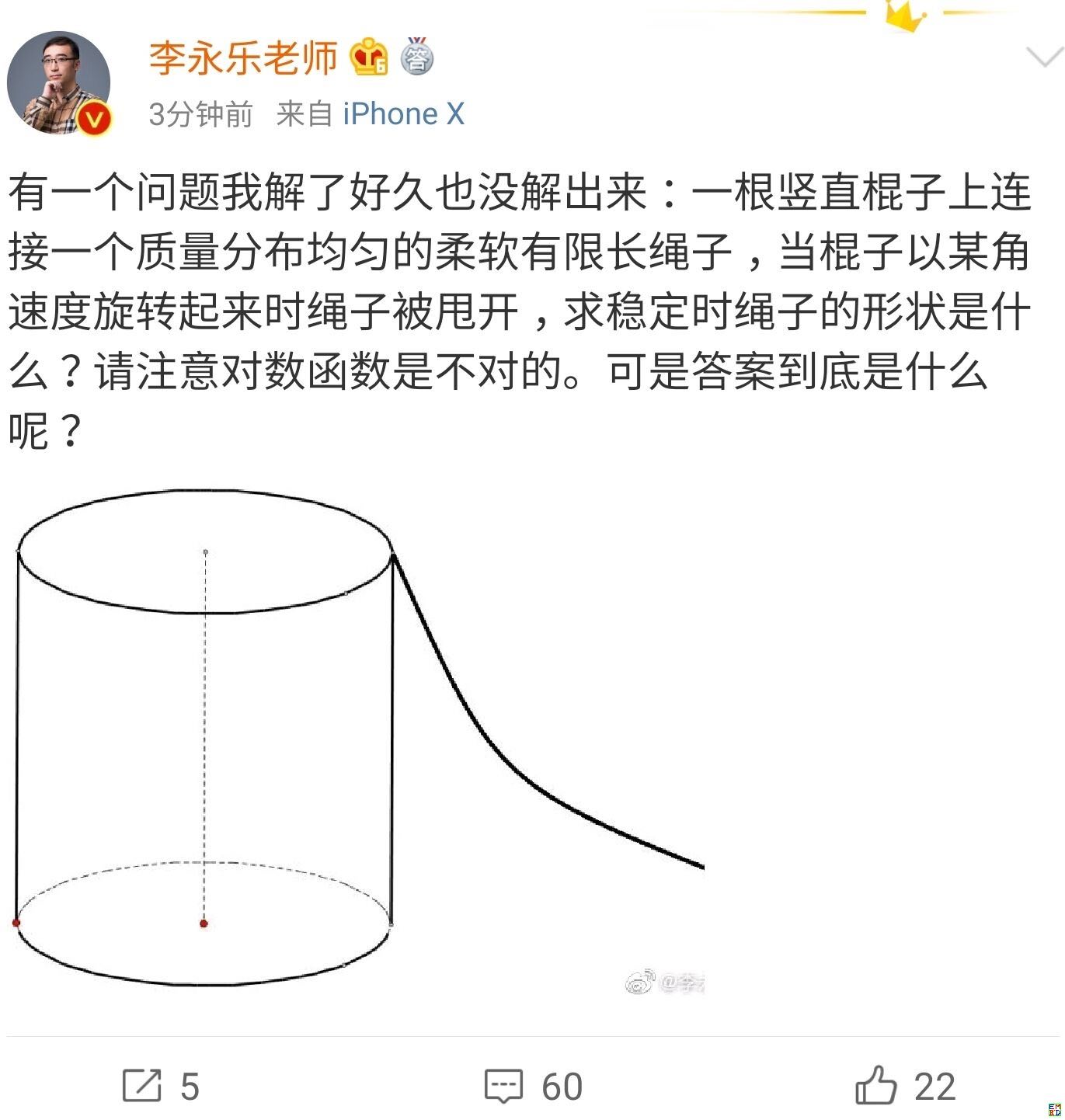
8
Jul
用时间换取效果:Keras梯度累积优化器
By 苏剑林 | 2019-07-08 | 84372位读者 | 引用现在Keras中你也可以用小的batch size实现大batch size的效果了——只要你愿意花$n$倍的时间,可以达到$n$倍batch size的效果,而不需要增加显存。
Github地址:https://github.com/bojone/accum_optimizer_for_keras
扯淡
在一两年之前,做NLP任务都不用怎么担心OOM问题,因为相比CV领域的模型,其实大多数NLP模型都是很浅的,极少会显存不足。幸运或者不幸的是,Bert出世了,然后火了。Bert及其后来者们(GPT-2、XLNET等)都是以足够庞大的Transformer模型为基础,通过足够多的语料预训练模型,然后通过fine tune的方式来完成特定的NLP任务。

最近评论