






12
Sep
【中文分词系列】 5. 基于语言模型的无监督分词
By 苏剑林 | 2016-09-12 | 158614位读者 | 引用迄今为止,前四篇文章已经介绍了分词的若干思路,其中有基于最大概率的查词典方法、基于HMM或LSTM的字标注方法等。这些都是已有的研究方法了,笔者所做的就只是总结工作而已。查词典方法和字标注各有各的好处,我一直在想,能不能给出一种只需要大规模语料来训练的无监督分词模型呢?也就是说,怎么切分,应该是由语料来决定的,跟语言本身没关系。说白了,只要足够多语料,就可以告诉我们怎么分词。
看上去很完美,可是怎么做到呢?《2.基于切分的新词发现》中提供了一种思路,但是不够彻底。那里居于切分的新词发现方法确实可以看成一种无监督分词思路,它就是用一个简单的凝固度来判断某处该不该切分。但从分词的角度来看,这样的分词系统未免太过粗糙了。因此,我一直想着怎么提高这个精度,前期得到了一些有意义的结果,但都没有得到一个完整的理论。而最近正好把这个思路补全了。因为没有查找到类似的工作,所以这算是笔者在分词方面的一点原创工作了。
语言模型
首先简单谈一下语言模型。
16
Nov
为什么勒贝格积分比黎曼积分强?
By 苏剑林 | 2016-11-16 | 121587位读者 | 引用学过实变函数的朋友,总会知道有个叫勒贝格积分的东西,号称是黎曼积分的改进版。虽然“实变函数学十遍,泛函分析心泛寒”,在学习实变函数的时候,我们通常都是云里雾里的,不过到最后,在老师的“灌溉”之下,也就耳濡目染了知道了一些结论,比如“黎曼可积的函数(在有限区间),也是勒贝格可积的”,说白了,就是“勒贝格积分比黎曼积分强”。那么,问题来了,究竟强在哪儿?为什么会强?

黎曼

勒贝格
这个问题,笔者在学习实变函数的时候并没有弄懂,后来也一直搁着,直到最近认真看了《重温微积分》之后,才有了些感觉。顺便说,齐民友老师的《重温微积分》真的很赞,值得一看。
本是同根生,相煎何太急?
2
Apr
【不可思议的Word2Vec】 1.数学原理
By 苏剑林 | 2017-04-02 | 59359位读者 | 引用对于了解深度学习、自然语言处理NLP的读者来说,Word2Vec可以说是家喻户晓的工具,尽管不是每一个人都用到了它,但应该大家都会听说过它——Google出品的高效率的获取词向量的工具。
Word2Vec不可思议?
大多数人都是将Word2Vec作为词向量的等价名词,也就是说,纯粹作为一个用来获取词向量的工具,关心模型本身的读者并不多。可能是因为模型过于简化了,所以大家觉得这样简化的模型肯定很不准确,所以没法用,但它的副产品词向量的质量反而还不错。没错,如果是作为语言模型来说,Word2Vec实在是太粗糙了。
但是,为什么要将它作为语言模型来看呢?抛开语言模型的思维约束,只看模型本身,我们就会发现,Word2Vec的两个模型 —— CBOW和Skip-Gram —— 实际上大有用途,它们从不同角度来描述了周围词与当前词的关系,而很多基本的NLP任务,都是建立在这个关系之上,如关键词抽取、逻辑推理等。这几篇文章就是希望能够抛砖引玉,通过介绍Word2Vec模型本身,以及几个看上去“不可思议”的用法,来提供一些研究此类问题的新思路。
8
Jun
互怼的艺术:从零直达WGAN-GP
By 苏剑林 | 2017-06-08 | 310711位读者 | 引用前言
GAN,全称Generative Adversarial Nets,中文名是生成对抗式网络。对于GAN来说,最通俗的解释就是“伪造者-鉴别者”的解释,如艺术画的伪造者和鉴别者。一开始伪造者和鉴别者的水平都不高,但是鉴别者还是比较容易鉴别出伪造者伪造出来的艺术画。但随着伪造者对伪造技术的学习后,其伪造的艺术画会让鉴别者识别错误;或者随着鉴别者对鉴别技术的学习后,能够很简单的鉴别出伪造者伪造的艺术画。这是一个双方不断学习技术,以达到最高的伪造和鉴别水平的过程。 然而,稍微深入了解的读者就会发现,跟现实中的造假者不同,造假者会与时俱进地使用新材料新技术来造假,而GAN最神奇而又让人困惑的地方是它能够将随机噪声映射为我们所希望的正样本,有噪声就有正样本,这不是无本生意吗,多划算~
另一个情况是,自从WGAN提出以来,基本上GAN的主流研究都已经变成了WGAN上去了,但WGAN的形式事实上已经跟“伪造者-鉴别者”差得比较远了。而且WGAN虽然最后的形式并不复杂,但是推导过程却用到了诸多复杂的数学,使得我无心研读原始论文。这迫使我要找从一条简明直观的线索来理解GAN。幸好,经过一段时间的思考,有点收获。
6
Aug
【不可思议的Word2Vec】6. Keras版的Word2Vec
By 苏剑林 | 2017-08-06 | 148604位读者 | 引用前言
看过我之前写的TF版的Word2Vec后,Keras群里的Yin神问我有没有Keras版的。事实上在做TF版之前,我就写过Keras版的,不过没有保留,所以重写了一遍,更高效率,代码也更好看了。纯Keras代码实现Word2Vec,原理跟《【不可思议的Word2Vec】5. Tensorflow版的Word2Vec》是一样的,现在放出来,我想,会有人需要的。(比如,自己往里边加一些额外输入,然后做更好的词向量模型?)
由于Keras同时支持tensorflow、theano、cntk等多个后端,这就等价于实现了多个框架的Word2Vec了。嗯,这样想就高大上了,哈哈~
代码
6
Oct
从马尔科夫过程到主方程(推导过程)
By 苏剑林 | 2017-10-06 | 78571位读者 | 引用主方程(master equation)是对随机过程进行建模的重要方法,它代表着马尔科夫过程的微分形式,我们的专业主要工具之一就是主方程,说宏大一点,量子力学和统计力学等也不外乎是主方程的一个特例。
然而,笔者阅读了几个著作,比如《统计物理现代教程》,还有我导师的《生物系统的随机动力学》,我发现这些著作对于主方程的推导都很模糊,他们在着力解释结果的意义,但并不说明结果的思想来源,因此其过程难以让人信服。而知乎上有人提问《如何理解马尔科夫过程的主方程的推导过程?》但没有得到很好的答案,也表明了这个事实。
马尔可夫过程
主方程是用来描述马尔科夫过程的,而马尔科夫过程可以理解为运动的无记忆性,说通俗点,就是下一刻的概率分布,只跟当前时刻有关,跟历史状态无关。用概率公式写出来就是(这里只考虑连续型概率,因此这里的$p$是概率密度):
$$\begin{equation}\label{eq:maerkefu}p(x,\tau)=\int p(x,\tau|y,t) p(y,t) dy\end{equation}$$
这里的积分区域是全空间。这里的$p(x,\tau|y,t)$称为跃迁概率,即已经确定了$t$时刻来到了$y$位置后、在$\tau$时刻达到$x$的概率密度,这个式子的物理意义是很明显的,就不多做解释了。
19
Nov
更别致的词向量模型(二):对语言进行建模
By 苏剑林 | 2017-11-19 | 57617位读者 | 引用从条件概率到互信息
目前,词向量模型的原理基本都是词的上下文的分布可以揭示这个词的语义,就好比“看看你跟什么样的人交往,就知道你是什么样的人”,所以词向量模型的核心就是对上下文的关系进行建模。除了glove之外,几乎所有词向量模型都是在对条件概率$P(w|context)$进行建模,比如Word2Vec的skip gram模型就是对条件概率$P(w_2|w_1)$进行建模。但这个量其实是有些缺点的,首先它是不对称的,即$P(w_2|w_1)$不一定等于$P(w_1|w_2)$,这样我们在建模的时候,就要把上下文向量和目标向量区分开,它们不能在同一向量空间中;其次,它是有界的、归一化的量,这就意味着我们必须使用softmax等方法将它压缩归一,这造成了优化上的困难。
事实上,在NLP的世界里,有一个更加对称的量比单纯的$P(w_2|w_1)$更为重要,那就是
\[\frac{P(w_1,w_2)}{P(w_1)P(w_2)}=\frac{P(w_2|w_1)}{P(w_2)}\tag{1}\]
这个量的大概意思是“两个词真实碰面的概率是它们随机相遇的概率的多少倍”,如果它远远大于1,那么表明它们倾向于共同出现而不是随机组合的,当然如果它远远小于1,那就意味着它们俩是刻意回避对方的。这个量在NLP界是举足轻重的,我们暂且称它为“相关度“,当然,它的对数值更加出名,大名为点互信息(Pointwise Mutual Information,PMI):
\[\text{PMI}(w_1,w_2)=\log \frac{P(w_1,w_2)}{P(w_1)P(w_2)}\tag{2}\]
有了上面的理论基础,我们认为,如果能直接对相关度进行建模,会比直接对条件概率$P(w_2|w_1)$建模更加合理,所以本文就围绕这个角度进行展开。在此之前,我们先进一步展示一下互信息本身的美妙性质。
18
Mar
变分自编码器(一):原来是这么一回事
By 苏剑林 | 2018-03-18 | 1045588位读者 | 引用过去虽然没有细看,但印象里一直觉得变分自编码器(Variational Auto-Encoder,VAE)是个好东西。于是趁着最近看概率图模型的三分钟热度,我决定也争取把VAE搞懂。于是乎照样翻了网上很多资料,无一例外发现都很含糊,主要的感觉是公式写了一大通,还是迷迷糊糊的,最后好不容易觉得看懂了,再去看看实现的代码,又感觉实现代码跟理论完全不是一回事啊。
终于,东拼西凑再加上我这段时间对概率模型的一些积累,并反复对比原论文《Auto-Encoding Variational Bayes》,最后我觉得我应该是想明白了。其实真正的VAE,跟很多教程说的的还真不大一样,很多教程写了一大通,都没有把模型的要点写出来~于是写了这篇东西,希望通过下面的文字,能把VAE初步讲清楚。
分布变换
通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量$Z$生成目标数据$X$的模型,但是实现上有所不同。更准确地讲,它们是假设了$Z$服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型$X=g(Z)$,这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。
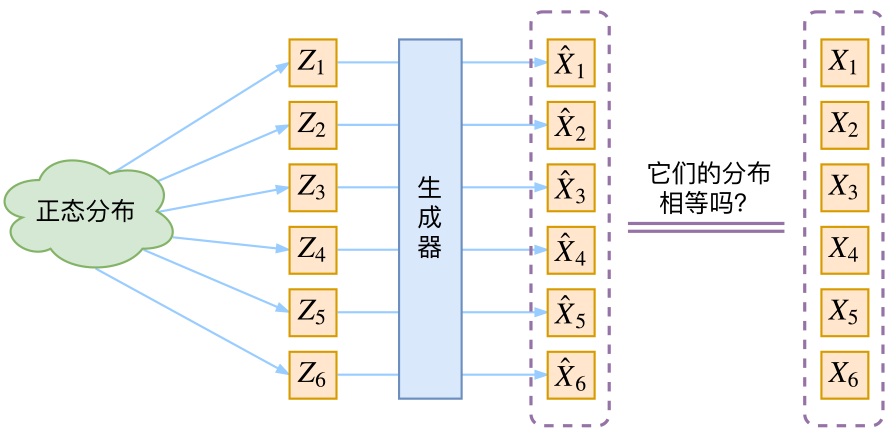
生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式

最近评论