






14
Mar
缓解交叉熵过度自信的一个简明方案
By 苏剑林 | 2023-03-14 | 37086位读者 | 引用众所周知,分类问题的常规评估指标是正确率,而标准的损失函数则是交叉熵,交叉熵有着收敛快的优点,但它并非是正确率的光滑近似,这就带来了训练和预测的不一致性问题。另一方面,当训练样本的预测概率很低时,交叉熵会给出一个非常巨大的损失(趋于$-\log 0^{+}=\infty$),这意味着交叉熵会特别关注预测概率低的样本——哪怕这个样本可能是“脏数据”。所以,交叉熵训练出来的模型往往有过度自信现象,即每个样本都给出较高的预测概率,这会带来两个副作用:一是对脏数据的过度拟合带来的效果下降,二是预测的概率值无法作为不确定性的良好指标。
围绕交叉熵的改进,学术界一直都有持续输出,目前这方面的研究仍处于“八仙过海,各显神通”的状态,没有标准答案。在这篇文章中,我们来学习一下论文《Tailoring Language Generation Models under Total Variation Distance》给出的该问题的又一种简明的候选方案。
12
May
Transformer升级之路:9、一种全局长度外推的新思路
By 苏剑林 | 2023-05-12 | 65673位读者 | 引用说到Transformer无法处理超长序列的原因,大家的第一反应通常都是Self Attention的二次复杂度。但事实上,即便忽略算力限制,常规的Transformer也无法处理超长序列,因为它们的长度外推性(Length Extrapolation)并不好,具体表现为当输入序列明显超过训练长度时,模型的效果通常会严重下降。
尽管已有一些相关工作,但长度外推问题离实际解决还比较远。本文介绍笔者构思的一种参考方案,它可能是目前唯一一种可以用在生成模型上、具备全局依赖能力的长度外推方法。
方法回顾
长度外推,也称为长度泛化(Length Generalization),此前我们在《Transformer升级之路:7、长度外推性与局部注意力》、《Transformer升级之路:8、长度外推性与位置鲁棒性》已经介绍过部分工作。然而,它们各有各的问题。
20
Nov
Transformer升级之路:15、Key归一化助力长度外推
By 苏剑林 | 2023-11-20 | 63194位读者 | 引用大体上,我们可以将目前Transformer的长度外推技术分为两类:一类是事后修改,比如NTK-RoPE、YaRN、ReRoPE等,这类方法的特点是直接修改推理模型,无需微调就能达到一定的长度外推效果,但缺点是它们都无法保持模型在训练长度内的恒等性;另一类自然是事前修改,如ALIBI、KERPLE、XPOS以及HWFA等,它们可以不加改动地实现一定的长度外推,但相应的改动需要在训练之前就引入,因此无法不微调地用于现成模型,并且这类方法是否能够Scale Up还没得到广泛认可。
在这篇文章中,笔者将介绍一种意外发现的长度外推方案——“KeyNorm”——对Attention的Key序列做L2 Normalization,很明显它属于事前修改一类,但对Attention机制的修改非常小,因此看上去非常有希望能够Scale Up。
最初动机
之所以说“意外发现”,是因为该改动的原始动机并不是长度外推,而是尝试替换Scaled Dot-Product Attention中的Scale方式。我们知道,Attention的标准定义是(本文主要考虑Causal场景)
\begin{equation}\boldsymbol{o}_i = \frac{\sum_{j = 1}^i\exp\left(\frac{\boldsymbol{q}_i\cdot \boldsymbol{k}_j}{\sqrt{d}}\right)\boldsymbol{v}_j}{\sum_{j = 1}^i\exp\left(\frac{\boldsymbol{q}_i\cdot \boldsymbol{k}_j}{\sqrt{d}}\right)},\quad \boldsymbol{q}_i,\boldsymbol{k}_j\in\mathbb{R}^d\label{eq:sdpa}\end{equation}
24
Oct
VQ的旋转技巧:梯度直通估计的一般推广
By 苏剑林 | 2024-10-24 | 28713位读者 | 引用随着多模态LLM的方兴未艾,VQ(Vector Quantization)的地位也“水涨船高”,它可以作为视觉乃至任意模态的Tokenizer,将多模态数据统一到自回归生成框架中。遗憾的是,自VQ-VAE首次提出VQ以来,其理论并没有显著进步,像编码表的坍缩或利用率低等问题至今仍亟待解决,取而代之的是FSQ等替代方案被提出,成为了VQ有力的“竞争对手”。
然而,FSQ并不能在任何场景下都替代VQ,所以VQ本身的改进依然是有价值的。近日笔者读到了《Restructuring Vector Quantization with the Rotation Trick》,它提出了一种旋转技巧,声称能改善VQ的一系列问题,本文就让我们一起来品鉴一下。
回顾
早在五年前的博文《VQ-VAE的简明介绍:量子化自编码器》中我们就介绍过了VQ-VAE,后来在《简单得令人尴尬的FSQ:“四舍五入”超越了VQ-VAE》介绍FSQ的时候,也再次仔细地温习了VQ-VAE,还不了解的读者可以先阅读这两篇文章。
20
Nov
不用L约束又不会梯度消失的GAN,了解一下?
By 苏剑林 | 2018-11-20 | 181684位读者 | 引用不知道从什么时候开始,我发现我也掉到了GAN的大坑里边了,唉,争取早日能跳出来...
这篇博客介绍的是我最近提交到arxiv的一个关于GAN的新框架,里边主要介绍了一种对概率散度的新理解,并且基于这种理解推导出了一个新的GAN。整篇文章比较偏理论,对这个GAN的相关性质都做了完整的论证,自认为是一个理论完备的结果。
文章链接:https://papers.cool/arxiv/1811.07296
先摆结论:
1、论文提供了一种分析和构造概率散度的直接思路,从而简化了构建新GAN框架的过程。
2、推导出了一个称为GAN-QP的GAN框架$\eqref{eq:gan-gp-gd}$,这个GAN不需要像WGAN那样的L约束,又不会有SGAN的梯度消失问题,实验表明它至少有不逊色于、甚至优于WGAN的表现。

GAN-QP效果图
论文的实验最大做到了512x512的人脸生成(CelebA HQ),充分表明了模型的有效性(效果不算完美,但是模型特别简单)。有兴趣的朋友,欢迎继续阅读下去。
11
Dec
从动力学角度看优化算法(六):为什么SimSiam不退化?
By 苏剑林 | 2020-12-11 | 88801位读者 | 引用自SimCLR以来,CV中关于无监督特征学习的工作层出不穷,让人眼花缭乱。这些工作大多数都是基于对比学习的,即通过适当的方式构造正负样本进行分类学习的。然而,在众多类似的工作中总有一些特立独行的研究,比如Google的BYOL和最近的SimSiam,它们提出了单靠正样本就可以完成特征学习的方案,让人觉得耳目一新。但是没有负样本的支撑,模型怎么不会退化(坍缩)为一个没有意义的常数模型呢?这便是这两篇论文最值得让人思考和回味的问题了。
其中SimSiam给出了让很多人都点赞的答案,但笔者觉得SimSiam也只是把问题换了种说法,并没有真的解决这个问题。笔者认为,像SimSiam、GAN等模型的成功,很重要的原因是使用了基于梯度的优化器(而非其他更强或者更弱的优化器),所以不结合优化动力学的答案都是不完整的。在这里,笔者尝试结合动力学来分析SimSiam不会退化的原因。
SimSiam
在看SimSiam之前,我们可以先看看BYOL,来自论文《Bootstrap your own latent: A new approach to self-supervised Learning》,其学习过程很简单,就是维护两个编码器Student和Teacher,其中Teacher是Student的滑动平均,Student则又反过来向Teacher学习,有种“左脚踩右脚”就可以飞起来的感觉。示意图如下:
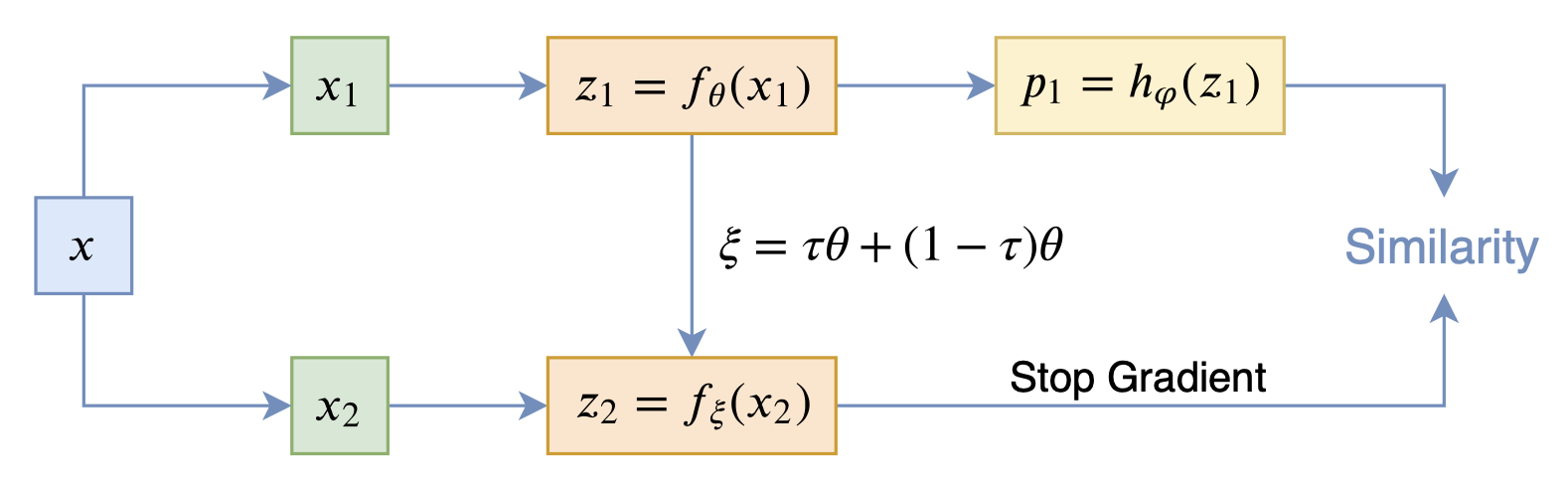
BYOL示意图
24
Aug
隐藏在动量中的梯度累积:少更新几步,效果反而更好?
By 苏剑林 | 2021-08-24 | 35140位读者 | 引用我们知道,梯度累积是在有限显存下实现大batch_size训练的常用技巧。在之前的文章《用时间换取效果:Keras梯度累积优化器》中,我们就简单介绍过梯度累积的实现,大致的思路是新增一组参数来缓存梯度,最后用缓存的梯度来更新模型。美中不足的是,新增一组参数会带来额外的显存占用。
这几天笔者在思考优化器的时候,突然意识到:梯度累积其实可以内置在带动量的优化器中!带着这个思路,笔者对优化了进行了一些推导和实验,最后还得到一个有意思但又有点反直觉的结论:少更新几步参数,模型最终效果可能会变好!
注:本文下面的结果,几乎原封不动且没有引用地出现在Google的论文《Combined Scaling for Zero-shot Transfer Learning》中,在此不做过多评价,请读者自行品评。
SGDM
在正式讨论之前,我们定义函数
\begin{equation}\chi_{t/k} = \left\{ \begin{aligned}&1,\quad t \equiv 0\,(\text{mod}\, k) \\
&0,\quad t \not\equiv 0\,(\text{mod}\, k)
\end{aligned}\right.\end{equation}
也就是说,$t$是一个整数,当它是$k$的倍数时,$\chi_{t/k}=1$,否则$\chi_{t/k}=0$,这其实就是一个$t$能否被$k$整除的示性函数。在后面的讨论中,我们将反复用到这个函数。
15
Nov
WGAN新方案:通过梯度归一化来实现L约束
By 苏剑林 | 2021-11-15 | 59852位读者 | 引用当前,WGAN主流的实现方式包括参数裁剪(Weight Clipping)、谱归一化(Spectral Normalization)、梯度惩罚(Gradient Penalty),本来则来介绍一种新的实现方案:梯度归一化(Gradient Normalization),该方案出自两篇有意思的论文,分别是《Gradient Normalization for Generative Adversarial Networks》和《GraN-GAN: Piecewise Gradient Normalization for Generative Adversarial Networks》。
有意思在什么地方呢?从标题可以看到,这两篇论文应该是高度重合的,甚至应该是同一作者的。但事实上,这是两篇不同团队的、大致是同一时期的论文,一篇中了ICCV,一篇中了WACV,它们基于同样的假设推出了几乎一样的解决方案,内容重合度之高让我一直以为是同一篇论文。果然是巧合无处不在啊~

最近评论