






21
Dec
从熵不变性看Attention的Scale操作
By 苏剑林 | 2021-12-21 | 132069位读者 | 引用当前Transformer架构用的最多的注意力机制,全称为“Scaled Dot-Product Attention”,其中“Scaled”是因为在Q,K转置相乘之后还要除以一个√d再做Softmax(下面均不失一般性地假设Q,K,V∈Rn×d):
Attention(Q,K,V)=softmax(QK⊤√d)V
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经初步解释了除以√d的缘由。而在这篇文章中,笔者将从“熵不变性”的角度来理解这个缩放操作,并且得到一个新的缩放因子。在MLM的实验显示,新的缩放因子具有更好的长度外推性能。
熵不变性
我们将一般的Scaled Dot-Product Attention改写成
oi=n∑j=1ai,jvj,ai,j=eλqi⋅kjn∑j=1eλqi⋅kj
其中λ是缩放因子,它跟qi,kj无关,但原则上可以跟长度n、维度d等参数有关,目前主流的就是λ=1/√d。
10
Apr
从JL引理看熵不变性Attention
By 苏剑林 | 2023-04-10 | 35697位读者 | 引用在《从熵不变性看Attention的Scale操作》、《熵不变性Softmax的一个快速推导》中笔者提出了熵不变性Softmax,简单来说就是往Softmax之前的Attention矩阵多乘上一个logn,理论上有助于增强长度外推性,其中n是序列长度。logn这个因子让笔者联系到了JL引理(Johnson-Lindenstrauss引理),因为JL引理告诉我们编码n个向量只需要O(logn)的维度就行了,大家都是logn,这两者有没有什么关联呢?
熵不变性
我们知道,熵是不确定性的度量,用在注意力机制中,我们将它作为“集中注意力的程度”。所谓熵不变性,指的是不管序列长度n是多少,我们都要将注意力集中在关键的几个token上,而不要太过分散。为此,我们提出的熵不变性Attention形式为
Attention(Q,K,V)=softmax(log512n√dQK⊤)V
14
Nov
当Batch Size增大时,学习率该如何随之变化?
By 苏剑林 | 2024-11-14 | 37848位读者 | 引用随着算力的飞速进步,有越多越多的场景希望能够实现“算力换时间”,即通过堆砌算力来缩短模型训练时间。理想情况下,我们希望投入n倍的算力,那么达到同样效果的时间则缩短为1/n,此时总的算力成本是一致的。这个“希望”看上去很合理和自然,但实际上并不平凡,即便我们不考虑通信之类的瓶颈,当算力超过一定规模或者模型小于一定规模时,增加算力往往只能增大Batch Size。然而,增大Batch Size一定可以缩短训练时间并保持效果不变吗?
这就是接下来我们要讨论的话题:当Batch Size增大时,各种超参数尤其是学习率该如何调整,才能保持原本的训练效果并最大化训练效率?我们也可以称之为Batch Size与学习率之间的Scaling Law。
方差视角
直觉上,当Batch Size增大时,每个Batch的梯度将会更准,所以步子就可以迈大一点,也就是增大学习率,以求更快达到终点,缩短训练时间,这一点大体上都能想到。问题就是,增大多少才是最合适的呢?
29
Jul
基于GRU和AM-Softmax的句子相似度模型
By 苏剑林 | 2018-07-29 | 357435位读者 | 引用搞计算机视觉的朋友会知道,AM-Softmax是人脸识别中的成果。所以这篇文章就是借鉴人脸识别的做法来做句子相似度模型,顺便介绍在Keras下各种margin loss的写法。
背景
细想之下会发现,句子相似度与人脸识别有很多的相似之处~
已有的做法
在我搜索到的资料中,深度学习做句子相似度模型,就只有两种做法:一是输入一对句子,然后输出一个0/1标签代表相似程度,也就是视为一个二分类问题,比如《Learning Text Similarity with Siamese Recurrent Networks》中的模型是这样的

将句子相似度视为二分类模型
包括今年拍拍贷的“魔镜杯”,也是这种格式。另外一种做法是输入一个三元组“(句子A,跟A相似的句子,跟A不相似的句子)”,然后用triplet loss的做法解决,比如文章《Applying Deep Learning To Answer Selection: A Study And An Open Task》中的做法。
这两种做法其实也可以看成是一种,本质上是一样的,只不过loss和训练方法有所差别。但是,这两种方法却都有一个很严重的问题:负样本采样严重不足,导致效果提升非常慢。
26
Dec
【学习清单】最近比较重要的GAN进展论文
By 苏剑林 | 2018-12-26 | 69861位读者 | 引用这篇文章简单列举一下我认为最近这段时间中比较重要的GAN进展论文,这基本也是我在学习GAN的过程中主要去研究的论文清单。
生成模型之味
GAN是一个大坑,尤其像我这样的业余玩家,一头扎进去很久也很难有什么产出,尤其是各个大公司拼算力搞出来一个个大模型,个人几乎都没法玩了。但我总觉得,真的去碰了生成模型,才觉得自己碰到了真正的机器学习。这一点,不管在图像中还是文本中都是如此。所以,我还是愿意去关注生成模型。
当然,GAN不是生成模型的唯一选择,却是一个非常有趣的选择。在图像中至少有GAN、flow、pixelrnn/pixelcnn这几种选择,但要说潜力,我还是觉得GAN才是最具前景的,不单是因为效果,主要是因为它那对抗的思想。而在文本中,事实上seq2seq机制就是一个概率生成模型了,而pixelrnn这类模型,实际上就是模仿着seq2seq来做的,当然也有用GAN做文本生成的研究(不过基本上都涉及到了强化学习)。也就是说,其实在NLP中,生成模型也有很多成果,哪怕你主要是研究NLP的,也终将碰到生成模型。
好了,话不多说,还是赶紧把清单列一列,供大家参考,也作为自己的备忘。
3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 280305位读者 | 引用在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
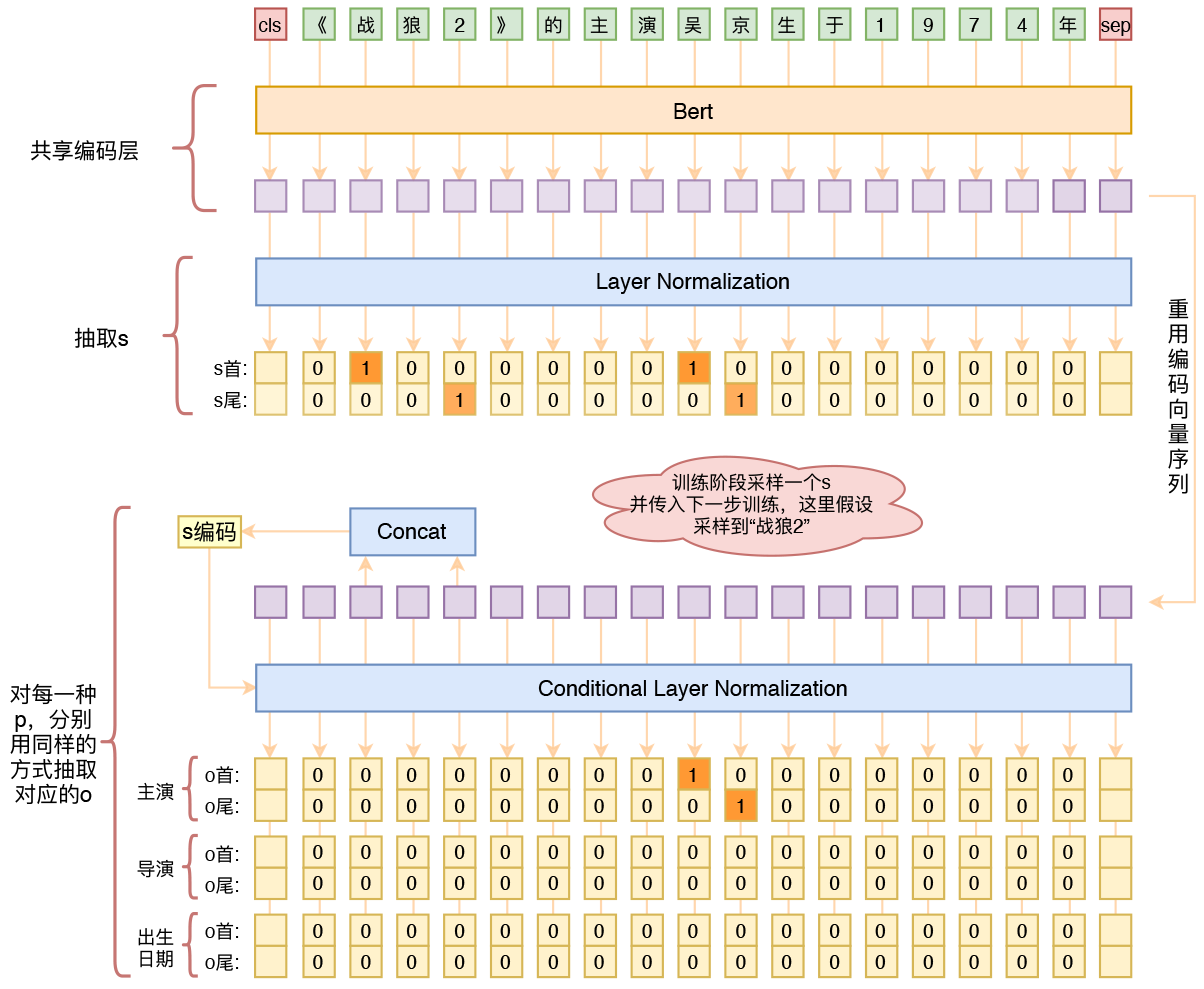
基于Bert的三元组抽取模型结构示意图
18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 456438位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
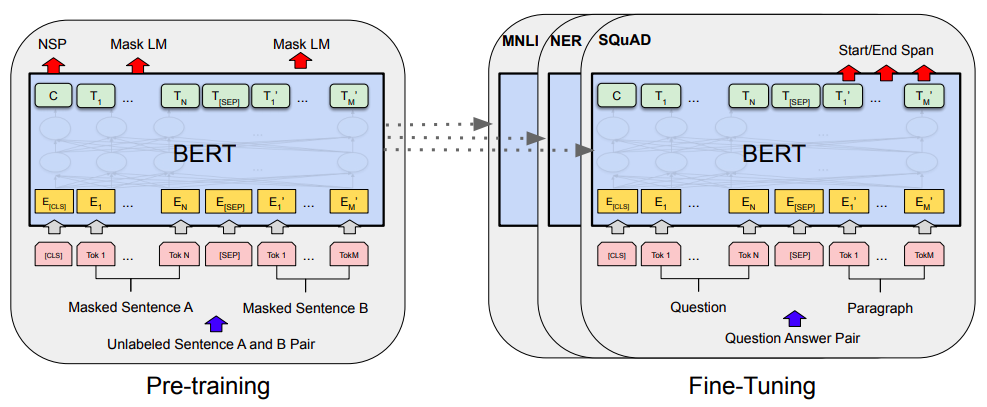
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
11
Dec
从动力学角度看优化算法(六):为什么SimSiam不退化?
By 苏剑林 | 2020-12-11 | 89212位读者 | 引用自SimCLR以来,CV中关于无监督特征学习的工作层出不穷,让人眼花缭乱。这些工作大多数都是基于对比学习的,即通过适当的方式构造正负样本进行分类学习的。然而,在众多类似的工作中总有一些特立独行的研究,比如Google的BYOL和最近的SimSiam,它们提出了单靠正样本就可以完成特征学习的方案,让人觉得耳目一新。但是没有负样本的支撑,模型怎么不会退化(坍缩)为一个没有意义的常数模型呢?这便是这两篇论文最值得让人思考和回味的问题了。
其中SimSiam给出了让很多人都点赞的答案,但笔者觉得SimSiam也只是把问题换了种说法,并没有真的解决这个问题。笔者认为,像SimSiam、GAN等模型的成功,很重要的原因是使用了基于梯度的优化器(而非其他更强或者更弱的优化器),所以不结合优化动力学的答案都是不完整的。在这里,笔者尝试结合动力学来分析SimSiam不会退化的原因。
SimSiam
在看SimSiam之前,我们可以先看看BYOL,来自论文《Bootstrap your own latent: A new approach to self-supervised Learning》,其学习过程很简单,就是维护两个编码器Student和Teacher,其中Teacher是Student的滑动平均,Student则又反过来向Teacher学习,有种“左脚踩右脚”就可以飞起来的感觉。示意图如下:
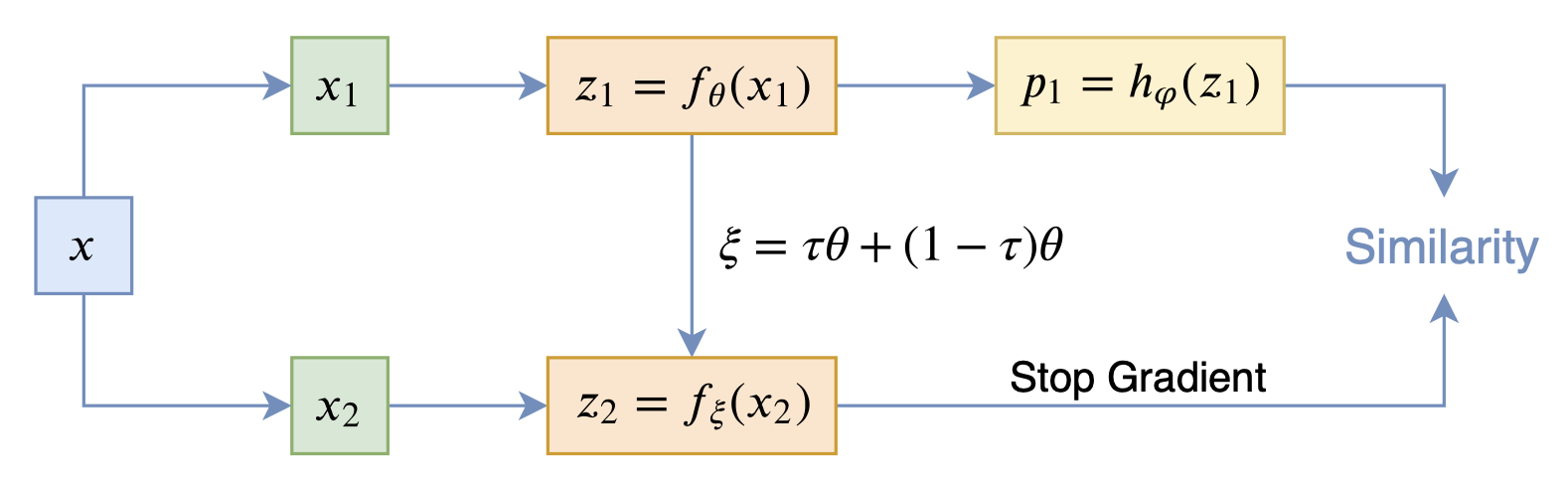
BYOL示意图

最近评论