






20
Feb
熵的形象来源与熵的妙用
By 苏剑林 | 2016-02-20 | 30839位读者 | 引用在拙作《“熵”不起:从熵、最大熵原理到最大熵模型(一)》中,笔者从比较“专业”的角度引出了熵,并对熵做了诠释。当然,熵作为不确定性的度量,应该具有更通俗、更形象的来源,本文就是试图补充这一部分,并由此给出一些妙用。
熵的形象来源
我们考虑由0-9这十个数字组成的自然数,如果要求小于10000的话,那么很自然有10000个,如果我们说“某个小于10000的自然数”,那么0~9999都有可能出现,那么10000便是这件事的不确定性的一个度量。类似地,考虑$n$个不同元素(可重复使用)组成的长度为$m$的序列,那么这个序列有$n^m$种情况,这时$n^m$也是这件事情的不确定性的度量。
$n^m$是指数形式的,数字可能异常地大,因此我们取了对数,得到$m\log n$,这也可以作为不确定性的度量,它跟我们原来熵的定义是一致的。因为
$$m\log n=-\sum_{i=1}^{n^m} \frac{1}{n^m}\log \frac{1}{n^m}$$
读者可能会疑惑,$n^m$和$m\log n$都算是不确定性的度量,那么究竟是什么原因决定了我们用$m\log n$而不是用$n^m$呢?答案是可加性。取对数后的度量具有可加性,方便我们运算。当然,可加性只是便利的要求,并不是必然的。如果使用$n^m$形式,那么就相应地具有可乘性。
9
Apr
一个非线性差分方程的隐函数解
By 苏剑林 | 2016-04-09 | 40871位读者 | 引用问题来源
笔者经常学习的数学研发论坛曾有一帖讨论下述非线性差分方程的渐近求解:
$$a_{n+1}=a_n+\frac{1}{a_n^2},\, a_1=1$$
原帖子在这里,从这帖子中我获益良多,学习到了很多新技巧。主要思路是通过将两边立方,然后设$x_n=a_n^3$,变为等价的递推问题:
$$x_{n+1}=x_n+3+\frac{3}{x_n}+\frac{1}{x_n^2},\,x_1=1$$
然后可以通过巧妙的技巧得到渐近展开式:
$$x_n = 3n+\ln n+a+\frac{\frac{1}{3}(\ln n+a)-\frac{5}{18}}{n}+\dots$$
具体过程就不提了,读者可以自行到上述帖子学习。
然而,这种形式的解虽然精妙,但存在一些笔者不是很满意的地方:
1、解是渐近的级数,这就意味着实际上收敛半径为0;
2、是$n^{-k}$形式的解,对于较小的$n$难以计算,这都使得高精度计算变得比较困难;
3、当然,题目本来的目的是渐近计算,但是渐近分析似乎又没有必要展开那么多项;
4、里边带有了一个本来就比较难计算的极限值$a$;
5、求解过程似乎稍欠直观。
当然,上面这些缺点,有些是鸡蛋里挑骨头的。不过,也正是这些缺点,促使我寻找更好的形式的解,最终导致了这篇文章。
15
May
Coming Back...
By 苏剑林 | 2016-05-15 | 37898位读者 | 引用上一篇博文的发布时间是4月15日,到今天刚好一个月没更新了,但是科学空间的访问量还在。感谢大家对本空间的支持,BoJone对久未更新表示非常抱歉。在恢复更新之前,请允许笔者记记流水账。
在“消失”的一个月中,笔者主要的事情是毕业论文和数据挖掘竞赛。首先毕业论文方面,论文于4月22日交稿,4月29日答辩,答辩完后就意味着毕业论文的事情结束了。我的毕业论文主要写了路径积分在描述随机游走、偏微分方程、随机微分方程的应用。既然是本科论文,就不能说得太晦涩,因此论文整体来看还是比较易读的,可以作为路径积分的入门教程。后面我会略加修改,分开几部分发布在科学空间中的,到时请大家批评指正。
说到路径积分,不得不说到做《量子力学与路径积分》的习题解答这件事情了。很遗憾,这一个多月来,基本没有时间做习题。不过后面我会继续做下去的,已发布的版本,也请有兴趣的读者指出问题。记得年初的时候,朋友问我今年的愿望是什么,我随意地回答了“希望做完一本书的习题”,这本书,当然就是《量子力学与路径积分》了,我相信今年应该能够完成的。
30
May
路径积分系列:1.我的毕业论文
By 苏剑林 | 2016-05-30 | 28119位读者 | 引用之前承诺过会把毕业论文共享出来,让大家批评指正,却一直偷懒没动。事实上,毕业论文的主要内容就是路径积分的一些入门级别的内容,标题为《随机游走、随机微分方程与偏微分方程的路径积分方法》。我的摘要是这样写的:
本文从随机游走模型出发,得到了关于随机游走模型的一般结果;然后基于随机游走模型引入了路径积分,并且通过路径积分方法,实现了随机游走、随机微分方程与抛物型微分方程的相互转化,并给出了一些计算案例.
路径积分方法是量子理论的一种形式,但实际上它可以抽象为一个有用的数学工具,本文的主要方法正是抽象后的路径积分;其次,量子力学中有一个相当典型的抛物型偏微分方程——薛定谔方程,物理学家已经对它进行了大量的研究,有众多的成果;而随机微分方程是一个微分方程的拓展,在物理、工程、金融等很多方面都有重要应用,这个领域中也有很多研究方法;最后,随机游走是一个简单而重要的模型,它是很多扩散模型的基础,而且具有容易使用计算机模拟的特性. 因此,实现三者的转化是很有意义的.
本文有一些新的内容,比如现有文献比较少研究的不对称随机游走方面、以及现有文献比较含糊的对路径积分的介绍等,可以供同好参考,希望借此方式,能够让一些读者以更简洁明了的方式理解路径积分. 但是本文主要是陈述性的,旨在在国内推广路径积分方法. 在国外,路径积分方法得到了相当的重视,它源于量子力学,但应用已经不仅仅限于量子力学,如著作[1],因此,推广路径积分方法、增加路径积分的中文资料,是很有意义和很有必要的事情.
本文所有推导和例子均以一维为例,相应的多维问题可以类似地计算。
18
Jun
OCR技术浅探:3. 特征提取(2)
By 苏剑林 | 2016-06-18 | 38147位读者 | 引用
9
Jun
路径积分系列:5.例子和综述
By 苏剑林 | 2016-06-09 | 22131位读者 | 引用路径积分方法为解决某些随机问题带来了新视角.
一个例子:股票价格模型
考虑有风险资产(如股票),在$t$时刻其价格为$S_t$,考虑的时间区间为$[0,T]$,0表示初始时间,$T$表示为到期日. $S_t$看作是随时间变化的连续时间变量,并服从下列随机微分方程:
$$dS_t^0=rS_t^0 dt;\quad dS_t=S_t(\mu dt+\sigma dW_t).\tag{70}$$
其中,$\mu$和$\sigma$是两个常量,$W_t$是一个标准布朗运动.
关于$S_t$的方程是一个随机微分方程,一般解决思路是通过随机微积分. 随机微积分有别于一般的微积分的地方在于,随机微积分在做一阶展开的时候,不能忽略$dS_t^2$项,因为$dW_t^2=dt$. 比如,设$S_t=e^{x_t}$,则$x_t=\ln S_t$
$$\begin{aligned}dx_t=&\ln(S_t+dS_t)-\ln S_t=\frac{dS_t}{S_t}-\frac{dS_t^2}{2S_t^2}\\
=&\frac{S_t(\mu dt+\sigma dW_t)}{S_t}-\frac{[S_t(\mu dt+\sigma dW_t)]^2}{2S_t^2}\\
=&\mu dt+\sigma dW_t-\frac{1}{2}\sigma^2 dW_t^2\quad(\text{其余项均低于}dt\text{阶})\\
=&\left(\mu-\frac{1}{2}\sigma^2\right) dt+\sigma dW_t\end{aligned}
,\tag{71}$$
18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 55120位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
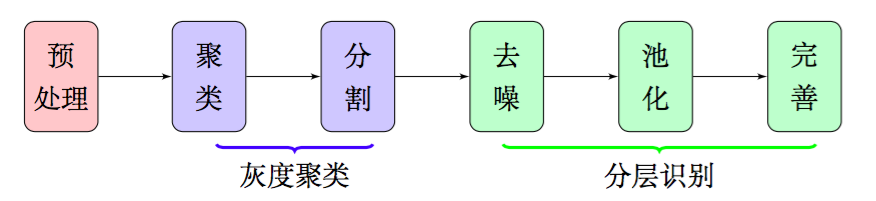
图2:特征提取大概流程
24
Jun
OCR技术浅探:4. 文字定位
By 苏剑林 | 2016-06-24 | 39989位读者 | 引用经过第一部分,我们已经较好地提取了图像的文本特征,下面进行文字定位. 主要过程分两步:1、邻近搜索,目的是圈出单行文字;2、文本切割,目的是将单行文本切割为单字.
邻近搜索
我们可以对提取的特征图进行连通区域搜索,得到的每个连通区域视为一个汉字. 这对于大多数汉字来说是适用,但是对于一些比较简单的汉字却不适用,比如“小”、“旦”、“八”、“元”这些字,由于不具有连通性,所以就被分拆开了,如图13. 因此,我们需要通过邻近搜索算法,来整合可能成字的区域,得到单行的文本区域.

图13 直接搜索连通区域,会把诸如“元”之类的字分拆开
邻近搜索的目的是进行膨胀,以把可能成字的区域“粘合”起来. 如果不进行搜索就膨胀,那么膨胀是各个方向同时进行的,这样有可能把上下行都粘合起来了. 因此,我们只允许区域向单一的一个方向膨胀. 我们正是要通过搜索邻近区域来确定膨胀方向(上、下、左、右):
邻近搜索* 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向.
既然涉及到了邻近,那么就需要有距离的概念. 下面给出一个比较合理的距离的定义.
距离
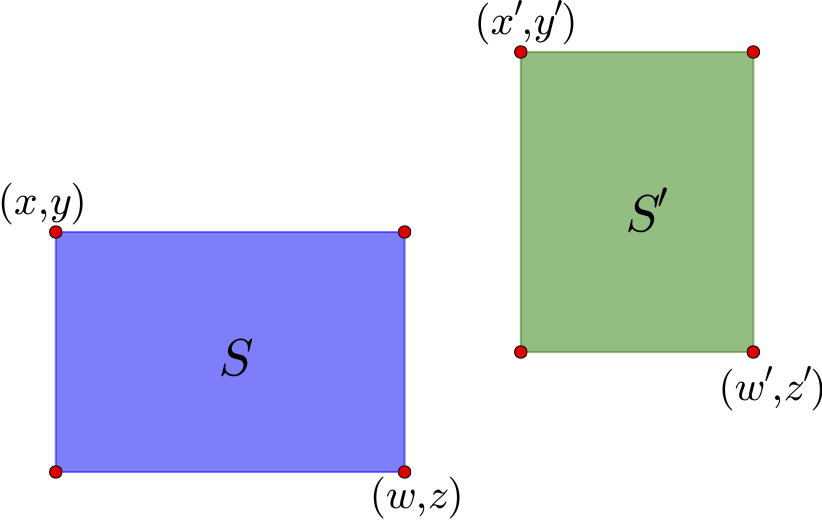
图14 两个示例区域
如上图,通过左上角坐标$(x,y)$和右下角坐标$(z,w)$就可以确定一个矩形区域,这里的坐标是以左上角为原点来算的. 这个区域的中心是$\left(\frac{x+w}{2},\frac{y+z}{2}\right)$. 对于图中的两个区域$S$和$S'$,可以计算它们的中心向量差
$$(x_c,y_c)=\left(\frac{x'+w'}{2}-\frac{x+w}{2},\frac{y'+z'}{2}-\frac{y+z}{2}\right)\tag{10}$$
如果直接使用$\sqrt{x_c^2+y_c^2}$作为距离是不合理的,因为这里的邻近应该是按边界来算,而不是中心点. 因此,需要减去区域的长度:
$$(x'_c,y'_c)=\left(x_c-\frac{w-x}{2}-\frac{w'-x'}{2},y_c-\frac{z-y}{2}-\frac{z'-y'}{2}\right)\tag{11}$$
距离定义为
$$d(S,S')=\sqrt{[\max(x'_c,0)]^2+[\max(y'_c,0)]^2}\tag{12}$$
至于方向,由$(x_c,y_c)$的幅角进行判断即可.
然而,按照前面的“邻近搜索*”方法,容易把上下两行文字粘合起来,因此,基于我们的横向排版假设,更好的方法是只允许横向膨胀:
邻近搜索 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向,当且仅当所在方向是水平的,才执行膨胀操作.
结果
有了距离之后,我们就可以计算每两个连通区域之间的距离,然后找出最邻近的区域. 我们将每个区域向它最邻近的区域所在的方向扩大4分之一,这样邻近的区域就有可能融合为一个新的区域,从而把碎片整合.
实验表明,邻近搜索的思路能够有效地整合文字碎片,结果如图15.

图15 通过邻近搜索后,圈出的文字区域

最近评论