






21
Dec
从动力学角度看优化算法(七):SGD ≈ SVM?
By 苏剑林 | 2020-12-21 | 35417位读者 | 引用众所周知,在深度学习之前,机器学习是SVM(Support Vector Machine,支持向量机)的天下,曾经的它可谓红遍机器学习的大江南北,迷倒万千研究人员,直至今日,“手撕SVM”仍然是大厂流行的面试题之一。然而,时过境迁,当深度学习流行起来之后,第一个革的就是SVM的命,现在只有在某些特别追求效率的场景以及大厂的面试题里边,才能看到SVM的踪迹了。
峰回路转的是,最近Arxiv上的一篇论文《Every Model Learned by Gradient Descent Is Approximately a Kernel Machine》做了一个非常“霸气”的宣言:
任何由梯度下降算法学出来的模型,都是可以近似看成是一个SVM!
这结论真不可谓不“霸气”,因为它已经不只是针对深度学习了,而是只要你用梯度下降优化的,都不过是一个SVM(的近似)。笔者看了一下原论文的分析,感觉确实挺有意思也挺合理的,有助于加深我们对很多模型的理解,遂跟大家分享一下。
7
Jan
【搜出来的文本】⋅(一)从文本生成到搜索采样
By 苏剑林 | 2021-01-07 | 60270位读者 | 引用最近,笔者入了一个新坑:基于离散优化的思想做一些文本生成任务。简单来说,就是把我们要生成文本的目标量化地写下来,构建一个分布,然后搜索这个分布的最大值点或者从这个分布中进行采样,这个过程通常不需要标签数据的训练。由于语言是离散的,因此梯度下降之类的连续函数优化方法不可用,并且由于这个分布通常没有容易采样的形式,直接采样也不可行,因此需要一些特别设计的采样算法,比如拒绝采样(Rejection Sampling)、MCMC(Markov Chain Monte Carlo)、MH采样(Metropolis-Hastings Sampling)、吉布斯采样(Gibbs Sampling),等等。
有些读者可能会觉得有些眼熟,似乎回到了让人头大的学习LDA(Latent Dirichlet Allocation)的那些年?没错,上述采样算法其实也是理解LDA模型的必备基础。本文我们就来回顾这些形形色色的采样算法,它们将会出现在后面要介绍的丰富的文本生成应用中。
22
Apr
Transformer升级之路:3、从Performer到线性Attention
By 苏剑林 | 2021-04-22 | 53860位读者 | 引用看过笔者之前的文章《线性Attention的探索:Attention必须有个Softmax吗?》和《Performer:用随机投影将Attention的复杂度线性化》的读者,可能会觉得本文的标题有点不自然,因为是先有线性Attention然后才有Performer的,它们的关系为“Performer是线性Attention的一种实现,在保证线性复杂度的同时保持了对标准Attention的近似”,所以正常来说是“从线性Attention到Performer”才对。
然而,本文并不是打算梳理线性Attention的发展史,而是打算反过来思考Performer给线性Attention所带来的启示,所以是“从Performer到线性Attention”。
激活函数
线性Attention的常见形式是
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})_i = \frac{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)} = \frac{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)}\end{equation}
5
Jun
从一个单位向量变换到另一个单位向量的正交矩阵
By 苏剑林 | 2021-06-05 | 41778位读者 | 引用这篇文章我们来讨论一个比较实用的线性代数问题:
给定两个$d$维单位(列)向量$\boldsymbol{a},\boldsymbol{b}$,求一个正交矩阵$\boldsymbol{T}$,使得$\boldsymbol{b}=\boldsymbol{T}\boldsymbol{a}$。
由于两个向量模长相同,所以很显然这样的正交矩阵必然存在,那么,我们怎么把它找出来呢?
二维
不难想象,这本质上就是$\boldsymbol{a},\boldsymbol{b}$构成的二维子平面下的向量变换(比如旋转或者镜面反射)问题,所以我们先考虑$d=2$的情形。
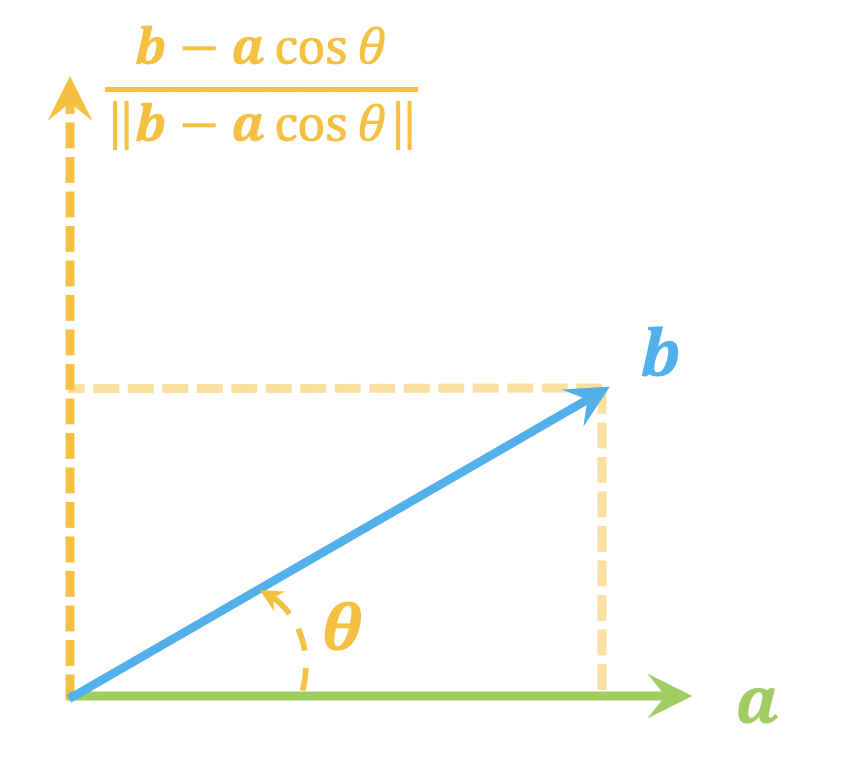
正交分解示意图
21
Dec
从熵不变性看Attention的Scale操作
By 苏剑林 | 2021-12-21 | 111177位读者 | 引用当前Transformer架构用的最多的注意力机制,全称为“Scaled Dot-Product Attention”,其中“Scaled”是因为在$Q,K$转置相乘之后还要除以一个$\sqrt{d}$再做Softmax(下面均不失一般性地假设$Q,K,V\in\mathbb{R}^{n\times d}$):
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{QK^{\top}}{\sqrt{d}}\right)V\label{eq:std}\end{equation}
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经初步解释了除以$\sqrt{d}$的缘由。而在这篇文章中,笔者将从“熵不变性”的角度来理解这个缩放操作,并且得到一个新的缩放因子。在MLM的实验显示,新的缩放因子具有更好的长度外推性能。
熵不变性
我们将一般的Scaled Dot-Product Attention改写成
\begin{equation}\boldsymbol{o}_i = \sum_{j=1}^n a_{i,j}\boldsymbol{v}_j,\quad a_{i,j}=\frac{e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}{\sum\limits_{j=1}^n e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}\end{equation}
其中$\lambda$是缩放因子,它跟$\boldsymbol{q}_i,\boldsymbol{k}_j$无关,但原则上可以跟长度$n$、维度$d$等参数有关,目前主流的就是$\lambda=1/\sqrt{d}$。
25
May
从重参数的角度看离散概率分布的构建
By 苏剑林 | 2022-05-25 | 15766位读者 | 引用一般来说,神经网络的输出都是无约束的,也就是值域为$\mathbb{R}$,而为了得到有约束的输出,通常是采用加激活函数的方式。例如,如果我们想要输出一个概率分布来代表每个类别的概率,那么通常在最后加上Softmax作为激活函数。那么一个紧接着的疑问就是:除了Softmax,还有什么别的操作能生成一个概率分布吗?
在《漫谈重参数:从正态分布到Gumbel Softmax》中,我们介绍了Softmax的重参数操作,本文将这个过程反过来,即先定义重参数操作,然后去反推对应的概率分布,从而得到一个理解概率分布构建的新视角。
问题定义
假设模型的输出向量为$\boldsymbol{\mu}=[\mu_1,\cdots,\mu_n]\in\mathbb{R}^n$,不失一般性,这里假设$\mu_i$两两不等。我们希望通过某个变换$\mathcal{T}$将$\boldsymbol{\mu}$转换为$n$元概率分布$\boldsymbol{p}=[p_1,\cdots,p_n]$,并保持一定的性质。比如,最基本的要求是:
\begin{equation}{\color{red}1.}\,p_i\geq 0 \qquad {\color{red}2.}\,\sum_i p_i = 1 \qquad {\color{red}3.}\,p_i \geq p_j \Leftrightarrow \mu_i \geq \mu_j\end{equation}
7
Dec
从局部到全局:语义相似度的测地线距离
By 苏剑林 | 2022-12-07 | 29765位读者 | 引用前段时间在最近的一篇论文《Unsupervised Opinion Summarization Using Approximate Geodesics》中学到了一个新的概念,叫做“测地线距离(Geodesic Distance)”,感觉有点意思,特来跟大家分享一下。
对笔者来说,“新”的不是测地线距离概念本身(以前学黎曼几何的时候就已经接触过了),而是语义相似度领域原来也可以巧妙地构造出测地线距离出来,并在某些场景下发挥作用。如果乐意,我们还可以说这是“流形上的语义相似度”,是不是瞬间就高级了不少?
论文梗概
首先,我们简单总结一下原论文的主要内容。顾名思义,论文的主题是摘要,通常我们的无监督摘要是这样做的:假设文章由$n$个句子$t_1,t_2,\cdots,t_n$组成,给每个句子设计打分函数$s(t_i)$(经典的是tf-idf及其变体),然后挑出打分最大的若干个句子作为摘要。当然,论文做的不是简单的摘要,而是“Opinion Summarization”,这个“Opinion”,我们可以理解为实现给定的主题或者中心$c$,摘要应该倾向于抽取出与$c$相关的句子,所以打分函数应该还应该跟$c$有关,即$s(t_i, c)$。
18
Oct
生成扩散模型漫谈(十三):从万有引力到扩散模型
By 苏剑林 | 2022-10-18 | 51588位读者 | 引用对于很多读者来说,生成扩散模型可能是他们遇到的第一个能够将如此多的数学工具用到深度学习上的模型。在这个系列文章中,我们已经展示了扩散模型与数学分析、概率统计、常微分方程、随机微分方程乃至偏微分方程等内容的深刻联系,可以说,即便是做数学物理方程的纯理论研究的同学,大概率也可以在扩散模型中找到自己的用武之地。
在这篇文章中,我们再介绍一个同样与数学物理有深刻联系的扩散模型——由“万有引力定律”启发的ODE式扩散模型,出自论文《Poisson Flow Generative Models》(简称PFGM),它给出了一个构建ODE式扩散模型的全新视角。
万有引力
中学时期我们就学过万有引力定律,大概的描述方式是:
两个质点彼此之间相互吸引的作用力,是与它们的质量乘积成正比,并与它们之间的距离成平方反比。

最近评论