






14
Oct
【理解黎曼几何】2. 从勾股定理到黎曼度量
By 苏剑林 | 2016-10-14 | 73063位读者 | 引用黎曼度量
几何,英文名是Geometry,原意是大地测量。既然是测量,就必须有参考物,还有得知道如何计算距离。
有了参照物,我们就可以建立坐标系,把每个点的坐标都写下来,至于计算距离,我们有伟大的勾股定理:
$$ds^2 = dx^2 + dy^2 \tag{1} $$
但这里我们忽略了两个问题。
第一个问题是,我们不一定使用直角坐标系,如果使用极坐标,那么应该是
$$ds^2 = dr^2 + r^2 d\theta^2 \tag{2} $$
因此可以联想,最一般的形式应该是
$$ds^2 = E(x^1, x^2)(dx^1)^2 + 2F(x^1, x^2)dx^1 dx^2 + G(x^1, x^2)(dx^2)^2 \tag{3} $$
这里的$x^1,x^2$是广义坐标,使用上标而不是下标来标记序号,是为了跟传统的教材记号一致。那这公式是什么意思呢?其实很简单,正如我们没理由要求全世界都使用人民币一样,我们没必要要求世界各地都使用同一个坐标系,而更合理的做法是,每一处地方都使用自己的坐标系(局部坐标系),然后给出当地计算距离的方法。因此,上述公式正是说,在位置$(x^1, x^2)$处计算向量$(dx^1, dx^2)$的长度的公式(当地的勾股定理)是$ds^2 = E(x^1, x^2)(dx^1)^2 + 2F(x_1, x_2)dx^1 dx^2 + G(x^1, x^2)(dx^2)^2$。
8
Jun
互怼的艺术:从零直达WGAN-GP
By 苏剑林 | 2017-06-08 | 277425位读者 | 引用前言
GAN,全称Generative Adversarial Nets,中文名是生成对抗式网络。对于GAN来说,最通俗的解释就是“伪造者-鉴别者”的解释,如艺术画的伪造者和鉴别者。一开始伪造者和鉴别者的水平都不高,但是鉴别者还是比较容易鉴别出伪造者伪造出来的艺术画。但随着伪造者对伪造技术的学习后,其伪造的艺术画会让鉴别者识别错误;或者随着鉴别者对鉴别技术的学习后,能够很简单的鉴别出伪造者伪造的艺术画。这是一个双方不断学习技术,以达到最高的伪造和鉴别水平的过程。 然而,稍微深入了解的读者就会发现,跟现实中的造假者不同,造假者会与时俱进地使用新材料新技术来造假,而GAN最神奇而又让人困惑的地方是它能够将随机噪声映射为我们所希望的正样本,有噪声就有正样本,这不是无本生意吗,多划算~
另一个情况是,自从WGAN提出以来,基本上GAN的主流研究都已经变成了WGAN上去了,但WGAN的形式事实上已经跟“伪造者-鉴别者”差得比较远了。而且WGAN虽然最后的形式并不复杂,但是推导过程却用到了诸多复杂的数学,使得我无心研读原始论文。这迫使我要找从一条简明直观的线索来理解GAN。幸好,经过一段时间的思考,有点收获。
7
Jul
从SamplePairing到mixup:神奇的正则项
By 苏剑林 | 2018-07-07 | 76224位读者 | 引用SamplePairing和mixup是两种一脉相承的图像数据扩增手段,它们看起来很不合理,而操作则非常简单,但结果却非常漂亮:在多个图像分类任务中都表明它们能提高最终分类模型的精度。
某些读者会困惑于一个问题:为什么如此不合理的数据扩增手段,能得到如此好的效果?而本文则要表明,它们看起来是一种数据扩增方法,事实上它们是对模型的一种正则化方案。正如周星驰的电影《国产凌凌漆》的一句经典台词:
表面上看这是一个吹风机,其实它是一个刮胡刀。
数据扩增
让我们从数据扩增说起。数据扩增是指我们在对原始数据做一些简单的变换后,它们对应的类别往往不会变化,所以我们可以在原来数据的基础上,“造”出更多的数据来。比如一幅小狗的照片,将它水平翻转、轻微的旋转、裁剪、平移等操作后,我们认为它的类别没有变化,它还是原来的那只狗。这样一来,从一个样本我们可以衍生出好几个样本,从而增加了训练样本量。

狗

旋转的狗
19
Apr
从DCGAN到SELF-MOD:GAN的模型架构发展一览
By 苏剑林 | 2019-04-19 | 77707位读者 | 引用事实上,O-GAN的发现,已经达到了我对GAN的理想追求,使得我可以很惬意地跳出GAN的大坑了。所以现在我会试图探索更多更广的研究方向,比如NLP中还没做过的任务,又比如图神经网络,又或者其他有趣的东西。
不过,在此之前,我想把之前的GAN的学习结果都记录下来。
这篇文章中,我们来梳理一下GAN的架构发展情况,当然主要的是生成器的发展,判别器一直以来的变动都不大。还有,本文介绍的是GAN在图像方面的模型架构发展,跟NLP的SeqGAN没什么关系。
此外,关于GAN的基本科普,本文就不再赘述了。

棋盘效应图示,体现为放大之后出现如国际象棋棋盘一样的交错效应。图片来自文章《Deconvolution and Checkerboard Artifacts》
18
Sep
从语言模型到Seq2Seq:Transformer如戏,全靠Mask
By 苏剑林 | 2019-09-18 | 313910位读者 | 引用相信近一年来(尤其是近半年来),大家都能很频繁地看到各种Transformer相关工作(比如Bert、GPT、XLNet等等)的报导,连同各种基础评测任务的评测指标不断被刷新。同时,也有很多相关的博客、专栏等对这些模型做科普和解读。
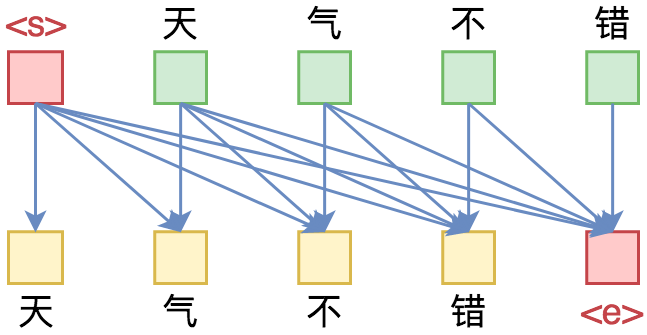
单向语言模型图示。每预测一个token,只依赖于前面的token。
俗话说,“外行看热闹,内行看门道”,我们不仅要在“是什么”这个层面去理解这些工作,我们还需要思考“为什么”。这个“为什么”不仅仅是“为什么要这样做”,还包括“为什么可以这样做”。比如,在谈到XLNet的乱序语言模型时,我们或许已经从诸多介绍中明白了乱序语言模型的好处,那不妨更进一步思考一下:
为什么Transformer可以实现乱序语言模型?是怎么实现的?RNN可以实现吗?
本文从对Attention矩阵进行Mask的角度,来分析为什么众多Transformer模型可以玩得如此“出彩”的基本原因,正如标题所述“Transformer如戏,全靠Mask”,这是各种花式Transformer模型的重要“门道”之一。
读完本文,你或许可以了解到:
1、Attention矩阵的Mask方式与各种预训练方案的关系;
2、直接利用预训练的Bert模型来做Seq2Seq任务。
16
Jan
从几何视角来理解模型参数的初始化策略
By 苏剑林 | 2020-01-16 | 89687位读者 | 引用对于复杂模型来说,参数的初始化显得尤为重要。糟糕的初始化,很多时候已经不单是模型效果变差的问题了,还更有可能是模型根本训练不动或者不收敛。在深度学习中常见的自适应初始化策略是Xavier初始化,它是从正态分布$\mathcal{N}\left(0,\frac{2}{fan_{in} + fan_{out}}\right)$中随机采样而构成的初始权重,其中$fan_{in}$是输入的维度而$fan_{out}$是输出的维度。其他初始化策略基本上也类似,只不过假设有所不同,导致最终形式略有差别。
标准的初始化策略的推导是基于概率统计的,大概的思路是假设输入数据的均值为0、方差为1,然后期望输出数据也保持均值为0、方差为1,然后推导出初始变换应该满足的均值和方差条件。这个过程理论上没啥问题,但在笔者看来依然不够直观,而且推导过程的假设有点多。本文则希望能从几何视角来理解模型的初始化方法,给出一个更直观的推导过程。
信手拈来的正交
前者时间笔者写了《n维空间下两个随机向量的夹角分布》,其中的一个推论是
推论1: 高维空间中的任意两个随机向量几乎都是垂直的。
22
Apr
Transformer升级之路:3、从Performer到线性Attention
By 苏剑林 | 2021-04-22 | 51975位读者 | 引用看过笔者之前的文章《线性Attention的探索:Attention必须有个Softmax吗?》和《Performer:用随机投影将Attention的复杂度线性化》的读者,可能会觉得本文的标题有点不自然,因为是先有线性Attention然后才有Performer的,它们的关系为“Performer是线性Attention的一种实现,在保证线性复杂度的同时保持了对标准Attention的近似”,所以正常来说是“从线性Attention到Performer”才对。
然而,本文并不是打算梳理线性Attention的发展史,而是打算反过来思考Performer给线性Attention所带来的启示,所以是“从Performer到线性Attention”。
激活函数
线性Attention的常见形式是
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})_i = \frac{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)} = \frac{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)}\end{equation}
5
Jun
从一个单位向量变换到另一个单位向量的正交矩阵
By 苏剑林 | 2021-06-05 | 40424位读者 | 引用这篇文章我们来讨论一个比较实用的线性代数问题:
给定两个$d$维单位(列)向量$\boldsymbol{a},\boldsymbol{b}$,求一个正交矩阵$\boldsymbol{T}$,使得$\boldsymbol{b}=\boldsymbol{T}\boldsymbol{a}$。
由于两个向量模长相同,所以很显然这样的正交矩阵必然存在,那么,我们怎么把它找出来呢?
二维
不难想象,这本质上就是$\boldsymbol{a},\boldsymbol{b}$构成的二维子平面下的向量变换(比如旋转或者镜面反射)问题,所以我们先考虑$d=2$的情形。
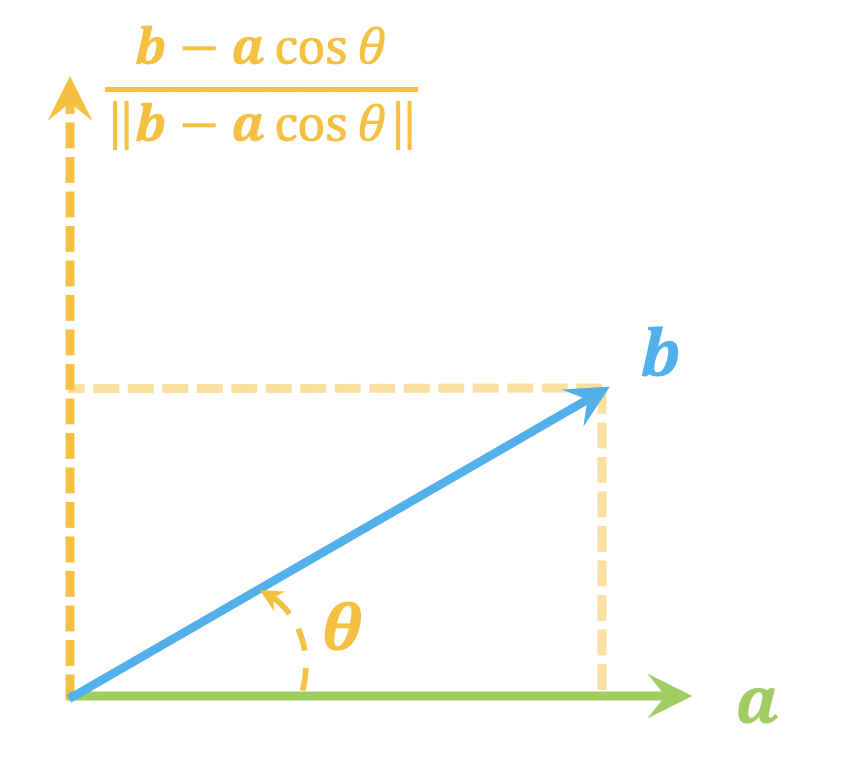
正交分解示意图

最近评论