






17
Sep
变分自编码器(四):一步到位的聚类方案
By 苏剑林 | 2018-09-17 | 372068位读者 | 引用由于VAE中既有编码器又有解码器(生成器),同时隐变量分布又被近似编码为标准正态分布,因此VAE既是一个生成模型,又是一个特征提取器。在图像领域中,由于VAE生成的图片偏模糊,因此大家通常更关心VAE作为图像特征提取器的作用。提取特征都是为了下一步的任务准备的,而下一步的任务可能有很多,比如分类、聚类等。本文来关心“聚类”这个任务。
一般来说,用AE或者VAE做聚类都是分步来进行的,即先训练一个普通的VAE,然后得到原始数据的隐变量,接着对隐变量做一个K-Means或GMM之类的。但是这样的思路的整体感显然不够,而且聚类方法的选择也让我们纠结。本文介绍基于VAE的一个“一步到位”的聚类思路,它同时允许我们完成无监督地完成聚类和条件生成。
理论
一般框架
回顾VAE的loss(如果没印象请参考《变分自编码器(二):从贝叶斯观点出发》):
$$KL\Big(p(x,z)\Big\Vert q(x,z)\Big) = \iint p(z|x)\tilde{p}(x)\ln \frac{p(z|x)\tilde{p}(x)}{q(x|z)q(z)} dzdx\tag{1}$$
通常来说,我们会假设$q(z)$是标准正态分布,$p(z|x),q(x|z)$是条件正态分布,然后代入计算,就得到了普通的VAE的loss。
28
May
ON-LSTM:用有序神经元表达层次结构
By 苏剑林 | 2019-05-28 | 205791位读者 | 引用今天介绍一个有意思的LSTM变种:ON-LSTM,其中“ON”的全称是“Ordered Neurons”,即有序神经元,换句话说这种LSTM内部的神经元是经过特定排序的,从而能够表达更丰富的信息。ON-LSTM来自文章《Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks》,顾名思义,将神经元经过特定排序是为了将层级结构(树结构)整合到LSTM中去,从而允许LSTM能自动学习到层级结构信息。这篇论文还有另一个身份:ICLR 2019的两篇最佳论文之一,这表明在神经网络中融合层级结构(而不是纯粹简单地全向链接)是很多学者共同感兴趣的课题。
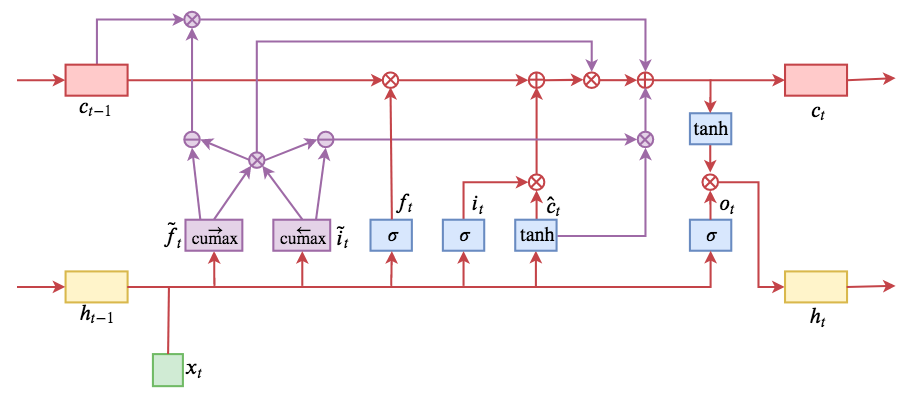
ON-LSTM运算流程示意图。主要是将分段函数用cumax光滑化变成可导。
笔者留意到ON-LSTM是因为机器之心的介绍,里边提到它除了提高了语言模型的效果之外,甚至还可以无监督地学习到句子的句法结构!正是这一点特性深深吸引了我,而它最近获得ICLR 2019最佳论文的认可,更是坚定了我要弄懂它的决心。认真研读、推导了差不多一星期之后,终于有点眉目了,遂写下此文。
在正式介绍ON-LSTM之后,我忍不住要先吐槽一下这篇文章实在是写得太差了,将一个明明很生动形象的设计,讲得异常晦涩难懂,其中的核心是$\tilde{f}_t$和$\tilde{i}_t$的定义,文中几乎没有任何铺垫就贴了出来,也没有多少诠释,开始的读了好几次仍然像天书一样...总之,文章写法实在不敢恭维~
9
Aug
seq2seq之双向解码
By 苏剑林 | 2019-08-09 | 48335位读者 | 引用在文章《玩转Keras之seq2seq自动生成标题》中我们已经基本探讨过seq2seq,并且给出了参考的Keras实现。
本文则将这个seq2seq再往前推一步,引入双向的解码机制,它在一定程度上能提高生成文本的质量(尤其是生成较长文本时)。本文所介绍的双向解码机制参考自《Synchronous Bidirectional Neural Machine Translation》,最后笔者也是用Keras实现的。
背景介绍
研究过seq2seq的读者都知道,常见的seq2seq的解码过程是从左往右逐字(词)生成的,即根据encoder的结果先生成第一个字;然后根据encoder的结果以及已经生成的第一个字,来去生成第二个字;再根据encoder的结果和前两个字,来生成第三个词;依此类推。总的来说,就是在建模如下概率分解
\begin{equation}p(Y|X)=p(y_1|X)p(y_2|X,y_1)p(y_3|X,y_1,y_2)\cdots\label{eq:p}\end{equation}
18
May
鱼与熊掌兼得:融合检索和生成的SimBERT模型
By 苏剑林 | 2020-05-18 | 315283位读者 | 引用前段时间我们开放了一个名为SimBERT的模型权重,它是以Google开源的BERT模型为基础,基于微软的UniLM思想设计了融检索与生成于一体的任务,来进一步微调后得到的模型,所以它同时具备相似问生成和相似句检索能力。不过当时除了放出一个权重文件和示例脚本之外,未对模型原理和训练过程做进一步说明。在这篇文章里,我们来补充这部分内容。
UniLM
UniLM是一个融合NLU和NLG能力的Transformer模型,由微软在去年5月份提出来的,今年2月份则升级到了v2版本。我们之前的文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》就简单介绍过UniLM,并且已经集成到了bert4keras中。
UniLM的核心是通过特殊的Attention Mask来赋予模型具有Seq2Seq的能力。假如输入是“你想吃啥”,目标句子是“白切鸡”,那UNILM将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP],然后接如图的Attention Mask:

UniLM的Mask
16
Jun
如何应对Seq2Seq中的“根本停不下来”问题?
By 苏剑林 | 2020-06-16 | 68526位读者 | 引用在Seq2Seq的解码过程中,我们是逐个token地递归生成的,直到出现<eos>标记为止,这就是所谓的“自回归”生成模型。然而,研究过Seq2Seq的读者应该都能发现,这种自回归的解码偶尔会出现“根本停不下来”的现象,主要是某个片段反复出现,比如“今天天气不错不错不错不错不错...”、“你觉得我说得对不对不对不对不对不对...”等等,但就是死活不出现<eos>标记。ICML 2020的文章《Consistency of a Recurrent Language Model With Respect to Incomplete Decoding》比较系统地讨论了这个现象,并提出了一些对策,本文来简单介绍一下论文的主要内容。
解码算法
对于自回归模型来说,我们建立的是如下的条件语言模型
\begin{equation}p(y_t|y_{\lt t}, x)\label{eq:p}\end{equation}
那么解码算法就是在已知上述模型时,给定$x$来输出对应的$y=(y_1,y_2,\dots,y_T)$来。解码算法大致可以分为两类:确定性解码算法和随机性解码算法,原论文分别针对这两类解码讨论来讨论了“根本停不下来”问题,所以我们需要来了解一下这两类解码算法。
22
Jan
【搜出来的文本】⋅(三)基于BERT的文本采样
By 苏剑林 | 2021-01-22 | 94569位读者 | 引用从这一篇开始,我们就将前面所介绍的采样算法应用到具体的文本生成例子中。而作为第一个例子,我们将介绍如何利用BERT来进行文本随机采样。所谓文本随机采样,就是从模型中随机地产生一些自然语言句子出来,通常的观点是这种随机采样是GPT2、GPT3这种单向自回归语言模型专有的功能,而像BERT这样的双向掩码语言模型(MLM)是做不到的。
事实真的如此吗?当然不是。利用BERT的MLM模型其实也可以完成文本采样,事实上它就是上一篇文章所介绍的Gibbs采样。这一事实首先由论文《BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model》明确指出。论文的标题也颇为有趣:“BERT也有嘴巴,所以它得说点什么。”现在就让我们看看BERT究竟能说出什么来~
26
Jan
Seq2Seq重复解码现象的理论分析尝试
By 苏剑林 | 2021-01-26 | 34308位读者 | 引用去年笔者写过博文《如何应对Seq2Seq中的“根本停不下来”问题?》,里边介绍了一篇论文中对Seq2Seq解码不停止现象的处理,并指出那篇论文只是提了一些应对该问题的策略,并没有提供原理上的理解。近日,笔者在Arixv读到了AAAI 2021的一篇名为《A Theoretical Analysis of the Repetition Problem in Text Generation》的论文,里边从理论上分析了Seq2Seq重复解码现象。从本质上来看,重复解码和解码不停止其实都是同理的,所以这篇新论文算是填补了前面那篇论文的空白。
经过学习,笔者发现该论文确实有不少可圈可点之处,值得一读。笔者对原论文中的分析过程做了一些精简、修正和推广,将结果记录成此文,供大家参考。此外,抛开问题背景不讲,读者也可以将本文当成一节矩阵分析习题课,供大家复习线性代数哈~
16
Feb
Nyströmformer:基于矩阵分解的线性化Attention方案
By 苏剑林 | 2021-02-16 | 49319位读者 | 引用标准Attention的$\mathcal{O}(n^2)$复杂度可真是让研究人员头大。前段时间我们在博文《Performer:用随机投影将Attention的复杂度线性化》中介绍了Google的Performer模型,它通过随机投影的方式将标准Attention转化为线性Attention。无独有偶,前些天Arxiv上放出了AAAI 2021的一篇论文《Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention》,里边又提出了一种从另一个角度把标准Attention线性化的方案。
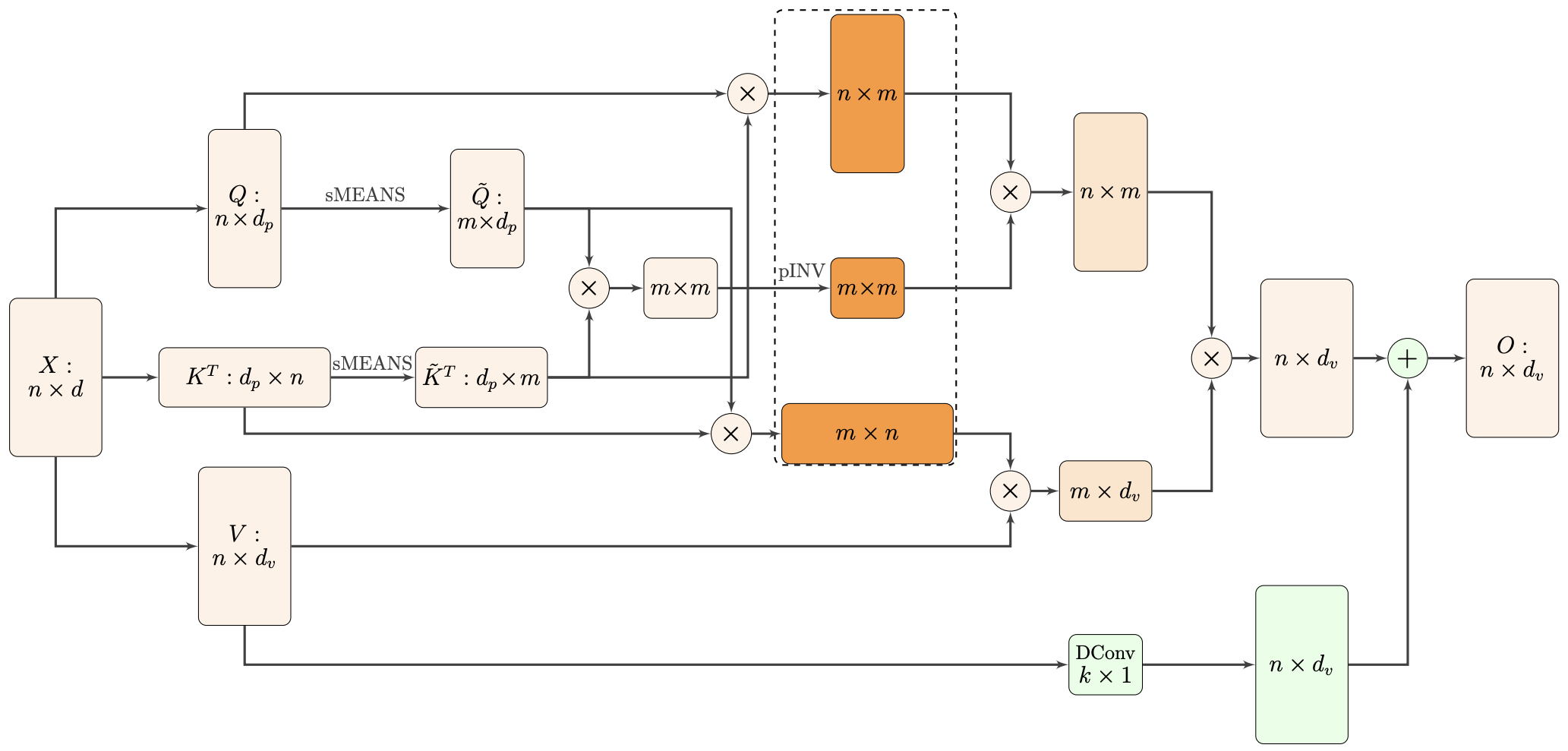
Nyströmformer结构示意图
该方案写的是Nyström-Based,顾名思义是利用了Nyström方法来近似标准Attention的。但是坦白说,在看到这篇论文之前,笔者也完全没听说过Nyström方法,而纵观整篇论文,里边也全是笔者一眼看上去感觉很茫然的矩阵分解推导,理解起来颇为困难。不过有趣的是,尽管作者的推导很复杂,但笔者发现最终的结果可以通过一个相对来说更简明的方式来理解,遂将笔者对Nyströmformer的理解整理在此,供大家参考。

最近评论