






18
Jan
多任务学习漫谈(一):以损失之名
By 苏剑林 | 2022-01-18 | 165115位读者 | 引用能提升模型性能的方法有很多,多任务学习(Multi-Task Learning)也是其中一种。简单来说,多任务学习是希望将多个相关的任务共同训练,希望不同任务之间能够相互补充和促进,从而获得单任务上更好的效果(准确率、鲁棒性等)。然而,多任务学习并不是所有任务堆起来就能生效那么简单,如何平衡每个任务的训练,使得各个任务都尽量获得有益的提升,依然是值得研究的课题。
最近,笔者机缘巧合之下,也进行了一些多任务学习的尝试,借机也学习了相关内容,在此挑部分结果与大家交流和讨论。
加权求和
从损失函数的层面看,多任务学习就是有多个损失函数$\mathcal{L}_1,\mathcal{L}_2,\cdots,\mathcal{L}_n$,一般情况下它们有大量的共享参数、少量的独立参数,而我们的目标是让每个损失函数都尽可能地小。为此,我们引入权重$\alpha_1,\alpha_2,\cdots,\alpha_n\geq 0$,通过加权求和的方式将它转化为如下损失函数的单任务学习
\begin{equation}\mathcal{L} = \sum_{i=1}^n \alpha_i \mathcal{L}_i\label{eq:w-loss}\end{equation}
在这个视角下,多任务学习的主要难点就是如何确定各个$\alpha_i$了。
1
Jun
如何训练你的准确率?
By 苏剑林 | 2022-06-01 | 29267位读者 | 引用最近Arxiv上的一篇论文《EXACT: How to Train Your Accuracy》引起了笔者的兴趣,顾名思义这是介绍如何直接以准确率为训练目标来训练模型的。正好笔者之前也对此有过一些分析,如《函数光滑化杂谈:不可导函数的可导逼近》、《再谈类别不平衡问题:调节权重与魔改Loss的对比联系》等, 所以带着之前的研究经验很快完成了论文的阅读,写下了这篇总结,并附上了最近关于这个主题的一些新思考。
失实的例子
论文开头指出,我们平时用的分类损失函数是交叉熵或者像SVM中的Hinge Loss,这两个损失均不能很好地拟合最终的评价指标准确率。为了说明这一点,论文举了一个很简单的例子:假设数据只有$\{(-0.25,-1),(0,-1),(0.25,,1)\}$三个点,$-1$和$1$分别代表负类和正类,待拟合模型是$f(x)=x-b$,$b$是参数,我们希望通过$\text{sign}(f(x))$来预测类别。如果用“sigmoid + 交叉熵”,那么损失函数就是$-\log \frac{1}{1+e^{-l \cdot f(x)}}$,$(x,l)$代表一对标签数据;如果用Hinge Loss,则是$\max(0, 1 - l\cdot f(x))$。
12
May
Transformer升级之路:9、一种全局长度外推的新思路
By 苏剑林 | 2023-05-12 | 63994位读者 | 引用说到Transformer无法处理超长序列的原因,大家的第一反应通常都是Self Attention的二次复杂度。但事实上,即便忽略算力限制,常规的Transformer也无法处理超长序列,因为它们的长度外推性(Length Extrapolation)并不好,具体表现为当输入序列明显超过训练长度时,模型的效果通常会严重下降。
尽管已有一些相关工作,但长度外推问题离实际解决还比较远。本文介绍笔者构思的一种参考方案,它可能是目前唯一一种可以用在生成模型上、具备全局依赖能力的长度外推方法。
方法回顾
长度外推,也称为长度泛化(Length Generalization),此前我们在《Transformer升级之路:7、长度外推性与局部注意力》、《Transformer升级之路:8、长度外推性与位置鲁棒性》已经介绍过部分工作。然而,它们各有各的问题。
29
May
Transformer升级之路:18、RoPE的底数选择原则
By 苏剑林 | 2024-05-29 | 149072位读者 | 引用我们知道,在RoPE中频率的计算公式为$\theta_i = b^{-2i/d}$,底数$b$默认值为10000。目前Long Context的主流做法之一是,先在$b=10000$上用短文本预训练,然后调大$b$并在长文本微调,其出发点是《Transformer升级之路:10、RoPE是一种β进制编码》里介绍的NTK-RoPE,它本身有较好长度外推性,换用更大的$b$再微调相比不加改动的微调,起始损失更小,收敛也更快。该过程给人的感觉是:调大$b$完全是因为“先短后长”的训练策略,如果一直都用长文本训练似乎就没必要调大$b$了?
上周的论文《Base of RoPE Bounds Context Length》试图回答这个问题,它基于一个期望性质研究了$b$的下界,由此指出更大的训练长度本身就应该选择更大的底数,与训练策略无关。整个分析思路颇有启发性,接下来我们一起来品鉴一番。
1
Oct
低秩近似之路(二):SVD
By 苏剑林 | 2024-10-01 | 19655位读者 | 引用上一篇文章中我们介绍了“伪逆”,它关系到给定矩阵$\boldsymbol{M}$和$\boldsymbol{A}$(或$\boldsymbol{B}$)时优化目标$\Vert \boldsymbol{A}\boldsymbol{B} - \boldsymbol{M}\Vert_F^2$的最优解。这篇文章我们来关注$\boldsymbol{A},\boldsymbol{B}$都不给出时的最优解,即
\begin{equation}\mathop{\text{argmin}}_{\boldsymbol{A},\boldsymbol{B}}\Vert \boldsymbol{A}\boldsymbol{B} - \boldsymbol{M}\Vert_F^2\label{eq:loss-ab}\end{equation}
其中$\boldsymbol{A}\in\mathbb{R}^{n\times r}, \boldsymbol{B}\in\mathbb{R}^{r\times m}, \boldsymbol{M}\in\mathbb{R}^{n\times m},r < \min(n,m)$。说白了,这就是要寻找矩阵$\boldsymbol{M}$的“最优$r$秩近似(秩不超过$r$的最优近似)”。而要解决这个问题,就需要请出大名鼎鼎的“SVD(奇异值分解)”了。虽然本系列把伪逆作为开篇,但它的“名声”远不如SVD,听过甚至用过SVD但没听说过伪逆的应该大有人在,包括笔者也是先了解SVD后才看到伪逆。
接下来,我们将围绕着矩阵的最优低秩近似来展开介绍SVD。
结论初探
对于任意矩阵$\boldsymbol{M}\in\mathbb{R}^{n\times m}$,都可以找到如下形式的奇异值分解(SVD,Singular Value Decomposition):
\begin{equation}\boldsymbol{M} = \boldsymbol{U}\boldsymbol{\Sigma} \boldsymbol{V}^{\top}\end{equation}
24
Oct
VQ的旋转技巧:梯度直通估计的一般推广
By 苏剑林 | 2024-10-24 | 27290位读者 | 引用随着多模态LLM的方兴未艾,VQ(Vector Quantization)的地位也“水涨船高”,它可以作为视觉乃至任意模态的Tokenizer,将多模态数据统一到自回归生成框架中。遗憾的是,自VQ-VAE首次提出VQ以来,其理论并没有显著进步,像编码表的坍缩或利用率低等问题至今仍亟待解决,取而代之的是FSQ等替代方案被提出,成为了VQ有力的“竞争对手”。
然而,FSQ并不能在任何场景下都替代VQ,所以VQ本身的改进依然是有价值的。近日笔者读到了《Restructuring Vector Quantization with the Rotation Trick》,它提出了一种旋转技巧,声称能改善VQ的一系列问题,本文就让我们一起来品鉴一下。
回顾
早在五年前的博文《VQ-VAE的简明介绍:量子化自编码器》中我们就介绍过了VQ-VAE,后来在《简单得令人尴尬的FSQ:“四舍五入”超越了VQ-VAE》介绍FSQ的时候,也再次仔细地温习了VQ-VAE,还不了解的读者可以先阅读这两篇文章。
24
Oct
从费马大定理谈起(十一):有理点与切割线法
By 苏剑林 | 2014-10-24 | 27872位读者 | 引用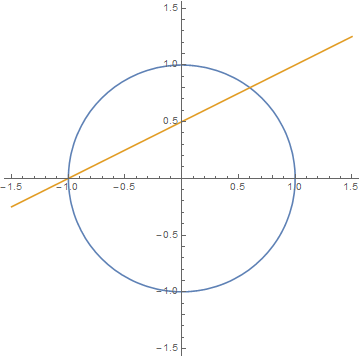
圆上的有理点
我们在这个系列的文章之中,探索了一些有关环和域的基本知识,并用整环以及唯一分解性定理证明了费马大定理在n=3和n=4时的情形。使用高斯整数环或者艾森斯坦整数环的相关知识,相对而言是属于近代的比较“高端”的代数内容(高斯生于1777年,艾森斯坦生于1823年,然而艾森斯坦英年早逝,只活到了1852年,高斯还活到了1855年。)。如果“顺利”的话,我们可以用这些“高端”的工具证明解的不存在性,或者求出通解(如果有解的话)。
然而,对于初等数论来讲,复数环和域的知识的门槛还是有点高了。其次,环和域是一个比较“强”的工具。这里的“强”有点“强势”的意味,是指这样的意思:如果它成功的话,它能够“一举破城”,把通解都求出来(或者证明解的不存在);如果它不成功的话,那么往往就连一点非平凡的解都求不出来。可是,有些问题是求出一部分解都已经很困难了,更不用说求出通解了(我们以后在研究$x^4+y^4 = z^4 + w^4 $的整数解的时候,就能深刻体会这点。)。因此,对于这些问题,单纯用环域的思想,很难给予我们(至少一部分)解。(当然,问题是如何才算是“单纯”,这也很难界定。这里的评论是比较粗糙的。)
25
Dec
从loss的硬截断、软化到focal loss
By 苏剑林 | 2017-12-25 | 208141位读者 | 引用前言
今天在QQ群里的讨论中看到了focal loss,经搜索它是Kaiming大神团队在他们的论文《Focal Loss for Dense Object Detection》提出来的损失函数,利用它改善了图像物体检测的效果。不过我很少做图像任务,不怎么关心图像方面的应用。本质上讲,focal loss就是一个解决分类问题中类别不平衡、分类难度差异的一个loss,总之这个工作一片好评就是了。大家还可以看知乎的讨论:
《如何评价kaiming的Focal Loss for Dense Object Detection?》
看到这个loss,开始感觉很神奇,感觉大有用途。因为在NLP中,也存在大量的类别不平衡的任务。最经典的就是序列标注任务中类别是严重不平衡的,比如在命名实体识别中,显然一句话里边实体是比非实体要少得多,这就是一个类别严重不平衡的情况。我尝试把它用在我的基于序列标注的问答模型中,也有微小提升。嗯,这的确是一个好loss。
接着我再仔细对比了一下,我发现这个loss跟我昨晚构思的一个loss具有异曲同工之理!这就促使我写这篇博文了。我将从我自己的思考角度出发,来分析这个问题,最后得到focal loss,也给出我昨晚得到的类似的loss。

最近评论