






25
Jun
OCR技术浅探:6. 光学识别
By 苏剑林 | 2016-06-25 | 78181位读者 | 引用经过第一、二步,我们已经能够找出图像中单个文字的区域,接下来可以建立相应的模型对单字进行识别.
模型选择
在模型方面,我们选择了深度学习中的卷积神经网络模型,通过多层卷积神经网络,构建了单字的识别模型.
卷积神经网络是人工神经网络的一种,已成为当前图像识别领域的主流模型. 它通过局部感知野和权值共享方法,降低了网络模型的复杂度,减少了权值的数量,在网络结构上更类似于生物神经网络,这也预示着它必然具有更优秀的效果. 事实上,我们选择卷积神经网络的主要原因有:
1. 对原始图像自动提取特征 卷积神经网络模型可以直接将原始图像进行输入,免除了传统模型的人工提取特征这一比较困难的核心部分;
2. 比传统模型更高的精度 比如在MNIST手写数字识别任务中,可以达到99%以上的精度,这远高于传统模型的精度;
3. 比传统模型更好的泛化能力 这意味着图像本身的形变(伸缩、旋转)以及图像上的噪音对识别的结果影响不明显,这正是一个良好的OCR系统所必需的.
6
Sep
基于双向LSTM和迁移学习的seq2seq核心实体识别
By 苏剑林 | 2016-09-06 | 174867位读者 | 引用暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下。模型的效果不是最好的,但是胜在“端到端”,迁移性强,估计对大家会有一定的参考价值。
比赛的主题是“核心实体识别”,其实有两个任务:核心识别 + 实体识别。这两个任务虽然有关联,但在传统自然语言处理程序中,一般是将它们分开处理的,而这次需要将两个任务联合在一起。如果只看“核心识别”,那就是传统的关键词抽取任务了,不同的是,传统的纯粹基于统计的思路(如TF-IDF抽取)是行不通的,因为单句中的核心实体可能就只出现一次,这时候统计估计是不可靠的,最好能够从语义的角度来理解。我一开始就是从“核心识别”入手,使用的方法类似QA系统:
1、将句子分词,然后用Word2Vec训练词向量;
2、用卷积神经网络(在这种抽取式问题上,CNN效果往往比RNN要好)卷积一下,得到一个与词向量维度一样的输出;
3、损失函数就是输出向量跟训练样本的核心词向量的cos值。
30
Mar
文本情感分类(四):更好的损失函数
By 苏剑林 | 2017-03-30 | 132719位读者 | 引用文本情感分类其实就是一个二分类问题,事实上,对于分类模型,都会存在这样一个毛病:优化目标跟考核指标不一致。通常来说,对于分类(包括多分类),我们都会采用交叉熵作为损失函数,它的来源就是最大似然估计(参考《梯度下降和EM算法:系出同源,一脉相承》)。但是,我们最后的评估目标,并非要看交叉熵有多小,而是看模型的准确率。一般来说,交叉熵很小,准确率也会很高,但这个关系并非必然的。
要平均,不一定要拔尖
一个更通俗的例子是:一个数学老师,在努力提高同学们的平均分,但期末考核的指标却是及格率(60分及格)。假如平均分是100分(也就意味着所有同学都考到了100分),那么自然及格率是100%,这是最理想的。但现实不一定这么美好,平均分越高,只要平均分还没有达到100,那么及格率却不一定越高,比如两个人分别考40和90,那么平均分就是65,及格率只有50%;如果两个人的成绩都是60,平均分就是60,及格率却有100%。这也就是说,平均分可以作为一个目标,但这个目标并不直接跟考核目标挂钩。
那么,为了提升最后的考核目标,这个老师应该怎么做呢?很显然,首先看看所有学生中,哪些同学已经及格了,及格的同学先不管他们,而针对不及格的同学进行补课加强,这样一来,原则上来说有很多不及格的同学都能考上60分了,也有可能一些本来及格的同学考不够60分了,但这个过程可以迭代,最终使得大家都在60分以上,当然,最终的平均分不一定很高,但没办法,谁叫考核目标是及格率呢?
26
Oct
浅谈神经网络中激活函数的设计
By 苏剑林 | 2017-10-26 | 50868位读者 | 引用激活函数是神经网络中非线性的来源,因为如果去掉这些函数,那么整个网络就只剩下线性运算,线性运算的复合还是线性运算的,最终的效果只相当于单层的线性模型。
那么,常见的激活函数有哪些呢?或者说,激活函数的选择有哪些指导原则呢?是不是任意的非线性函数都可以做激活函数呢?
这里探究的激活函数是中间层的激活函数,而不是输出的激活函数。最后的输出一般会有特定的激活函数,不能随意改变,比如二分类一般用sigmoid函数激活,多分类一般用softmax激活,等等;相比之下,中间层的激活函数选择余地更大一些。
浮点误差都行!
理论上来说,只要是非线性函数,都有做激活函数的可能性,一个很有说服力的例子是,最近OpenAI成功地利用了浮点误差来做激活函数,其中的细节,请阅读OpenAI的博客:
https://blog.openai.com/nonlinear-computation-in-linear-networks/
或者阅读机器之心的介绍:
https://mp.weixin.qq.com/s/PBRzS4Ol_Zst35XKrEpxdw
19
Nov
更别致的词向量模型(四):模型的求解
By 苏剑林 | 2017-11-19 | 56286位读者 | 引用损失函数
现在,我们来定义loss,以便把各个词向量求解出来。用$\tilde{P}$表示$P$的频率估计值,那么我们可以直接以下式为loss
\[\sum_{w_i,w_j}\left(\langle \boldsymbol{v}_i, \boldsymbol{v}_j\rangle-\log\frac{\tilde{P}(w_i,w_j)}{\tilde{P}(w_i)\tilde{P}(w_j)}\right)^2\tag{16}\]
相比之下,无论在参数量还是模型形式上,这个做法都比glove要简单,因此称之为simpler glove。glove模型是
\[\sum_{w_i,w_j}\left(\langle \boldsymbol{v}_i, \boldsymbol{\hat{v}}_j\rangle+b_i+\hat{b}_j-\log X_{ij}\right)^2\tag{17}\]
在glove模型中,对中心词向量和上下文向量做了区分,然后最后模型建议输出的是两套词向量的求和,据说这效果会更好,这是一个比较勉强的trick,但也不是什么毛病。
\[\begin{aligned}&\sum_{w_i,w_j}\left(\langle \boldsymbol{v}_i, \boldsymbol{\hat{v}}_j\rangle+b_i+\hat{b}_j-\log \tilde{P}(w_i,w_j)\right)^2\\
=&\sum_{w_i,w_j}\left[\langle \boldsymbol{v}_i+\boldsymbol{c}, \boldsymbol{\hat{v}}_j+\boldsymbol{c}\rangle+\Big(b_i-\langle \boldsymbol{v}_i, \boldsymbol{c}\rangle - \frac{|\boldsymbol{c}|^2}{2}\Big)\right.\\
&\qquad\qquad\qquad\qquad\left.+\Big(\hat{b}_j-\langle \boldsymbol{\hat{v}}_j, \boldsymbol{c}\rangle - \frac{|\boldsymbol{c}|^2}{2}\Big)-\log X_{ij}\right]^2\end{aligned}\tag{18}\]
这就是说,如果你有了一组解,那么你将所有词向量加上任意一个常数向量后,它还是一组解!这个问题就严重了,我们无法预估得到的是哪组解,一旦加上的是一个非常大的常向量,那么各种度量都没意义了(比如任意两个词的cos值都接近1)。事实上,对glove生成的词向量进行验算就可以发现,glove生成的词向量,停用词的模长远大于一般词的模长,也就是说一堆词放在一起时,停用词的作用还明显些,这显然是不利用后续模型的优化的。(虽然从目前的关于glove的实验结果来看,是我强迫症了一些。)
互信息估算
25
Nov
果壳中的条件随机场(CRF In A Nutshell)
By 苏剑林 | 2017-11-25 | 123793位读者 | 引用本文希望用尽可能简短的语言把CRF(条件随机场,Conditional Random Field)的原理讲清楚,这里In A Nutshell在英文中其实有“导论”、“科普”等意思(霍金写过一本《果壳中的宇宙》,这里东施效颦一下)。
网上介绍CRF的文章,不管中文英文的,基本上都是先说一些概率图的概念,然后引入特征的指数公式,然后就说这是CRF。所谓“概率图”,只是一个形象理解的说法,然而如果原理上说不到点上,你说太多形象的比喻,反而让人糊里糊涂,以为你只是在装逼。(说到这里我又想怼一下了,求解神经网络,明明就是求一下梯度,然后迭代一下,这多好理解,偏偏还弄个装逼的名字叫“反向传播”,如果不说清楚它的本质是求导和迭代求解,一下子就说反向传播,有多少读者会懂?)
好了,废话说完了,来进入正题。
逐标签Softmax
CRF常见于序列标注相关的任务中。假如我们的模型输入为$Q$,输出目标是一个序列$a_1,a_2,\dots,a_n$,那么按照我们通常的建模逻辑,我们当然是希望目标序列的概率最大
$$P(a_1,a_2,\dots,a_n|Q)$$
不管用传统方法还是用深度学习方法,直接对完整的序列建模是比较艰难的,因此我们通常会使用一些假设来简化它,比如直接使用朴素假设,就得到
$$P(a_1,a_2,\dots,a_n|Q)=P(a_1|Q)P(a_2|Q)\dots P(a_n|Q)$$
24
Apr
最小熵原理(二):“当机立断”之词库构建
By 苏剑林 | 2018-04-24 | 90117位读者 | 引用在本文,我们介绍“套路宝典”第一式——“当机立断”:1、导出平均字信息熵的概念,然后基于最小熵原理推导出互信息公式;2、并且完成词库的无监督构建、给出一元分词模型的信息熵诠释,从而展示有关生成套路、识别套路的基本方法和技巧。
这既是最小熵原理的第一个使用案例,也是整个“套路宝典”的总纲。
你练或者不练,套路就在那里,不增不减。
为什么需要词语
从上一篇文章可以看到,假设我们根本不懂中文,那么我们一开始会将中文看成是一系列“字”随机组合的字符串,但是慢慢地我们会发现上下文是有联系的,它并不是“字”的随机组合,它应该是“套路”的随机组合。于是为了减轻我们的记忆成本,我们会去挖掘一些语言的“套路”。第一个“套路”,是相邻的字之间的组合定式,这些组合定式,也就是我们理解的“词”。
平均字信息熵
假如有一批语料,我们将它分好词,以词作为中文的单位,那么每个词的信息量是$-\log p_w$,因此我们就可以计算记忆这批语料所要花费的时间为
$$-\sum_{w\in \text{语料}}\log p_w\tag{2.1}$$
这里$w\in \text{语料}$是对语料逐词求和,不用去重。如果不分词,按照字来理解,那么需要的时间为
$$-\sum_{c\in \text{语料}}\log p_c\tag{2.2}$$
18
May
简明条件随机场CRF介绍(附带纯Keras实现)
By 苏剑林 | 2018-05-18 | 361521位读者 | 引用笔者去年曾写过博文《果壳中的条件随机场(CRF In A Nutshell)》,以一种比较粗糙的方式介绍了一下条件随机场(CRF)模型。然而那篇文章显然有很多不足的地方,比如介绍不够清晰,也不够完整,还没有实现,在这里我们重提这个模型,将相关内容补充完成。
本文是对CRF基本原理的一个简明的介绍。当然,“简明”是相对而言中,要想真的弄清楚CRF,免不了要提及一些公式,如果只关心调用的读者,可以直接移到文末。
图示
按照之前的思路,我们依旧来对比一下普通的逐帧softmax和CRF的异同。
逐帧softmax
CRF主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
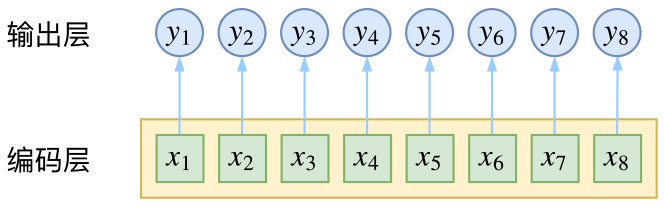
逐帧softmax并没有直接考虑输出的上下文关联

最近评论