






在查找量子化有关资料的时候,笔者查找到了一系列名为《漫谈几何量子化》的文章,并进一步查询得知,作者为季候风,原来发表在繁星客栈(顺便提一下,繁星客栈是最早的理论物理论坛之一,现在已经不能发帖了,但是上面很多资料都弥足珍贵),据说这是除正则量子化和路径积分量子化外的第三种量子化方法。网上鲜有几何量子化的资料,更不用说是中文资料了,于是季候风前辈的这一十五篇文章便显得格外有意义了。
然而,虽然不少网站都转载了这系列文章,但是无一例外地,文章中的公式图片已经失效了,后来笔者在百度网盘那找到其中的十四篇pdf格式的(估计是网友在公式图片失效前保存下来的),笔者通过替换公式服务器的方式找回了第十五篇,把第十五篇也补充进去了。(见漫谈几何量子化(原文档).zip)
虽然这样已经面前能够阅读了,但是总感觉美中不足,虽然笔者花了三天时间把文章重新用$\LaTeX$录入了,主要是把公式重新录入了,简单地排版了一下。现放出来与大家分享。
17
Jul
强大的整数数列网站OEIS
By 苏剑林 | 2014-07-17 | 41099位读者 | 引用OEIS?:http://oeis.org/
近段时间在研究解析数论,进一步感觉数论真是个奇妙的东西,通过它,似乎数学的各个方面——离散的和连续的,实数的和复数的,甚至物理的——都联系了起来。由此也不难体会到当初高斯(Gauss)会说“数学是科学的皇后,数论是数学的皇后。”了。今天,由于在研究素数的个数的上下界问题时,需要思考组合数
$$C_{n}^{2n}=\binom{2n}{n}=\frac{(2n)!}{n!\ n!}$$
最多能被2的多少次方整除。直觉告诉我,次数应该是随着$n$的增大而增大的,但事实却不是,比如$C_{15}^{30}$能够被16整除,但是$C_{20}^{40}$却最多只能被4整除,有种毫无规律的感觉,于是到群里问问各大神。其中,wayne提出
这个可以写个小程序算出一些数据,再在oeis上搜搜
2
Apr
【不可思议的Word2Vec】 1.数学原理
By 苏剑林 | 2017-04-02 | 60678位读者 | 引用对于了解深度学习、自然语言处理NLP的读者来说,Word2Vec可以说是家喻户晓的工具,尽管不是每一个人都用到了它,但应该大家都会听说过它——Google出品的高效率的获取词向量的工具。
Word2Vec不可思议?
大多数人都是将Word2Vec作为词向量的等价名词,也就是说,纯粹作为一个用来获取词向量的工具,关心模型本身的读者并不多。可能是因为模型过于简化了,所以大家觉得这样简化的模型肯定很不准确,所以没法用,但它的副产品词向量的质量反而还不错。没错,如果是作为语言模型来说,Word2Vec实在是太粗糙了。
但是,为什么要将它作为语言模型来看呢?抛开语言模型的思维约束,只看模型本身,我们就会发现,Word2Vec的两个模型 —— CBOW和Skip-Gram —— 实际上大有用途,它们从不同角度来描述了周围词与当前词的关系,而很多基本的NLP任务,都是建立在这个关系之上,如关键词抽取、逻辑推理等。这几篇文章就是希望能够抛砖引玉,通过介绍Word2Vec模型本身,以及几个看上去“不可思议”的用法,来提供一些研究此类问题的新思路。
18
Mar
变分自编码器(一):原来是这么一回事
By 苏剑林 | 2018-03-18 | 1086905位读者 | 引用过去虽然没有细看,但印象里一直觉得变分自编码器(Variational Auto-Encoder,VAE)是个好东西。于是趁着最近看概率图模型的三分钟热度,我决定也争取把VAE搞懂。于是乎照样翻了网上很多资料,无一例外发现都很含糊,主要的感觉是公式写了一大通,还是迷迷糊糊的,最后好不容易觉得看懂了,再去看看实现的代码,又感觉实现代码跟理论完全不是一回事啊。
终于,东拼西凑再加上我这段时间对概率模型的一些积累,并反复对比原论文《Auto-Encoding Variational Bayes》,最后我觉得我应该是想明白了。其实真正的VAE,跟很多教程说的的还真不大一样,很多教程写了一大通,都没有把模型的要点写出来~于是写了这篇东西,希望通过下面的文字,能把VAE初步讲清楚。
分布变换
通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量$Z$生成目标数据$X$的模型,但是实现上有所不同。更准确地讲,它们是假设了$Z$服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型$X=g(Z)$,这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。
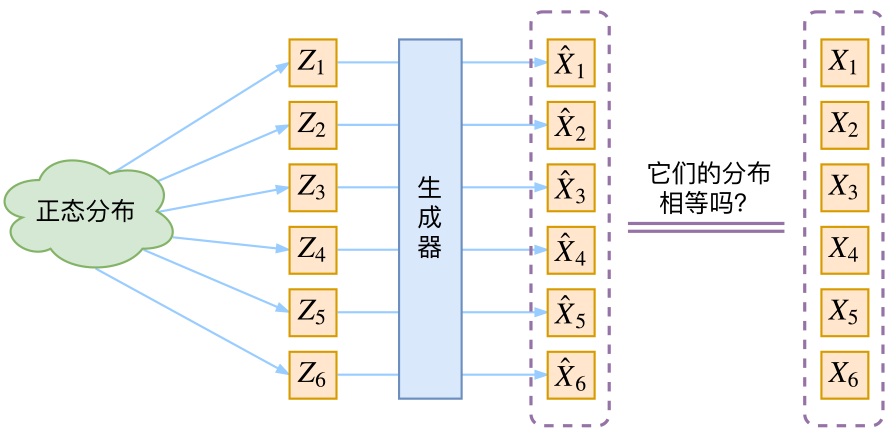
生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式
1
Mar
对抗训练浅谈:意义、方法和思考(附Keras实现)
By 苏剑林 | 2020-03-01 | 250308位读者 | 引用当前,说到深度学习中的对抗,一般会有两个含义:一个是生成对抗网络(Generative Adversarial Networks,GAN),代表着一大类先进的生成模型;另一个则是跟对抗攻击、对抗样本相关的领域,它跟GAN相关,但又很不一样,它主要关心的是模型在小扰动下的稳健性。本博客里以前所涉及的对抗话题,都是前一种含义,而今天,我们来聊聊后一种含义中的“对抗训练”。
本文包括如下内容:
1、对抗样本、对抗训练等基本概念的介绍;
2、介绍基于快速梯度上升的对抗训练及其在NLP中的应用;
3、给出了对抗训练的Keras实现(一行代码调用);
4、讨论了对抗训练与梯度惩罚的等价性;
5、基于梯度惩罚,给出了一种对抗训练的直观的几何理解。
25
Feb
【搜出来的文本】⋅(四)通过增、删、改来用词造句
By 苏剑林 | 2021-02-25 | 53160位读者 | 引用“用词造句”是小学阶段帮助我们理解和运用词语的一个经典任务,从自然语言处理的角度来看,它是一个句子扩写或者句子补全任务,它其实要求我们具有不定向地进行文本生成的能力。然而,当前主流的语言模型都是单方向生成的(多数是正向的,即从左往右,少数是反向的,即从右往左),但用词造句任务中所给的若干个词未必一定出现在句首或者句末,这导致无法直接用语言模型来完成造句任务。
本文我们将介绍论文《CGMH: Constrained Sentence Generation by Metropolis-Hastings Sampling》,它使用MCMC采样使得单向语言模型也可以做到不定向生成,通过增、删、改操作模拟了人的写作润色过程,从而能无监督地完成用词造句等多种文本生成任务。
问题设置
无监督地进行文本采样,那么直接可以由语言模型来完成,而我们同样要做的,是往这个采样过程中加入一些信号$\boldsymbol{c}$,使得它能生成我们期望的一些文本。在本系列第一篇文章《【搜出来的文本】⋅(一)从文本生成到搜索采样》的“明确目标”一节中,我们就介绍了本系列的指导思想:把我们要寻找的目标量化地写下来,然后最大化它或者从中采样。
1
May
GlobalPointer:用统一的方式处理嵌套和非嵌套NER
By 苏剑林 | 2021-05-01 | 356050位读者 | 引用(注:本文的相关内容已整理成论文《Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition》,如需引用可以直接引用英文论文,谢谢。)
本文将介绍一个称为GlobalPointer的设计,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是$\mathcal{O}(1)$!
简单来说,就是更漂亮、更快速、更强大!真有那么好的设计吗?不妨继续看看。
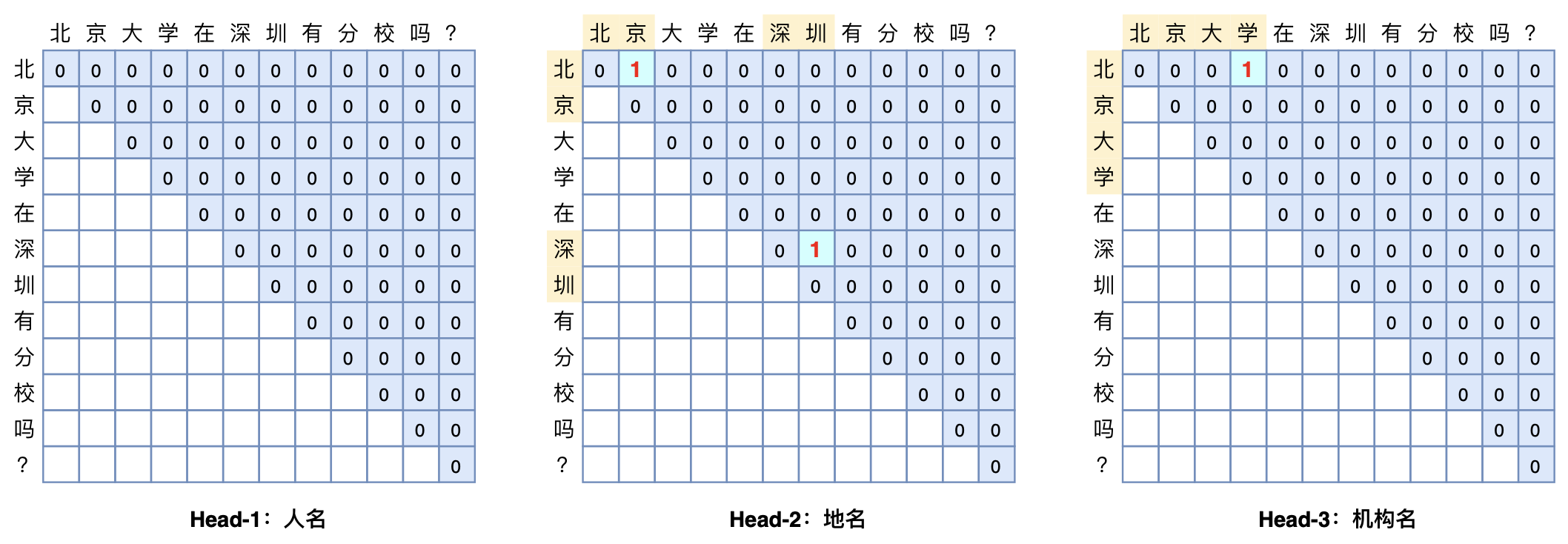
GlobalPointer多头识别嵌套实体示意图
10
Sep
曾被嫌弃的预训练任务NSP,做出了优秀的Zero Shot效果
By 苏剑林 | 2021-09-10 | 59700位读者 | 引用在五花八门的预训练任务设计中,NSP通常认为是比较糟糕的一种,因为它难度较低,加入到预训练中并没有使下游任务微调时有明显受益,甚至RoBERTa的论文显示它会带来负面效果。所以,后续的预训练工作一般有两种选择:一是像RoBERTa一样干脆去掉NSP任务,二是像ALBERT一样想办法提高NSP的难度。也就是说,一直以来NSP都是比较“让人嫌弃”的。
不过,反转来了,NSP可能要“翻身”了。最近的一篇论文《NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task--Next Sentence Prediction》(下面简称NSP-BERT)显示NSP居然也可以做到非常不错的Zero Shot效果!这又是一个基于模版(Prompt)的Few/Zero Shot的经典案例,只不过这一次的主角是NSP。
背景回顾
曾经我们认为预训练纯粹就是预训练,它只是为下游任务的训练提供更好的初始化,像BERT的预训练任务有MLM(Masked Language Model和NSP(Next Sentence Prediction),在相当长的一段时间内,大家都不关心这两个预训练任务本身,而只是专注于如何通过微调来使得下游任务获得更好的性能。哪怕是T5将模型参数训练到了110亿,走的依然是“预训练+微调”这一路线。

最近评论