






9
Mar
Seq2Seq中Exposure Bias现象的浅析与对策
By 苏剑林 | 2020-03-09 | 99158位读者 | 引用前些天笔者写了《CRF用过了,不妨再了解下更快的MEMM?》,里边提到了MEMM的局部归一化和CRF的全局归一化的优劣。同时,笔者联想到了Seq2Seq模型,因为Seq2Seq模型的典型训练方案Teacher Forcing就是一个局部归一化模型,所以它也存在着局部归一化所带来的毛病——也就是我们经常说的“Exposure Bias”。带着这个想法,笔者继续思考了一翻,将最后的思考结果记录在此文。

经典的Seq2Seq模型图示
本文算是一篇进阶文章,适合对Seq2Seq模型已经有一定的了解、希望进一步提升模型的理解或表现的读者。关于Seq2Seq的入门文章,可以阅读旧作《玩转Keras之seq2seq自动生成标题》和《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》。
本文的内容大致为:
1、Exposure Bias的成因分析及例子;
2、简单可行的缓解Exposure Bias问题的策略。
13
Apr
突破瓶颈,打造更强大的Transformer
By 苏剑林 | 2020-04-13 | 137113位读者 | 引用自《Attention is All You Need》一文发布后,基于Multi-Head Attention的Transformer模型开始流行起来,而去年发布的BERT模型更是将Transformer模型的热度推上了又一个高峰。当然,技术的探索是无止境的,改进的工作也相继涌现:有改进预训练任务的,比如XLNET的PLM、ALBERT的SOP等;有改进归一化的,比如Post-Norm向Pre-Norm的改变,以及T5中去掉了Layer Norm里边的beta参数等;也有改进模型结构的,比如Transformer-XL等;有改进训练方式的,比如ALBERT的参数共享等;...
以上的这些改动,都是在Attention外部进行改动的,也就是说它们都默认了Attention的合理性,没有对Attention本身进行改动。而本文我们则介绍关于两个新结果:它们针对Multi-Head Attention中可能存在建模瓶颈,提出了不同的方案来改进Multi-Head Attention。两篇论文都来自Google,并且做了相当充分的实验,因此结果应该是相当有说服力的了。
再小也不能小key_size
第一个结果来自文章《Low-Rank Bottleneck in Multi-head Attention Models》,它明确地指出了Multi-Head Attention里边的表达能力瓶颈,并提出通过增大key_size的方法来缓解这个瓶颈。
25
Apr
将“Softmax+交叉熵”推广到多标签分类问题
By 苏剑林 | 2020-04-25 | 377132位读者 | 引用(注:本文的相关内容已整理成论文《ZLPR: A Novel Loss for Multi-label Classification》,如需引用可以直接引用英文论文,谢谢。)
一般来说,在处理常规的多分类问题时,我们会在模型的最后用一个全连接层输出每个类的分数,然后用softmax激活并用交叉熵作为损失函数。在这篇文章里,我们尝试将“Softmax+交叉熵”方案推广到多标签分类场景,希望能得到用于多标签分类任务的、不需要特别调整类权重和阈值的loss。

类别不平衡
单标签到多标签
一般来说,多分类问题指的就是单标签分类问题,即从$n$个候选类别中选$1$个目标类别。假设各个类的得分分别为$s_1,s_2,
\dots,s_n$,目标类为$t\in\{1,2,\dots,n\}$,那么所用的loss为
\begin{equation}-\log \frac{e^{s_t}}{\sum\limits_{i=1}^n e^{s_i}}= - s_t + \log \sum\limits_{i=1}^n e^{s_i}\label{eq:log-softmax}\end{equation}
这个loss的优化方向是让目标类的得分$s_t$变为$s_1,s_2,\dots,s_t$中的最大值。关于softmax的相关内容,还可以参考《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等文章。
23
Mar
AdaFactor优化器浅析(附开源实现)
By 苏剑林 | 2020-03-23 | 90018位读者 | 引用自从GPT、BERT等预训练模型流行起来后,其中一个明显的趋势是模型越做越大,因为更大的模型配合更充分的预训练通常能更有效地刷榜。不过,理想可以无限远,现实通常很局促,有时候模型太大了,大到哪怕你拥有了大显存的GPU甚至TPU,依然会感到很绝望。比如GPT2最大的版本有15亿参数,最大版本的T5模型参数量甚至去到了110亿,这等规模的模型,哪怕在TPU集群上也没法跑到多大的batch size。
这时候通常要往优化过程着手,比如使用混合精度训练(tensorflow下还可以使用一种叫做bfloat16的新型浮点格式),即省显存又加速训练;又或者使用更省显存的优化器,比如RMSProp就比Adam更省显存。本文则介绍AdaFactor,一个由Google提出来的新型优化器,首发论文为《Adafactor: Adaptive Learning Rates with Sublinear Memory Cost》。AdaFactor具有自适应学习率的特性,但比RMSProp还要省显存,并且还针对性地解决了Adam的一些缺陷。
Adam
首先我们来回顾一下常用的Adam优化器的更新过程。设$t$为迭代步数,$\alpha_t$为当前学习率,$L(\theta)$是损失函数,$\theta$是待优化参数,$\epsilon$则是防止溢出的小正数,那么Adam的更新过程为
20
Apr
EAE:自编码器 + BN + 最大熵 = 生成模型
By 苏剑林 | 2020-04-20 | 62817位读者 | 引用生成模型一直是笔者比较关注的主题,不管是NLP和CV的生成模型都是如此。这篇文章里,我们介绍一个新颖的生成模型,来自论文《Batch norm with entropic regularization turns deterministic autoencoders into generative models》,论文中称之为EAE(Entropic AutoEncoder)。它要做的事情给变分自编码器(VAE)基本一致,最终效果其实也差不多(略优),说它新颖并不是它生成效果有多好,而是思路上的新奇,颇有别致感。此外,借着这个机会,我们还将学习一种统计量的估计方法——$k$邻近方法,这是一种很有用的非参数估计方法。
自编码器vs生成模型
普通的自编码器是一个“编码-解码”的重构过程,如下图所示:
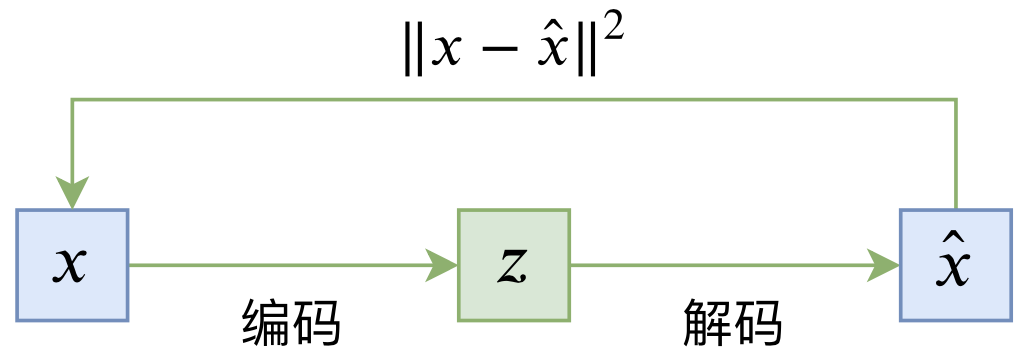
典型自编码器示意图
其loss一般为
\begin{equation}L_{AE} = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - \hat{x}\right\Vert^2\right] = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - D(E(x))\right\Vert^2\right]\end{equation}
25
May
Google新作Synthesizer:我们还不够了解自注意力
By 苏剑林 | 2020-05-25 | 98072位读者 | 引用深度学习这个箱子,远比我们想象的要黑。
写在开头
据说物理学家费曼说过一句话[来源]:“谁要是说他懂得量子力学,那他就是真的不懂量子力学。”我现在越来越觉得,这句话中的“量子力学”也可以替换为“深度学习”。尽管深度学习已经在越来越多的领域证明了其有效性,但我们对它的解释性依然相当无力。当然,这几年来已经有不少工作致力于打开深度学习这个黑箱,但是很无奈,这些工作基本都是“马后炮”式的,也就是在已有的实验结果基础上提出一些勉强能说服自己的解释,无法做到自上而下的构建和理解模型的原理,更不用说提出一些前瞻性的预测。
本文关注的是自注意力机制。直观上来看,自注意力机制算是解释性比较强的模型之一了,它通过自己与自己的Attention来自动捕捉了token与token之间的关联,事实上在《Attention is All You Need》那篇论文中,就给出了如下的看上去挺合理的可视化效果:
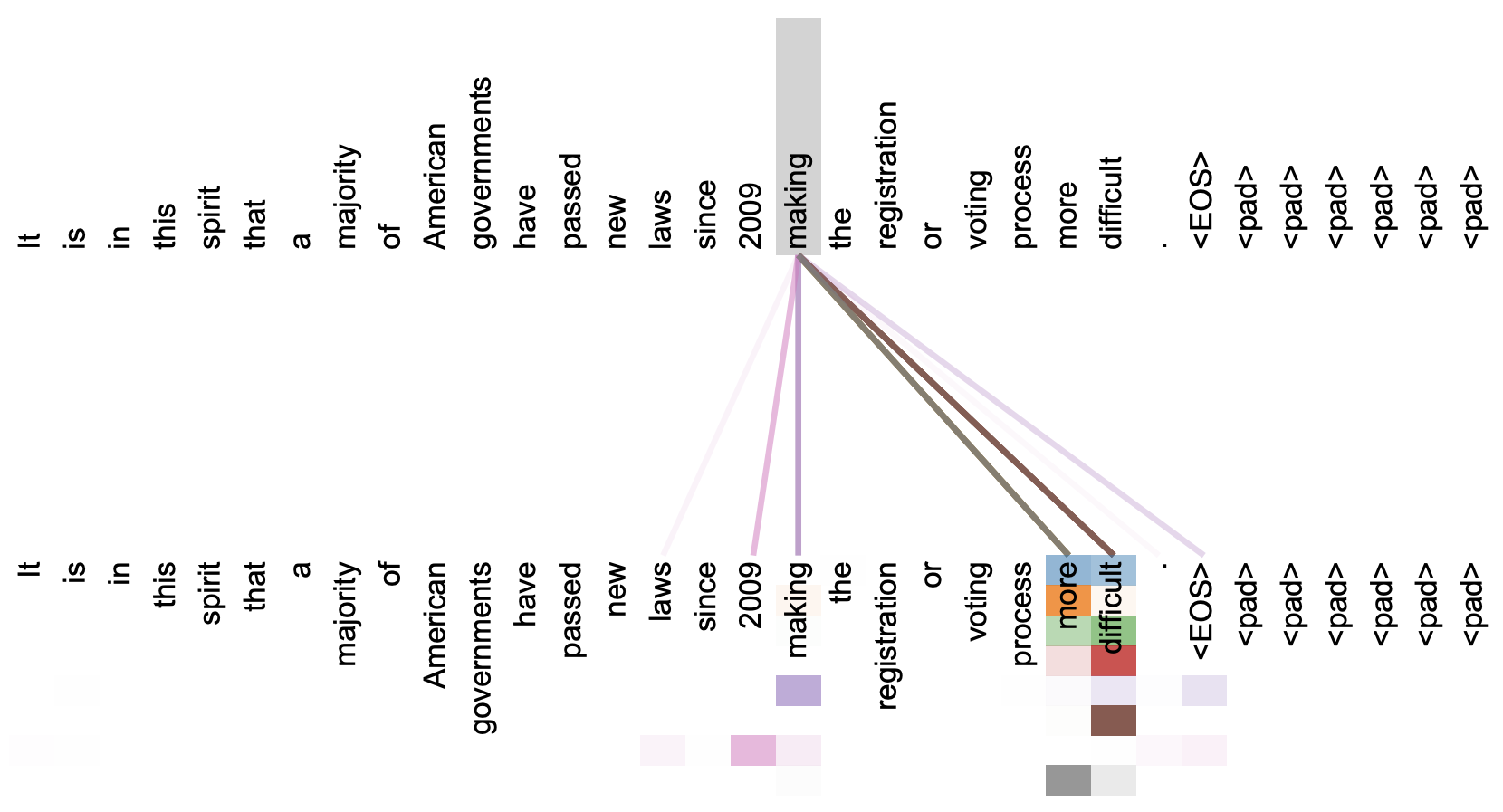
《Attention is All You Need》一文中对Attention的可视化例子
但自注意力机制真的是这样生效的吗?这种“token对token”的注意力是必须的吗?前不久Google的新论文《Synthesizer: Rethinking Self-Attention in Transformer Models》对自注意力机制做了一些“异想天开”的探索,里边的结果也许会颠覆我们对自注意力的认知。
28
Jun
积分梯度:一种新颖的神经网络可视化方法
By 苏剑林 | 2020-06-28 | 97926位读者 | 引用本文介绍一种神经网络的可视化方法:积分梯度(Integrated Gradients),它首先在论文《Gradients of Counterfactuals》中提出,后来《Axiomatic Attribution for Deep Networks》再次介绍了它,两篇论文作者都是一样的,内容也大体上相同,后一篇相对来说更易懂一些,如果要读原论文的话,建议大家优先读后一篇。当然,它已经是2016~2017年间的工作了,“新颖”说的是它思路上的创新有趣,而不是指最近发表。

笔者在中文情感分类上对积分梯度的实验效果(越红的token越重要)
所谓可视化,简单来说就是对于给定的输入$x$以及模型$F(x)$,我们想办法指出$x$的哪些分量对模型的决策有重要影响,或者说对$x$各个分量的重要性做个排序,用专业的话术来说那就是“归因”。一个朴素的思路是直接使用梯度$\nabla_x F(x)$来作为$x$各个分量的重要性指标,而积分梯度是对它的改进。然而,笔者认为,很多介绍积分梯度方法的文章(包括原论文),都过于“生硬”(形式化),没有很好地突出积分梯度能比朴素梯度更有效的本质原因。本文试图用自己的思路介绍一下积分梯度方法。
4
Jul
线性Attention的探索:Attention必须有个Softmax吗?
By 苏剑林 | 2020-07-04 | 245596位读者 | 引用众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是$\mathcal{O}(n^2)$级别的,$n$是序列长度,所以当$n$比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到$\mathcal{O}(n\log n)$甚至$\mathcal{O}(n)$。
前几天笔者读到了论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》,了解到了线性化Attention(Linear Attention)这个探索点,继而阅读了一些相关文献,有一些不错的收获,最后将自己对线性化Attention的理解汇总在此文中。
Attention
当前最流行的Attention机制当属Scaled-Dot Attention,形式为
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\label{eq:std-att}\end{equation}
这里的$\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}$,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设$\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times d}$,一般场景下都有$n > d$甚至$n\gg d$(BERT base里边$d=64$)。

最近评论