






28
Apr
在bert4keras中使用混合精度和XLA加速训练
By 苏剑林 | 2022-04-28 | 19393位读者 | 引用之前笔者一直都是聚焦于模型的构思和实现,鲜有关注模型的训练加速,像混合精度和XLA这些技术,虽然也有听过,但没真正去实践过。这两天折腾了一番,成功在bert4keras中使用了混合精度和XLA来加速训练,在此做个简单的总结,供大家参考。
本文的多数经验结论并不只限于bert4keras中使用,之所以在标题中强调bert4keras,只不过bert4keras中的模型实现相对较为规整,因此启动这些加速技巧所要做的修改相对更少。
实验环境
本文的实验显卡为3090,使用的docker镜像为nvcr.io/nvidia/tensorflow:21.09-tf1-py3,其中自带的tensorflow版本为1.15.5。另外,实验所用的bert4keras版本为0.11.3。其他环境也可以参考着弄,要注意有折腾精神,不要指望着无脑调用。
顺便提一下,3090、A100等卡只能用cuda11,而tensorflow官网的1.15版本是不支持cuda11的,如果还想用tensorflow 1.x,那么只能用nvidia亲自维护的nvidia-tensorflow,或者用其构建的docker镜像。用nvidia而不是google维护的tensorflow,除了能让你在最新的显卡用上1.x版本外,还有nvidia专门做的一些额外优化,具体文档可以参考这里。
9
Oct
“十字架”组合计数问题浅试
By 苏剑林 | 2022-10-09 | 13458位读者 | 引用
4
Jan
智能家居之热水器零冷水技术原理浅析
By 苏剑林 | 2023-01-04 | 27906位读者 | 引用如果家庭使用单一的热水器集中供热水,那么当我们想要用热水时,往往需要先放一段时间的冷水,而如果放冷水时间比较长的话,就会比较影响体验。所谓零冷水,实际上就是想办法提前把热水管中的冷水排放掉,以达到(几乎)瞬间出热水的效果。事实上,零冷水并不是什么高大上的技术,但可能由于观念没跟上、理解上有误等原因,零冷水技术还没有在家庭中得到普及,不过随着大家对生活品质的要求越来越高,零冷水确实在慢慢流行起来了。
本文来简单分析一下零冷水技术的实现原理,包括各种方案的优缺点和自省DIY的参考思路。
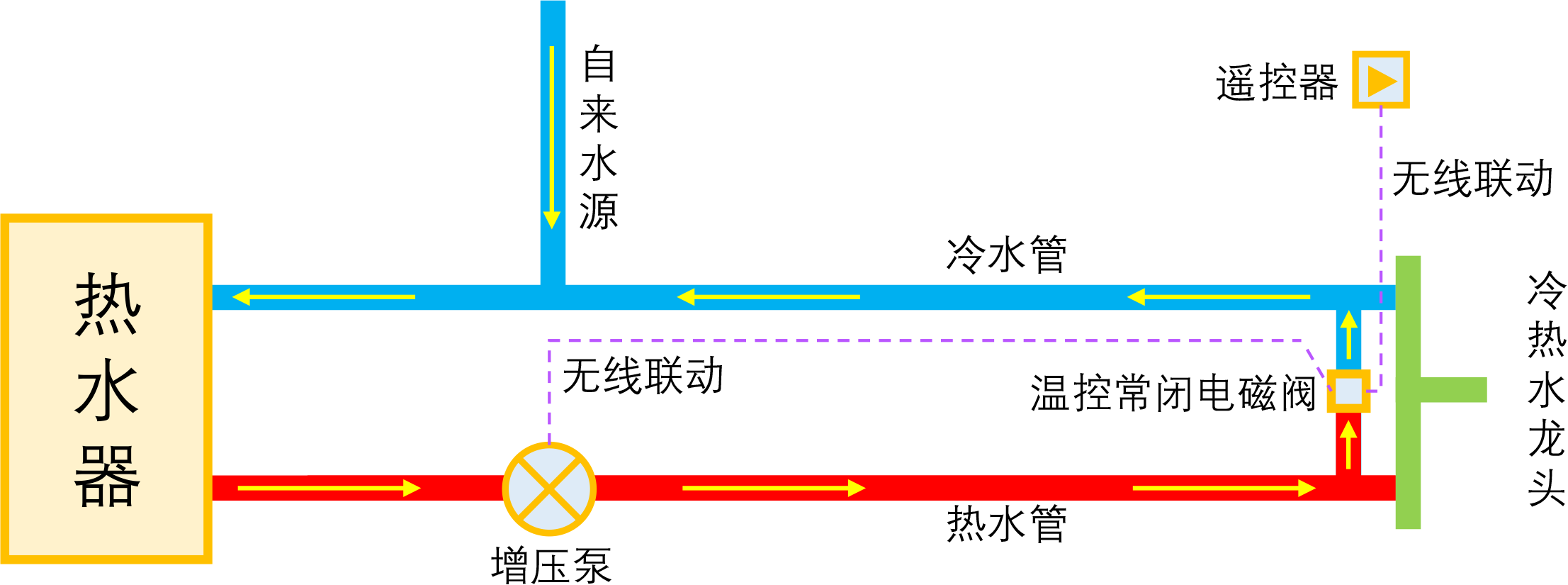
理想的零冷水方案
写在前面
在文章开始,需要纠正很多人的一个错误观念:零冷水不是为了省钱,而是为了提升生活品质。如果你是省钱最大的心态,那么接下来的内容就可以不用看了,零冷水技术对你毫无价值。
13
Nov
【生活杂记】炒锅的尽头是铁锅
By 苏剑林 | 2023-11-13 | 41012位读者 | 引用
铁锅(网络图)
很多会下厨的同学估计都纠结过一件事情,那就是炒锅的选择。
对于炒锅的纠结,归根结底是不粘与方便的权衡。最简单的不粘锅自然是带涂层的不粘锅,如果家里的热源只有电磁炉,并且炒菜习惯比较温和,那么涂层不粘锅往往是最佳选择了。不过,一旦有了明火的燃气灶,又或者是比较喜欢爆炒,那么涂层锅可能就不是那么适合了,毕竟温度过高涂层总有脱落的风险,此时一般就考虑无涂层不粘锅。
无涂层不粘锅也有五花八门的选择,比如朴素的铁锅、带蜂窝纹的不锈钢锅、有钛锅、纯钛锅等等,价格大体上也单调递增。不过用到最后,我觉得大部分人都会回归到朴素的铁锅。
20
Sep
自然数集中 N = ab + c 时 a + b + c 的最小值
By 苏剑林 | 2023-09-20 | 27723位读者 | 引用前天晚上微信群里有群友提出了一个问题:
对于一个任意整数$N > 100$,求一个近似算法,使得$N=a\times b+c$(其中$a,b,c$都是非负整数),并且令$a+b+c$尽量地小。
初看这道题,笔者第一感觉就是“这还需要算法?”,因为看上去自由度太大了,应该能求出个解析解才对,于是简单分析了一下之后就给出了个“答案”,结果很快就有群友给出了反例。这时,笔者才意识到这题并非那么平凡,随后正式推导了一番,总算得到了一个可行的算法。正当笔者以为这个问题已经结束时,另一个数学群的群友精妙地构造了新的参数化,证明了算法的复杂度还可以进一步下降!
整个过程波澜起伏,让笔者获益匪浅,遂将过程记录在此,与大家分享。
25
Dec
写了个刷论文的辅助网站:Cool Papers
By 苏剑林 | 2023-12-25 | 50402位读者 | 引用写在开头
一直以来,笔者都有日刷Arxiv的习惯,以求尽可能跟上领域内最新成果,并告诫自己“不进则退”。之前也有不少读者问我是怎么刷Arxiv的、有什么辅助工具等,但事实上,在很长的时间里,笔者都是直接刷Arxiv官网,并且没有用任何算法过滤,都是自己一篇篇过的。这个过程很枯燥,但并非不能接受,之所以不用算法初筛,主要还是担心算法漏召,毕竟“刷”就是为了追新,一旦算法漏召就“错失先机”了。
自从Kimi Chat发布后,笔者就一直计划着写一个辅助网站结合Kimi来加速刷论文的过程。最近几个星期稍微闲了一点,于是在GPT4、Kimi的帮助下,初步写成了这个网站,并且经过几天的测试和优化后,已经逐步趋于稳定,于是正式邀请读者试用。
Cool Papers:https://papers.cool
9
Jan
局部余弦相似度大,全局余弦相似度一定也大吗?
By 苏剑林 | 2024-01-09 | 25557位读者 | 引用在分析模型的参数时,有些情况下我们会将模型的所有参数当成一个整体的向量,有些情况下我们则会将不同的参数拆开来看。比如,一个7B大小的LLAMA模型所拥有的70亿参数量,有时候我们会将它当成“一个70亿维的向量”,有时候我们会按照模型的实现方式将它看成“数百个不同维度的向量”,最极端的情况下,我们也会将它看成是“七十亿个1维向量”。既然有不同的看待方式,那么当我们要算一些统计指标时,也就会有不同的计算方式,即局部计算和全局计算,这引出了局部计算的指标与全局计算的指标有何关联的问题。
本文我们关心两个向量的余弦相似度。如果两个大向量的维度被拆成了若干组,同一组对应的子向量余弦相似度都很大,那么两个大向量的余弦相似度是否一定就大呢?答案是否定的。特别地,这还跟著名的“辛普森悖论”有关。
问题背景
这个问题源于笔者对优化器的参数增量导致的损失函数变化量的分析。具体来说,假设优化器的更新规则是:
\begin{equation}\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \eta_t \boldsymbol{u}_t\end{equation}

最近评论