






 感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持!
感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持! 科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
27
Oct
低精度Attention可能存在有偏的舍入误差
By 苏剑林 | 2025-10-27 | 26662位读者 | Kimi 引用前段时间笔者在arXiv上刷到了论文《Why Low-Precision Transformer Training Fails: An Analysis on Flash Attention》,里面描述的实验现象跟我们在训练Kimi K2时出现的一些现象很吻合,比如都是第二层Attention开始出现问题。论文将其归因为低精度Attention固有的有偏误差,这个分析角度是比较出乎笔者意料的,所以饶有兴致地阅读了一番。
然而,论文的表述似乎比较让人费解——当然也有笔者本就不大熟悉低精度运算的原因。总之,经过多次向作者请教后,笔者才勉强看懂论文,遂将自己的理解记录在此,供大家参考。
结论简述
要指出的是,论文标题虽然点名了“Flash Attention”,但按照论文的描述,即便block_size取到训练长度那么大,相同的问题依然会出现,所以Flash Attention的分块计算并不是引起问题的原因,因此我们可以按照朴素的低精度Attention实现来简化分析。
21
Oct
MuP之上:1. 好模型的三个特征
By 苏剑林 | 2025-10-21 | 20824位读者 | Kimi 引用不知道大家有没有发现一个有趣的细节,Muon和MuP都是“Mu”开头,但两个“Mu”的原意完全不一样,前者是“MomentUm Orthogonalized by Newton-Schulz”,后者是“Maximal Update Parametrization”,可它们俩之间确实有着非常深刻的联系。也就是说,Muon和MuP有着截然不同的出发点,但最终都走向了相同的方向,甚至无意间取了相似的名字,似乎真应了那句“冥冥中自有安排”。
言归正传。总之,笔者在各种机缘巧合之下,刚好同时学习到了Muon和MuP,这大大加深了笔者对模型优化的理解,同时也让笔者开始思考关于模型优化更本质的原理。经过一段时间的试错,算是有些粗浅的收获,在此跟大家分享一下。
写在前面
按照提出时间的先后顺序,是先有MuP再有Muon,但笔者的学习顺序正好反过来,先学习了Muon然后再学习MuP,事后来看,这也不失为一个不错的学习顺序。
12
Oct
随机矩阵的谱范数的快速估计
By 苏剑林 | 2025-10-12 | 22939位读者 | Kimi 引用在《高阶MuP:更简明但更高明的谱条件缩放》的“近似估计”一节中,我们曾“预支”了一个结论:“一个服从标准正态分布的$n\times m$大小的随机矩阵,它的谱范数大致是$\sqrt{n}+\sqrt{m}$。”
这篇文章我们来补充讨论这个结论,给出随机矩阵谱范数的快速估计方法。
随机矩阵论
设有随机矩阵$\boldsymbol{W}\in\mathbb{R}^{n\times m}$,每个元素都是从标准正态分布$\mathcal{N}(0,1)$中独立重复地采样出来的,要求估计$\boldsymbol{W}$的谱范数,也就是最大奇异值,我们以$\mathbb{E}[\Vert\boldsymbol{W}\Vert_2]$为最终的估计结果。
8
Oct
DiVeQ:一种非常简洁的VQ训练方案
By 苏剑林 | 2025-10-08 | 31132位读者 | Kimi 引用对于坚持离散化路线的研究人员来说,VQ(Vector Quantization)是视觉理解和生成的关键部分,担任着视觉中的“Tokenizer”的角色。它提出在2017年的论文《Neural Discrete Representation Learning》,笔者在2019年的博客《VQ-VAE的简明介绍:量子化自编码器》也介绍过它。
然而,这么多年过去了,我们可以发现VQ的训练技术几乎没有变化,都是STE(Straight-Through Estimator)加额外的Aux Loss。STE倒是没啥问题,它可以说是给离散化运算设计梯度的标准方式了,但Aux Loss的存在总让人有种不够端到端的感觉,同时还引入了额外的超参要调。
幸运的是,这个局面可能要结束了,上周的论文《DiVeQ: Differentiable Vector Quantization Using the Reparameterization Trick》提出了一个新的STE技巧,它最大亮点是不需要Aux Loss,这让它显得特别简洁漂亮!
5
Oct
为什么线性注意力要加Short Conv?
By 苏剑林 | 2025-10-05 | 38650位读者 | Kimi 引用如果读者有关注模型架构方面的进展,那么就会发现,比较新的线性Attention(参考《线性注意力简史:从模仿、创新到反哺》)模型都给$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$加上了Short Conv,比如下图所示的DeltaNet:
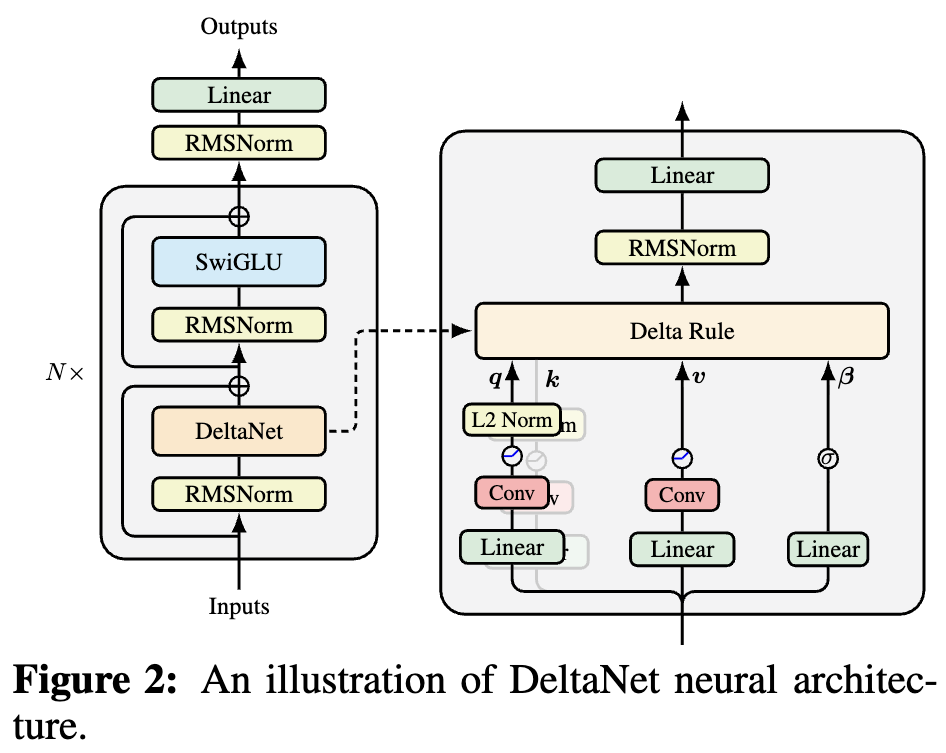
DeltaNet中的Short Conv
为什么要加这个Short Conv呢?直观理解可能是增加模型深度、增强模型的Token-Mixing能力等,说白了就是补偿线性化导致的表达能力下降。这个说法当然是大差不差,但它属于“万能模版”式的回答,我们更想对它的生效机制有更准确的认知。
接下来,笔者将给出自己的一个理解(更准确说应该是猜测)。
1
Oct
AdamW的Weight RMS的渐近估计(上)
By 苏剑林 | 2025-10-01 | 22051位读者 | Kimi 引用在《为什么Adam的Update RMS是0.2?》中,我们用平均场近似估计了Adam的Update RMS。不久后,读者 @EIFY 指出相同的结果已经出现在论文《Rotational Equilibrium: How Weight Decay Balances Learning Across Neural Networks》中。阅读后,笔者发现其中不仅包含了Update RMS的估计,还包含了Weight RMS的估计。
也就是说,AdamW训出来的模型,其权重的RMS是可以事先估计出来一个渐近结果的。大家会不会觉得这个结论有点意外?反正笔者第一次看到它是颇为意外的,直觉上权重模长是模型根据训练集自己学出来的,结果它告诉我这已经隐藏在优化器的超参中,可谓很反直觉了。
这篇文章我们还是用平均场近似方法,来复现对Weight RMS的渐近估计。
22
Sep
重新思考学习率与Batch Size(四):EMA
By 苏剑林 | 2025-09-22 | 26658位读者 | Kimi 引用我们在《重新思考学习率与Batch Size(二):平均场》中提到,关注SignSGD的原因之一是我们通常将它作为Adam的理论近似,这是Adam做理论分析时常用的简化策略。除了分析学习率的场景外,在《配置不同的学习率,LoRA还能再涨一点?》、《初探MuP:超参数的跨模型尺度迁移规律》等地方我们也用了这个简化。
然而,SignSGD真是Adam的良好近似吗?一个明显差异是SignSGD的Update RMS总是1,而Adam并非如此。笔者发现,导致这一差异的核心原因是动量,它普遍存在于Adam、Lion、Muon等优化器中。所以,本文我们来考察动量——更广义地说是EMA——的影响。
问题分析
从Adam的视角看,SignSGD对应$\beta_1=\beta_2=0$这个特例,或者对应于Adam的第一步更新量(不管$\beta_1,\beta_2$如何)。因此,我们认为它跟Adam肯定有一些共性,能够捕捉到一些通用的规律。
15
Sep
重新思考学习率与Batch Size(三):Muon
By 苏剑林 | 2025-09-15 | 40109位读者 | Kimi 引用前两篇文章《重新思考学习率与Batch Size(一):现状》和《重新思考学习率与Batch Size(二):平均场》中,我们主要是提出了平均场方法,用以简化学习率与Batch Size的相关计算。当时我们分析的优化器是SGD、SignSGD和SoftSignSGD,并且主要目的是简化,本质上没有新的结论。
然而,在如今的优化器盛宴中,怎能少得了Muon的一席之地呢?所以,这篇文章我们就来尝试计算Muon的相关结论,看看它的学习率与Batch Size的关系是否会呈现出新的规律。
基本记号
众所周知,Muon的主要特点就是非Element-wise的更新规则,所以之前在《当Batch Size增大时,学习率该如何随之变化?》和《Adam的epsilon如何影响学习率的Scaling Law?》的Element-wise的计算方法将完全不可用。但幸运的是,上篇文章介绍的平均场依然好使,只需要稍微调整一下细节。

最近评论