






21
Mar
细水长flow之可逆ResNet:极致的暴力美学
By 苏剑林 | 2019-03-21 | 162615位读者 | 引用今天我们来介绍一个非常“暴力”的模型:可逆ResNet。
为什么一个模型可以可以用“暴力”来形容呢?当然是因为它确实非常暴力:它综合了很多数学技巧,活生生地(在一定约束下)把常规的ResNet模型搞成了可逆的!
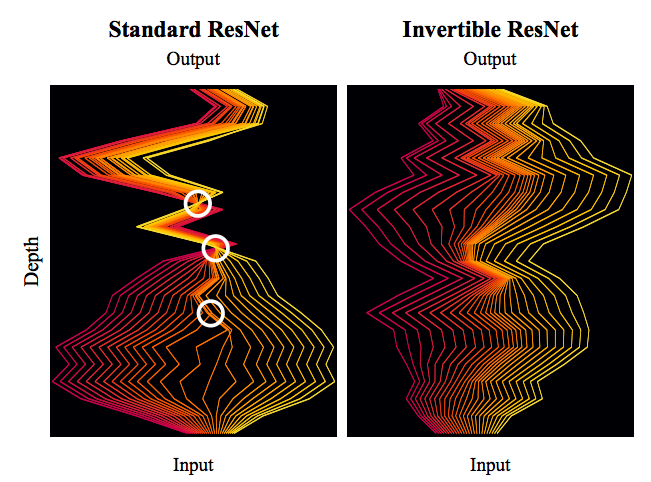
标准ResNet与可逆ResNet对比图。可逆ResNet允许信息无损可逆流动,而标准ResNet在某处则存在“坍缩”现象。
模型出自《Invertible Residual Networks》,之前在机器之心也报导过。在这篇文章中,我们来简单欣赏一下它的原理和内容。
可逆模型的点滴
为什么要研究可逆ResNet模型?它有什么好处?以前没有人研究过吗?
可逆的好处
可逆意味着什么?
意味着它是信息无损的,意味着它或许可以用来做更好的分类网络,意味着可以直接用最大似然来做生成模型,而且得益于ResNet强大的能力,意味着它可能有着比之前的Glow模型更好的表现~总而言之,如果一个模型是可逆的,可逆的成本不高而且拟合能力强,那么它就有很广的用途(分类、密度估计和生成任务,等等)。
10
Mar
“让Keras更酷一些!”:分层的学习率和自由的梯度
By 苏剑林 | 2019-03-10 | 127818位读者 | 引用高举“让Keras更酷一些!”大旗,让Keras无限可能~
今天我们会用Keras做到两件很重要的事情:分层设置学习率和灵活操作梯度。
首先是分层设置学习率,这个用途很明显,比如我们在fine tune已有模型的时候,有些时候我们会固定一些层,但有时候我们又不想固定它,而是想要它以比其他层更低的学习率去更新,这个需求就是分层设置学习率了。对于在Keras中分层设置学习率,网上也有一定的探讨,结论都是要通过重写优化器来实现。显然这种方法不论在实现上还是使用上都不友好。
然后是操作梯度。操作梯度一个最直接的例子是梯度裁剪,也就是把梯度控制在某个范围内,Keras内置了这个方法。但是Keras内置的是全局的梯度裁剪,假如我要给每个梯度设置不同的裁剪方式呢?甚至我有其他的操作梯度的思路,那要怎么实施呢?不会又是重写优化器吧?
本文就来为上述问题给出尽可能简单的解决方案。
6
Mar
O-GAN:简单修改,让GAN的判别器变成一个编码器!
By 苏剑林 | 2019-03-06 | 332353位读者 | 引用本文来给大家分享一下笔者最近的一个工作:通过简单地修改原来的GAN模型,就可以让判别器变成一个编码器,从而让GAN同时具备生成能力和编码能力,并且几乎不会增加训练成本。这个新模型被称为O-GAN(正交GAN,即Orthogonal Generative Adversarial Network),因为它是基于对判别器的正交分解操作来完成的,是对判别器自由度的最充分利用。

FFHQ线性插值效果图
26
Feb
非对抗式生成模型GLANN的简单介绍
By 苏剑林 | 2019-02-26 | 86863位读者 | 引用前段时间看到facebook发表了一个非对抗的生成模型GLANN(去年12月挂在arxiv上),号称用非对抗的方式也能生成1024的高清人脸,于是饶有兴致地阅读了一番,确实有点收获,但也有点失望。至于为啥失望,大家阅读下去就明白了。
原论文:《Non-Adversarial Image Synthesis with Generative Latent Nearest Neighbors》
机器之心介绍:《为什么让GAN一家独大?Facebook提出非对抗式生成方法GLANN》
效果图:

GLANN效果图
22
Feb
巧断梯度:单个loss实现GAN模型
By 苏剑林 | 2019-02-22 | 57470位读者 | 引用我们知道普通的模型都是搭好架构,然后定义好loss,直接扔给优化器训练就行了。但是GAN不一样,一般来说它涉及有两个不同的loss,这两个loss需要交替优化。现在主流的方案是判别器和生成器都按照1:1的次数交替训练(各训练一次,必要时可以给两者设置不同的学习率,即TTUR),交替优化就意味我们需要传入两次数据(从内存传到显存)、执行两次前向传播和反向传播。
如果我们能把这两步合并起来,作为一步去优化,那么肯定能节省时间的,这也就是GAN的同步训练。
(注:本文不是介绍新的GAN,而是介绍GAN的新写法,这只是一道编程题,不是一道算法题~)
如果在TF中
15
Feb
能量视角下的GAN模型(二):GAN=“分析”+“采样”
By 苏剑林 | 2019-02-15 | 177358位读者 | 引用在这个系列中,我们尝试从能量的视角理解GAN。我们会发现这个视角如此美妙和直观,甚至让人拍案叫绝。
上一篇文章里,我们给出了一个直白而用力的能量图景,这个图景可以让我们轻松理解GAN的很多内容,换句话说,通俗的解释已经能让我们完成大部分的理解了,并且把最终的结论都已经写了出来。在这篇文章中,我们继续从能量的视角理解GAN,这一次,我们争取把前面简单直白的描述,用相对严密的数学语言推导一遍。
跟第一篇文章一样,对于笔者来说,这个推导过程依然直接受启发于Bengio团队的新作《Maximum Entropy Generators for Energy-Based Models》。
原作者的开源实现:https://github.com/ritheshkumar95/energy_based_generative_models
本文的大致内容如下:
1、推导了能量分布下的正负相对抗的更新公式;
2、比较了理论分析与实验采样的区别,而将两者结合便得到了GAN框架;
3、导出了生成器的补充loss,理论上可以防止mode collapse;
4、简单提及了基于能量函数的MCMC采样。
30
Jan
能量视角下的GAN模型(一):GAN=“挖坑”+“跳坑”
By 苏剑林 | 2019-01-30 | 148457位读者 | 引用
“看那挖坑的人,有啥不一样~”
在这个系列中,我们尝试从能量的视角理解GAN。我们会发现这个视角如此美妙和直观,甚至让人拍案叫绝。
本视角直接受启发于Benjio团队的新作《Maximum Entropy Generators for Energy-Based Models》,这篇文章前几天出现在arxiv上。当然,能量模型与GAN的联系由来已久,并不是这篇文章的独创,只不过这篇文章做得仔细和完善一些。另外本文还补充了自己的一些理解和思考上去,力求更为易懂和完整。
作为第一篇文章,我们先来给出一个直白的类比推导:GAN实际上就是一场前仆后继(前挖后跳?)的“挖坑”与“跳坑”之旅~
总的来说,本文的大致内容如下:
1、给出了GAN/WGAN的清晰直观的能量图像;
2、讨论了判别器(能量函数)的训练情况和策略;
3、指出了梯度惩罚一个非常漂亮而直观的能量解释;
4、讨论了GAN中优化器的选择问题。
27
Jan
“让Keras更酷一些!”:随意的输出和灵活的归一化
By 苏剑林 | 2019-01-27 | 129666位读者 | 引用继续“让Keras更酷一些!”系列,让Keras来得更有趣些吧~
这次围绕着Keras的loss、metric、权重和进度条进行展开。
可以不要输出
一般我们用Keras定义一个模型,是这样子的:
x_in = Input(shape=(784,))
x = x_in
x = Dense(100, activation='relu')(x)
x = Dense(10, activation='softmax')(x)
model = Model(x_in, x)
model.compile(loss='categorical_crossentropy ',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)

最近评论