






29
Jun
UniVAE:基于Transformer的单模型、多尺度的VAE模型
By 苏剑林 | 2021-06-29 | 106754位读者 |大家都知道,Transformer的$\mathcal{O}(n^2)$复杂度是它的“硬伤”之一。不过凡事有弊亦有利,$\mathcal{O}(n^2)$的复杂度也为Transformer带来很大的折腾空间,我们可以灵活地定制不同的attention mask,来设计出不同用途的Transformer模型来,比如UniLM、K-BERT等。
本文介绍笔者构思的一个能用于文本的UniVAE模型,它沿用类似UniLM的思路,将VAE做到了一个Transformer模型里边,并且还具备多尺度特性~
UniAE #
VAE(Variational Autoencoder)这里就不科普了,本站已经有多篇文章进行介绍,大家自行搜索就好。VAE可以理解为带有正则项的AE(Autoencoder),一般情况下,Encoder负责将输入编码为一个向量,并且满足一定的分布,而Decoder则负责将编码向量重构为输入。所以很显然,要实现UniVAE,首先要实现对应的UniAE。
在《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中,我们已经介绍了UniLM(Uni是Unified的缩写),它通过下图左的Attention Mask来使得Transformer能完成Seq2Seq任务。然而UniLM并不是我们要寻找的UniAE,因为UniLM的Decoder部分关联到的是输入的整个编码序列,而不是单个向量。

UniLM式Attention Mask

UniAE式Attention Mask
不过,我们可以在UniLM的基础上,进一步调整Attention Mask为上图右的模式,这样一来,解码的时候只能依赖于编码部分的[CLS]向量以及当前已完成的解码结果,这就是我们要找的UniAE式Attention Mask了。因为对于输入来说,它只依赖于[CLS]向量,而[CLS]向量的大小是固定的,所以相当于说生成过程中的源信息只是一个固定大小的向量,而输入也被编码成这个固定大小的向量,这就是AE功能了。
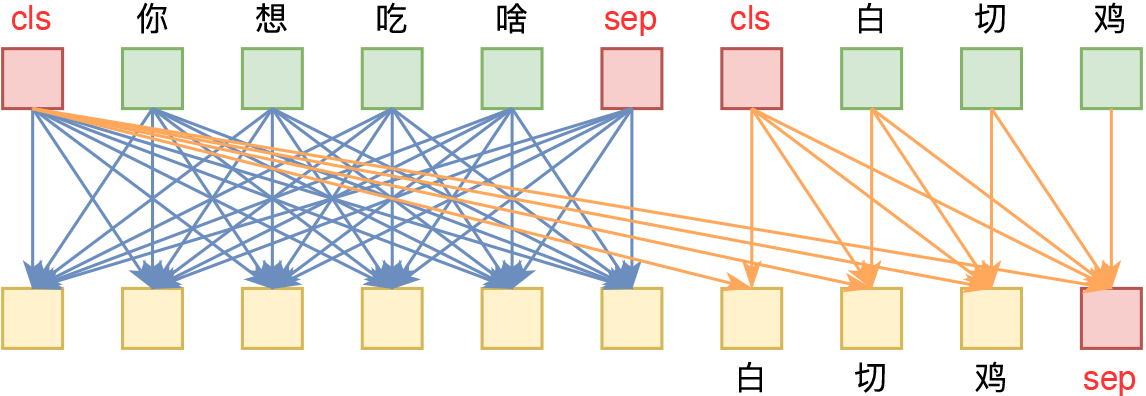
UniAE式Attention关联示意图
多尺度 #
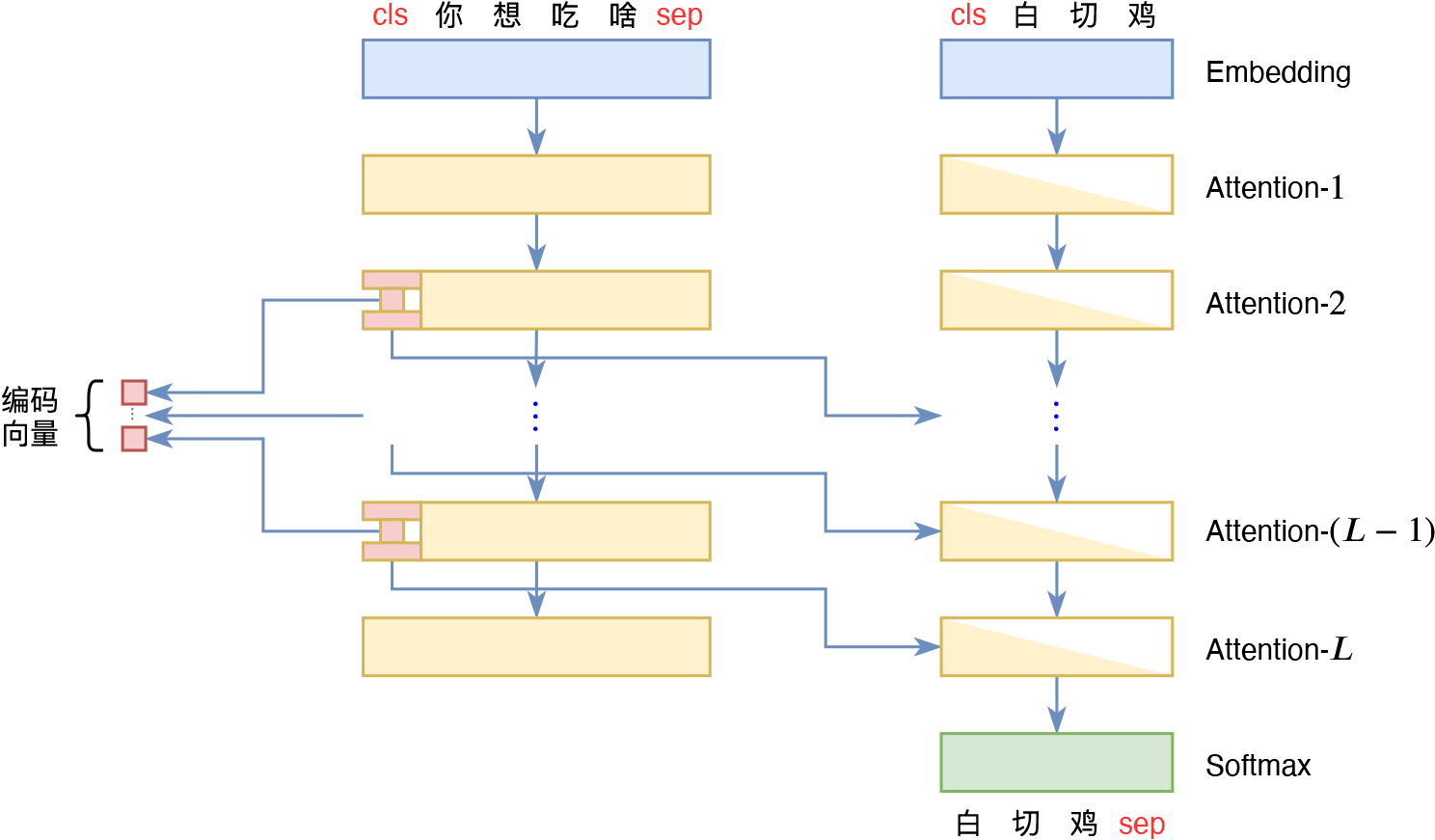
也就是说,通过UniAE式Attention Mask,我们可以实现类似UniLM的Seq2Seq模型,它等效于Encoder将输入编码为固定长度的向量,然后Decoder对该向量进行解码。如果还觉得不够清晰,我们还可以分拆为Encoder-Decoder架构来理解,如下图所示:
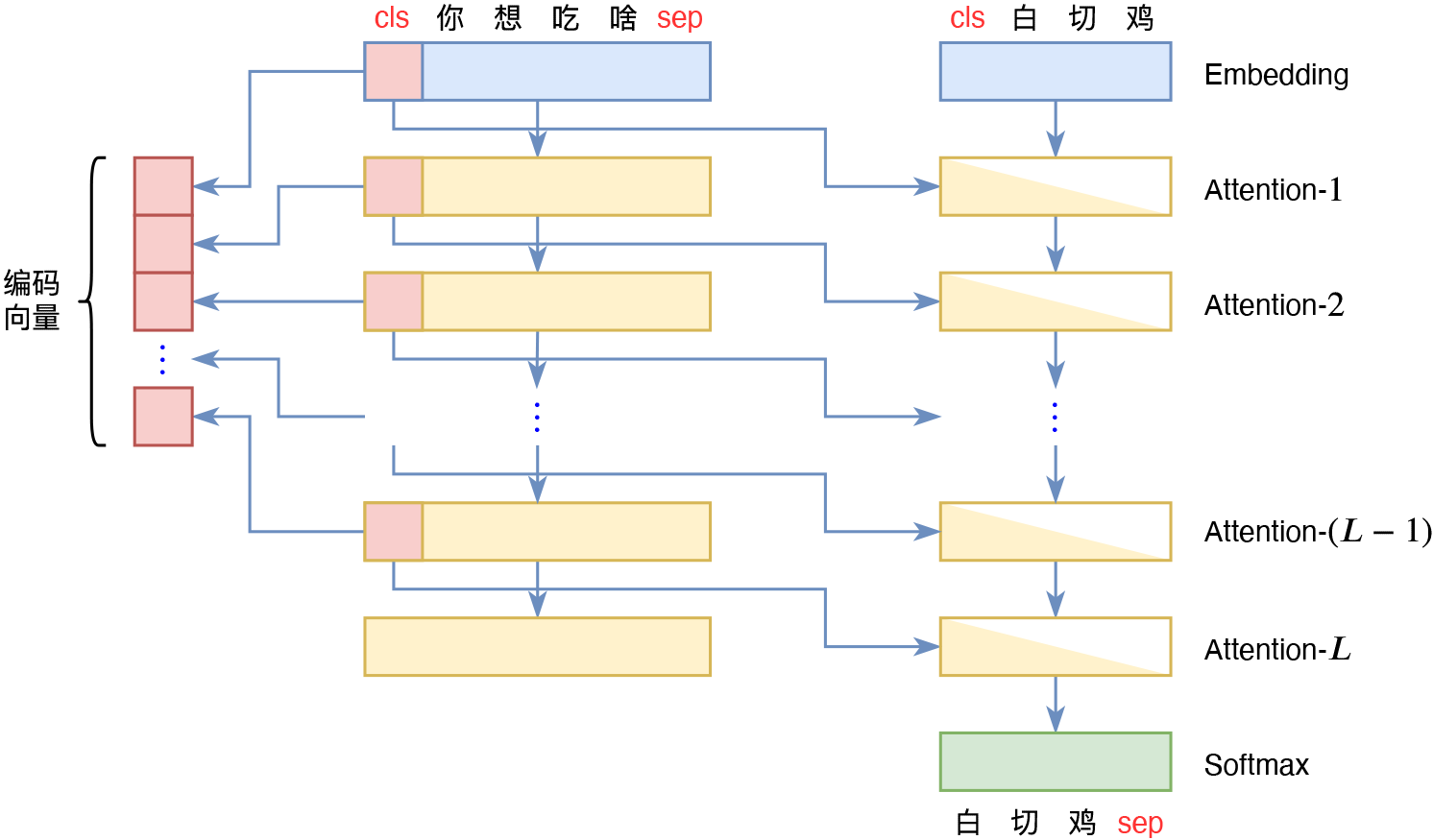
分拆为Encoder-Decoder结构来理解
跟常规的Seq2Seq架构不同的地方在于,这里的Encoder和Decoder的权重是共享的。从上图还可以看出,如果我们每一层Attention都加上这种Mask,那么Decoder将依赖于每一层输入的[CLS]向量,这也就意味如果有$L$层Attention,那么这$L$层Attention的输入序列的所有[CLS]向量拼接起来,才是输入文本的完整的编码向量(当然,第一层可以去掉,因为第一层的[CLS]是其Embedding向量,对于每个输入来说它都是常向量),单独某一层的[CLS]向量,并不是完整编码向量。
对于Decoder来说,每一层Attention都有一个[CLS]向量传入,这其实就形成了一种多尺度结构。在CV中,最先进的生成模型基本上都是多尺度结构了,如StyleGAN、Glow、NVAE等,但是NLP中似乎还不多见。不难想象,在多尺度结构中,不同层次的输入对生成结果的调控程度也是不同的,越靠近输入层的变量,控制的部分越是“无伤大雅”,而越靠近输出层的变量,则控制着生成结果的关键信息。所以理想情况下,训练好一个多尺度模型后,我们可以通过编辑不同层级的输入变量,来实现对生成结果的不同层次的控制。
降低维度 #
有些读者可能会想到,要是每层的维度是$d$,共有$L$层,那么全部[CLS]向量拼接起来就是$Ld$维了,对于BERT base来说就是$12\times 768 = 9216$维了,这编码向量维度是不是太大了?确实如此,对于一个普通的AE或者VAE来说,近万维的编码向量是太大了。
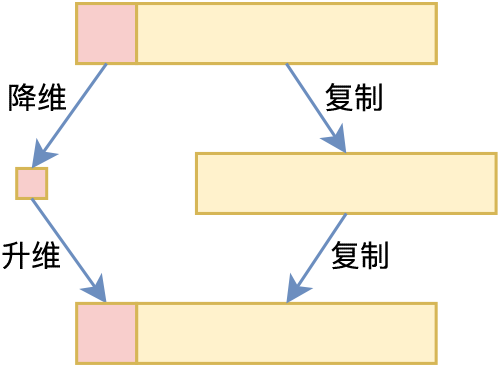
降维过程示意图
其实解决方法很简单,我们只需要将每层的[CLS]向量用一个全连接层先降维,然后再用另一个全连接层升维,最后拼接到剩下的$(L-1)$个$d$维向量就行了,如上图所示。这样的话,虽然输入序列还是$L\times d$大小,但事实上[CLS]向量可以用一个更低维的向量表达出来,我们只需要把每一层的这个更低维向量拼接起来,作为总的编码向量就行了。
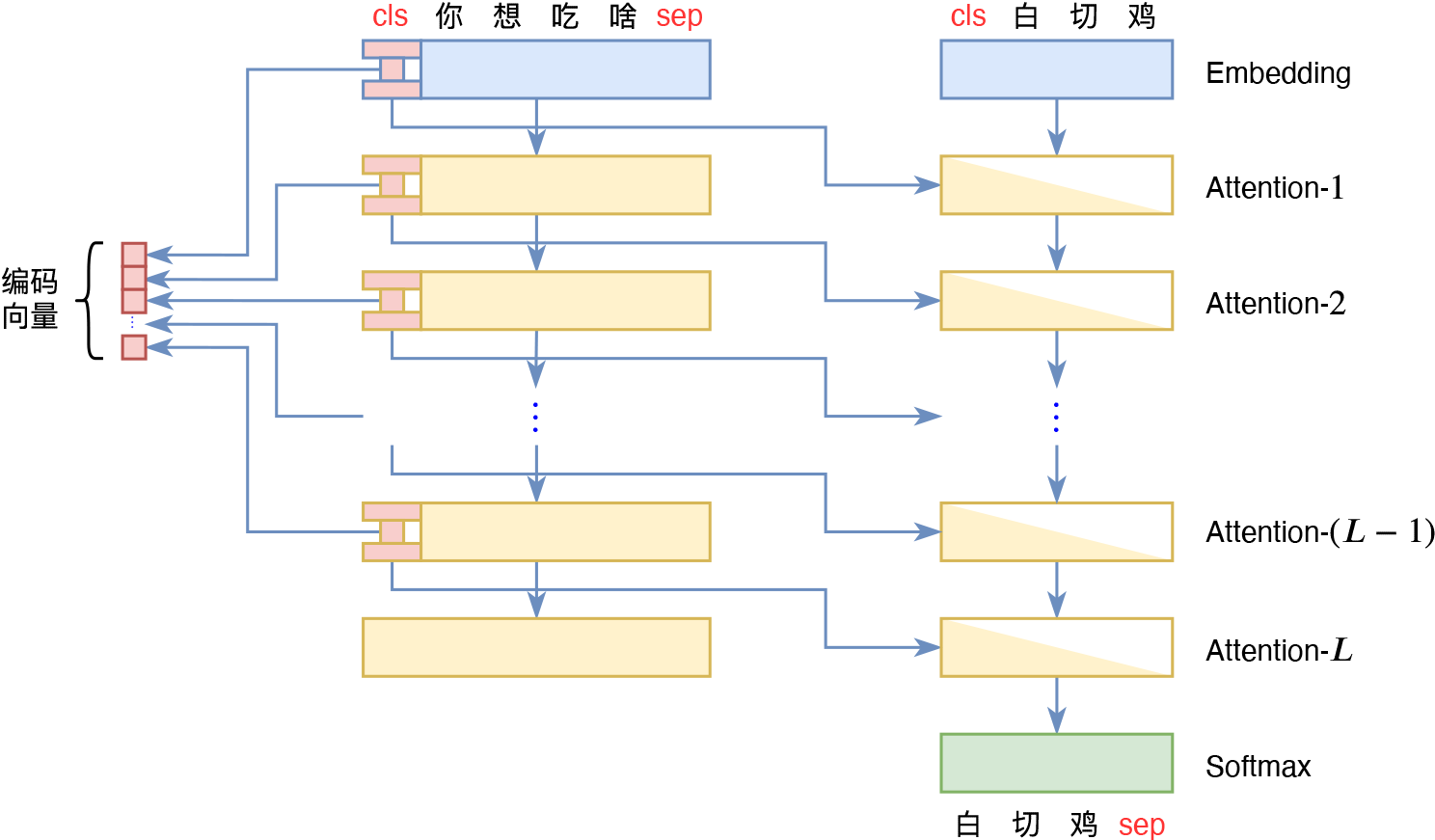
降维后的Encoder-Decoder示意图
解耦能力 #
前面的设计和讨论还只是针对普通的AE的,对于VAE来说,就是往AE的编码向量里边加入重参数操作,然后损失函数里边加入KL散度项,所以,设计好UniAE后,理论上就已经设计好UniVAE了。
不过,实际操作的时候,我们还有改进的空间。理论上来说,训练好VAE是具有一定的解耦(Disentanglement)能力的,也就是说,隐变量的每个维度是独立无关的,它们分别控制生成结果的某一方面,可以随机调节。不难理解,解耦是一件非常有挑战性的事情,所以如果VAE的Encoder能编码出解耦的编码向量,那么其拟合能力必然也是比较强的,换言之,其结构需要有一定的复杂了。
我们再来看UniAE的Encoder,它的编码向量是每一层的[CLS]向量(或者对应的低维向量)的拼接,对于前面的层来说,它们的[CLS]向量仅仅是有限几层的Transformer的输出,它们的编码能力是很弱的,并不足以编码出解耦的向量,因此将它们作为VAE的隐变量是不合适的。
所以,在实际设计UniVAE的时候,我们不能使用UniAE的所有[CLS]向量作为编码向量,应该设置一个起始层数,Decoder只使用大于这个层数的[CLS]向量,而小于等于这个层数的[CLS]向量则不使用,此时相对于使用下图右的Attention Mask:
靠近输出层,使用UniAE式Attention Mask

靠近输入层,使用独立式Attention Mask
此时它等效于如下的Encoder-Decoder结构:
前两层Attention使用独立式Mask的效果示意图
其他细节 #
至此,UniVAE的关键部分已经介绍完毕了,下面分享一下在实现过程中一些比较重要的细节。
首先是长度泄漏问题。不管是UniLM还是UniVAE,因为Encoder和Decoder整合成了一个模型,所以我们都是将输入输出拼接起来作为单个样本训练的,这样的话每个样本在Decoder部分的起始位置就不一样了,取决于输入文本的长度,这就意味着输入长度是也是作为了输入条件传入到了Decoder中,这就是长度泄漏。
这个问题有两个解决方案:第一个就是所有输入都通过截断或者填充来变为同一长度,这就不会造成长度泄漏了;第二个就更简单了,干脆啥都不做,即确实把长度当成条件输入,解码时通过控制起始位置来控制生成长度,但这样可能带来的问题是长度信息可能没有跟编码向量完全解耦,因此同一编码向量配上不同的长度可能会得到不合理的结果。
然后是层数和维度的选择问题。前面说了,为了让隐变量具有较好的解耦能力,我们将前$k$层的Attention加上独立式Attention Mask,剩下的$L-k$层则加上UniAE式Attention Mask。那么这个$k$怎么选择呢?这是一个需要仔细调整的超参数,比较小的$k$能保留更多的信息,有利于重构,但不利于解耦;反之较大的$k$则更有利于解耦,但是不利于重构。在笔者的实验中,使用的是$k=8$。
类似的问题出现在降维的维度选择上,较大的维度自然是有利于重构的,但也不利于解耦,反之则利于解耦而有损重构性能。这个参数需要根据任务本身的复杂度来具体调整,调整的大致方向是观察随机采样效果和重构效果,如果随机采样出来的样本多数可读、自然句子的重构效果也不错,那么说明这个维度适中了,否则则需要相应地调整。
最后,值得一提的是,UniAE的设计不单单可以用来做VAE,还可以用于构建VQ-VAE,只需要对每个[CLS]向量做一下量化,就成为了一个将不定长句子编码为定长离散序列的VQ-VAE模型了。
参考实现 #
这里给出一个UniVAE参考实现:
代码里使用的是vMF-VAE变体,基于bert4keras实现,基础架构是RoFormer,当然也可以换成BERT。下面演示的是用问句训练的UniVAE的效果。
随机采样效果:
我在steam下载的游戏,怎样能在电脑上玩啊???
呼市男科医院哪家比较好实惠
我血压高,我妈妈手脚麻木,是怎么回事呀
怎样查询交通违章记录和处罚
为什么我提问的问题有点卡顿
小米2s用的是移动卡还是联通卡
幼儿园怎么发展幼儿教育
英国读研学校排名对于英国留学生来说重要吗
有专业的关于excel表格数据库的培训机构吗?
为什么一到晚上就容易咳嗽,不睡觉就不咳
重构效果:
原句:数字电视机顶盒坏了,可以免费维修吗
重构:数字电视机顶盒坏了可以换吗?原句:青椒跟什么炒好吃
重构:青椒跟什么炒好吃原句:王者荣耀carryyou什么意思
重构:王者荣耀carry芈月什么意思原句:没感冒老是咳嗽要吃什么药好
重构:没感冒老是咳嗽要吃什么药好原句:沁园(金科西城大院店)怎么样,好不好的默认点评
重构:沁园(金源店)怎么样,好不好的默认点评
随机替换前32维隐变量:
原句:牙龈出血要吃什么药?
结果:牙龈出血还出血吃什么消炎药好
牙龈出血吃阿莫西林有效吗
牙龈出血是肝火旺吗?
牙龈出血去医院检查大概要多少钱?
牙龈出血去牙科看什么科室
牙龈出血去深圳哪里看牙科好原句:广州和深圳哪个更好玩?
结果:广州和深圳哪个城市发展得好? 薪资高?
广州和深圳,哪个发达?深圳到广州的飞机票贵吗?
广州和深圳比哪个好
广州和深圳哪个人均gdp高
广州和深圳房价涨幅
广州和深圳自考一样吗
随机替换后16维隐变量:
原句:牙龈出血要吃什么药?
结果:未来21年做什么生意好?
湿疹给身体有什么伤害?
朗逸现在要买什么配置?
马来西亚签证要多少钱?
早上给孩子吃什么水果好?
头晕发热去医院看什么科?原句:广州和深圳哪个更好玩?
结果:99和98相差多少呢?
微信和支付宝怎么更换手机号
我的指甲和肉很不一样怎么回事?
吃了甲硝唑多久才能喝酒?
桂圆和红枣可以一起泡茶吗?
小米和华为哪个更好点?
可以看到,随机采样和重构的效果都不错的,而通过随机替换不同维度的隐变量,我们可以大致观察到多尺度结构的效果:替换前面部分维度的隐变量,大致上保持了主题词不变;替换后面部分维度的隐变量,大致上保持了句式不变。当然,自然语言的结构性本身就很弱,因此例子中通常也夹杂了一些例外情况。
文章小结 #
本文介绍了笔者构思的UniVAE设计,它沿用类似UniLM的思路,通过特定的Attention Mask将VAE做到了一个Transformer模型里边,并且还具备多尺度特性。除了常规的VAE模型外,该设计还可以用于VQ-VAE等模型。
转载到请包括本文地址:https://kexue.fm/archives/8475
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jun. 29, 2021). 《UniVAE:基于Transformer的单模型、多尺度的VAE模型 》[Blog post]. Retrieved from https://kexue.fm/archives/8475
@online{kexuefm-8475,
title={UniVAE:基于Transformer的单模型、多尺度的VAE模型},
author={苏剑林},
year={2021},
month={Jun},
url={\url{https://kexue.fm/archives/8475}},
}

June 29th, 2021
好文章,占个座;能问下UniVAE相比前面基于UniLM的simbert模型,生成效果怎么样呢
UniVAE在生成感觉可控性操作性很强
这是“VAE + 适当的模型结构”的效果,UniVAE只是一种模型设计,本身没有特别的作用。
UniVAE跟SimBERT都不是同一类型的模型,没什么可比较性。
如果你用UniVAE和UniLM分别训练一个seq2seq模型,单看生成效果来看肯定是UniLM更好,因为UniVAE要将输入压缩为一个固定长度的向量,这对于seq2seq来说是不必要的约束。
June 29th, 2021
苏神,这些样例真的不是cherrypick的吗……总感觉用一个向量就把原句重构得这么好有点违反直觉
没有挑过的,确实是随机抽样的重构效果。其实这个重构效果不算好了,如果愿意牺牲随机采样效果,那么几乎可以达到每个句子都完全重构出来。
只要模型足够大,重构是一件很容易的事情,VAE的难度不在于重构,而在于随机采样,随机采样结果的可读性才是真的难,因为这意味着编码特征已经被很好地解耦了,这是非常困难的~
July 11th, 2021
如果把得到的CLS作为sentence embedding,所包含的信息足不足够区分不同句子,来做语义相似度任务?
既然能完成重构,说明cls向量是可以用来代表原句子的。
但是,要注意“包含足够的语义信息”,不代表“可以用向量的余弦相似度衡量句子的相似度”,这是两个不同的问题。可以完成重构,说明该向量可以用来表示句子本身了,但是两个句子的相似度能否用这两个向量的余弦相似度近似,这并不是一个显然可以看出答案的问题。
July 13th, 2021
有2个问题请教,
==>1.apply_final_layers函数中的Pooler-Dense提取的CLS,就是最后一层Transofmer输出的CLS吗?
==>2.如果要使用UniVAE的CLS做下游的分类任务,最好也用这里的多层降维后的CLS concate,而不能用1中Pooler-Dense提取的CLS(信息不完整)?
1、是;2、理论上是
July 29th, 2021
苏神,有torch 的版本的代码嘛, 唉 理论看的懂 代码不会写 只会 torch
不好意思,只要是我自己写的代码,就不大可能会有pytorch版。
September 3rd, 2021
[CLS]向量真滴好神奇,在这里作为沟通了输入(编码)与输出(解码)之间的桥梁。
顺便问下苏神,本篇的内容写成文章发表了吗?担心被人偷走 idea~
有读者一起帮忙监督着,偷不了的~
December 28th, 2021
请问苏神,您训练的形式是 “你想吃啥” --> z --> “你想吃啥” 这种还原式的, 还是像图例中的“你想吃啥” --> z --> “白切鸡”这种对话形式呢?如果是前者,能否直接应用在对话任务上呀?
正常的VAE都是前者。
明白了,感谢苏神回复!
December 28th, 2021
@郑佳斌|comment-18106
看代码是前者:
```python
batch_segment_ids = np.concatenate([zeros, ones], axis=1)
batch_token_ids = np.concatenate([batch_token_ids] * 2, axis=1)
```
确实,感谢大佬!
April 6th, 2022
苏神,我想复现一下UniVAE的代码,之后再转换到我自己的数据集上,所以想问问您上面使用的数据集synonyms_shuf.json的格式是什么样的?d['text'], d['synonyms']具体的格式是什么?或者从哪可以获取您的数据集?谢谢
不用在意d['text'], d['synonyms']是什么格式,只需要知道corpus每次yield的是一个纯文本。
May 5th, 2022
从上图还可以看出,如果我们每一层Attention都加上这种Mask,那么Decoder将依赖于每一层输入的[CLS]向量,这也就意味如果有L层Attention,那么这L层Attention的输入序列的所有[CLS]向量拼接起来,才是输入文本的完整的编码向量
--------------
hello,苏神,这一段话没太理解您的意思,为什么输入文本的完整的编码向量是:L层Attention的输入序列的所有[CLS]向量的拼接呢?
因为它就是读取到了每一层的[CLS]向量,所以所有的[CLS]向量拼接起来才够。