






24
Mar
基于CNN和VAE的作诗机器人:随机成诗
By 苏剑林 | 2018-03-24 | 171123位读者 |前几日写了一篇VAE的通俗解读,也得到了一些读者的认可。然而,你是否厌倦了每次介绍都只有一个MNIST级别的demo?不要急,这就给大家带来一个更经典的VAE玩具:机器人作诗。
为什么说“更经典”呢?前一篇文章我们说过用VAE生成的图像相比GAN生成的图像会偏模糊,也就是在图像这一“仗”上,VAE是劣势。然而,在文本生成这一块上,VAE却漂亮地胜出了。这是因为GAN希望把判别器(度量)也直接训练出来,然而对于文本来说,这个度量很可能是离散的、不可导的,因此纯GAN就很难训练了。而VAE中没有这个步骤,它是通过重构输入来完成的,这个重构过程对于图像还是文本都可以进行。所以,文本生成这件事情,对于VAE来说它就跟图像生成一样,都是一个基本的、直接的应用;对于(目前的)GAN来说,却是艰难的象征,是它挥之不去的“心病”。
嗯,古有曹植七步作诗,今有VAE随机成诗,让我们开始吧~
模型 #
对于很多人来说,诗是一个很美妙的玩意,美妙之处在于大多数人都不真正懂得诗,但大家对诗的模样又有一知半解的认识。因此,只要生成的“诗”稍微像模像样一点,我们通常都会认为机器人可以作诗了。因此,所谓作诗机器人,是一个纯粹的玩具了,能作几句诗,也不意味着普通语言的生成能力有多好,也不意味着我们对NLP的理解有多深。
CNN + VAE #
就本文的玩具而言,其实是一个比较简单的模型,主要是把一维CNN和VAE结合了起来。因为生成的诗长度是固定的,所以不管是encoder还是decoder,我都只是用了纯CNN来做。模型的结构图大概是:
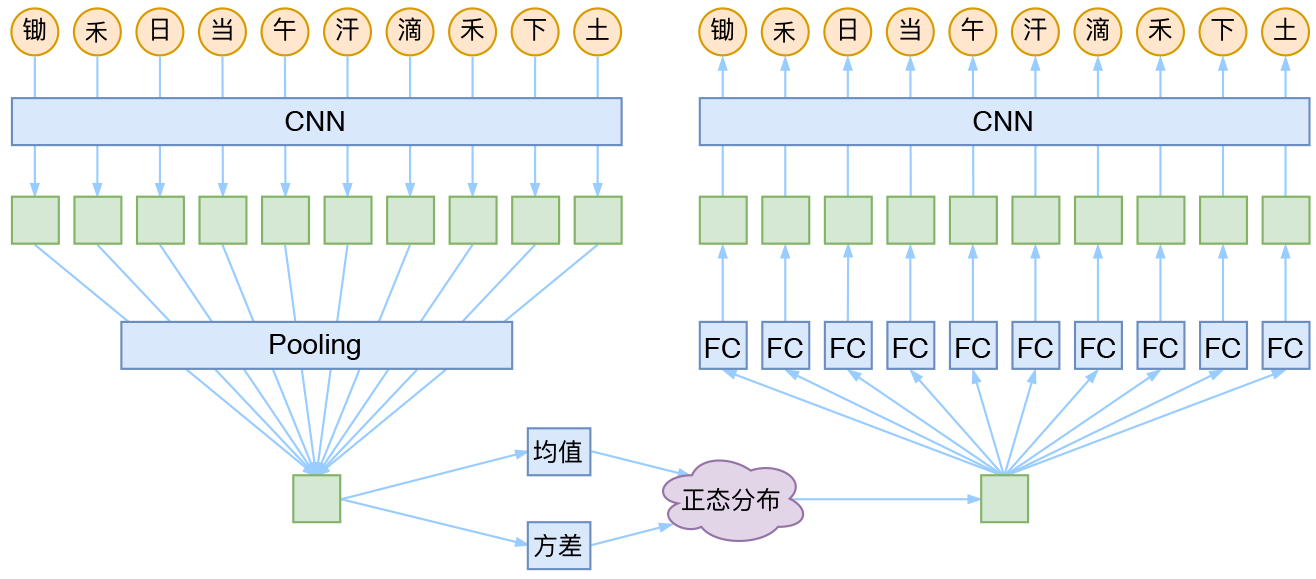
cnn + vae 诗歌生成模型
具体来说,是先将每个字embedding为向量,然后用层叠CNN来做编码,接着池化得到一个encoder的结果,根据这个结果生成计算均值和方差,然后生成正态分布并重新采样。在解码截断,由于现在只有一个encoder的输出结果,而最后要输出多个字,所以先接了多个不同的全连接层,得到多样的输出,然后再接着全连接层。
GCNN #
这里的CNN不是普通的CNN+ReLU,而是facebook提出的GCNN,其实就是做两个不同的、外形一样的CNN,一个不加激活函数,一个用sigmoid激活,然后把结果乘起来。这样一来sigmoid那部分就相当于起到了一个“门(gate)”的作用。
我第一次看到GCNN是在论文《Language Modeling with Gated Convolutional Networks》中,然后在《Convolutional Sequence to Sequence Learning》中再次看到了。在笔者的《分享一个slide:花式自然语言处理》也有简单介绍。
经过实测,在很多NLP任务上,GCNN比普通的CNN+ReLU明显要好。
实验 #
实验还是基于Python2.7和Keras(Tensorflow后端)完成~
代码 #
有了前述讨论,并且结合Keras自带的VAE例子,其实把整个模型实现就不困难了。由于只为了演示,这里仅选了最简单的五言诗,而且也不要求生成完整的一首诗,只要生成一句(10个字),这样其实更像对对联了。
代码:https://github.com/bojone/vae/blob/master/vae_shi.py
训练语料用的是全唐诗,也已经放在github上面了。模型并没有经过充分的调参,这留给有兴趣的读者慢慢折腾和增强了。
训练 #
为了观察训练过程中生成的诗句变化,所以写了个evaluator,效果如图:
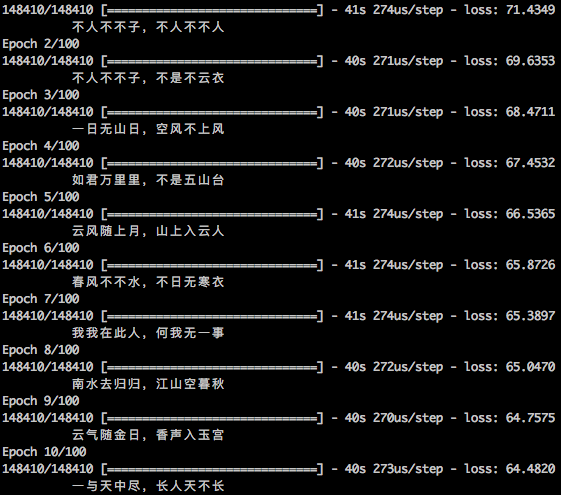
作诗机器人训练过程
可以看到,随着训练次数的增加,诗句质量确实在提高。
测试 #
下面是训练好的模型随机生成的一些诗句,严格来看并不怎么样,这毕竟只是随机数到诗句的映射,随机出诗罢了~可以看得出,这些“诗句”在对仗和平仄方面还是像模像样的。
出上无花客,相来一日时。
从瞻大车策,萧盖偃车矛。
今见青衣去,萧凉白叶风。
帝城今不战,征罪在天兵。
鹤仰临山里,逶留出太回。
画关斜过水,残色迥过杨。
上道皆有战,四门不如兵。
涧烟含雨沥,风影动风风。
登回一落景,一处更相期。
芳酒不无醉,长楼酒更春。
天月满云管,楚女长南闻。
明今今有矣,不得道无生。
朝明开绿菊,香影下红枝。
世外相扁处,逍遥无旧目。
唯闻含玉色,讵见月光光。
春风将乐节,风服未谁娱。
万年君何在,今年酒未新。
回辔参相召,乘歌会使程。
今有千人醉,不然一子心。
今风泛云会,清日白衣新。注:演示模型只是生成单句诗,因此这些诗句的行与行之间并没有关联。
最后 #
本文的实验并不是为了生出多高质量的诗,而是做一个基于VAE的文本生成的演示。网上也有类似的作诗机器人了,不过多数流行的作诗机器人是基于“RNN + 语言模型”的思路的,一般需要一些种子词输入才可以完成作诗。而VAE能真正实现把随机数映射到诗句的过程~
转载到请包括本文地址:https://kexue.fm/archives/5332
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Mar. 24, 2018). 《基于CNN和VAE的作诗机器人:随机成诗 》[Blog post]. Retrieved from https://kexue.fm/archives/5332
@online{kexuefm-5332,
title={基于CNN和VAE的作诗机器人:随机成诗},
author={苏剑林},
year={2018},
month={Mar},
url={\url{https://kexue.fm/archives/5332}},
}

March 26th, 2018
楼主,我运行你的代码,报这样的错误,貌似是编码的问题,能麻烦看一眼吗
Traceback (most recent call last):
File "vae_shi.py", line 136, in
callbacks=[evaluator])
File "/anaconda2/lib/python2.7/site-packages/keras/engine/training.py", line 1705, in fit
validation_steps=validation_steps)
File "/anaconda2/lib/python2.7/site-packages/keras/engine/training.py", line 1255, in _fit_loop
callbacks.on_epoch_end(epoch, epoch_logs)
File "/anaconda2/lib/python2.7/site-packages/keras/callbacks.py", line 77, in on_epoch_end
callback.on_epoch_end(epoch, logs)
File "vae_shi.py", line 127, in on_epoch_end
print ' %s'%(self.log[-1])
UnicodeEncodeError: 'ascii' codec can't encode characters in position 10-20: ordinal not in range(128)
现在重新用最新的代码试试~
可以了,谢谢
March 26th, 2018
挺有意思的
April 11th, 2018
厉害了!
May 3rd, 2018
请问一下学习率是怎么设置的,输出例子的图中的损失下降很多,然而跑代码的时候,损失下降很少
代码都在这里https://github.com/bojone/vae/blob/master/vae_shi.py ,优化算法用的是adam,默认学习率是0.001
就是在跑代码的时候遇到了一个问题:Dense_4 missing from loss dictionary, 导致计算的导数没有回传,不知道您有没有遇到这个bug?另外还试了将损失的计算作为模型的一层,也无法解决。
我是在keras=2.1.0, python3的环境下跑的
不知道由于什么原因,在linux环境下跑这个代码的时候损失不下降,但是在mac上跑损失是正常下降的。
keras版本要用更新的,你不妨对比一下你这两个keras版本~
May 15th, 2018
您好,h = GCNN(residual=True)(input_vec) # GCNN层 这个代码出现了错误
number of input channels does not match corresponding dimension of filter, 10 != 64
请问是什么原因呢?
默认代码不会有问题,你自己改参数的话麻烦看懂再改~
没有改参数的,貌似是keras版本引起的问题。更新一下就好了。
October 26th, 2018
你好,我在python3,keras2.2.4,tf 1.11.0环境下,copy了你的代码来运行,会报错
File "", line 1, in
runfile('/Users/fayguo/Downloads/python/VEA_shi/vae_shi.py', wdir='/Users/fayguo/Downloads/python/VEA_shi')
File "/anaconda3/lib/python3.6/site-packages/spyder/utils/site/sitecustomize.py", line 705, in runfile
execfile(filename, namespace)
File "/anaconda3/lib/python3.6/site-packages/spyder/utils/site/sitecustomize.py", line 102, in execfile
exec(compile(f.read(), filename, 'exec'), namespace)
File "/Users/fayguo/Downloads/python/VEA_shi/vae_shi.py", line 136, in
callbacks=[evaluator])
File "/anaconda3/lib/python3.6/site-packages/keras/engine/training.py", line 952, in fit
batch_size=batch_size)
File "/anaconda3/lib/python3.6/site-packages/keras/engine/training.py", line 751, in _standardize_user_data
exception_prefix='input')
File "/anaconda3/lib/python3.6/site-packages/keras/engine/training_utils.py", line 138, in standardize_input_data
str(data_shape))
ValueError: Error when checking input: expected input_1 to have shape (10,) but got array with shape (1,)
请问是哪里出了问题?
请先在python2尝试,如果python2有问题请再联系。因为我不负责从python2到python3的debug。
January 9th, 2019
谕嗾肉苾薝,铛獝诼堌嘲
你好啊,我的机器人作出来的诗,为什么都是上面这种超级复杂的,怎么才能作出像你那样的。
完全执行我的代码,数据集和代码都一点没改动?
January 17th, 2019
您好,“而VAE能真正实现把随机数映射到诗句的过程~” 该如何理解? 能否做到诗句到随机数的过程?
encoder的作用就是相当于将诗句映射到一个随机向量了
January 22nd, 2019
楼主你好,我运行了你的代码 报了以下的错误,请问可能是什么原因呢
Traceback (most recent call last):
File "C:/Users/Administrator/PycharmProjects/dataset/vae-master/vae_shi.py", line 136, in
callbacks=[evaluator])
File "D:\python35\lib\site-packages\keras\engine\training.py", line 1039, in fit
validation_steps=validation_steps)
File "D:\python35\lib\site-packages\keras\engine\training_arrays.py", line 217, in fit_loop
callbacks.on_epoch_end(epoch, epoch_logs)
File "D:\python35\lib\site-packages\keras\callbacks.py", line 79, in on_epoch_end
callback.on_epoch_end(epoch, logs)
File "C:/Users/Administrator/PycharmProjects/dataset/vae-master/vae_shi.py", line 127, in on_epoch_end
print (u'%s'%(self.log[-1])).encode('utf-8')
AttributeError: 'NoneType' object has no attribute 'encode'
换python2,或者自己想办法。
February 28th, 2019
根据 conv1d 的文档:
This layer creates a convolution kernel that is convolved with the layer input over a single spatial (or temporal) dimension to produce a tensor of outputs.
conv1d执行的是时序卷积,在下一层的t时间步依赖的是前面一层的t时间步之前的信息。这对该问题有影响吗?我觉得在这个问题中跟时序好像没什么关系。
如果确定使用时序的卷积,那么padding应该设置为 causal
参考:
https://www.tensorflow.org/api_docs/python/tf/keras/layers/Conv1D
跟时序没本质关系,convd就是一个局部全连接。
而且本文这个诗句生成,因为诗句格式固定,所以可以直接看到一个简单的向量到文本的映射,不需要看成时序。