






22
Oct
CAN:借助先验分布提升分类性能的简单后处理技巧
By 苏剑林 | 2021-10-22 | 206425位读者 | 引用顾名思义,本文将会介绍一种用于分类问题的后处理技巧——CAN(Classification with Alternating Normalization),出自论文《When in Doubt: Improving Classification Performance with Alternating Normalization》。经过笔者的实测,CAN确实多数情况下能提升多分类问题的效果,而且几乎没有增加预测成本,因为它仅仅是对预测结果的简单重新归一化操作。
有趣的是,其实CAN的思想是非常朴素的,朴素到每个人在生活中都应该用过同样的思想。然而,CAN的论文却没有很好地说清楚这个思想,只是纯粹形式化地介绍和实验这个方法。本文的分享中,将会尽量将算法思想介绍清楚。
思想例子
假设有一个二分类问题,模型对于输入$a$给出的预测结果是$p^{(a)} = [0.05, 0.95]$,那么我们就可以给出预测类别为$1$;接下来,对于输入$b$,模型给出的预测结果是$p^{(b)}=[0.5,0.5]$,这时候处于最不确定的状态,我们也不知道输出哪个类别好。
10
Oct
用狄拉克函数来构造非光滑函数的光滑近似
By 苏剑林 | 2021-10-10 | 104354位读者 | 引用在机器学习中,我们经常会碰到不光滑的函数,但我们的优化方法通常是基于梯度的,这意味着光滑的模型可能更利于优化(梯度是连续的),所以就有了寻找非光滑函数的光滑近似的需求。事实上,本博客已经多次讨论过相关主题,比如《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等,但以往的讨论在方法上并没有什么通用性。
不过,笔者从最近的一篇论文《SAU: Smooth activation function using convolution with approximate identities》学习到了一种比较通用的思路:用狄拉克函数来构造光滑近似。通用到什么程度呢?理论上有可数个间断点的函数都可以用它来构造光滑近似!个人感觉还是非常有意思的。
24
Sep
让人惊叹的Johnson-Lindenstrauss引理:应用篇
By 苏剑林 | 2021-09-24 | 49998位读者 | 引用上一篇文章《让人惊叹的Johnson-Lindenstrauss引理:理论篇》中,我们比较详细地介绍了Johnson-Lindenstrauss引理(JL引理)的理论推导,这一篇我们来关注它的应用。
作为一个内容上本身就跟降维相关的结论,JL引理最基本的自然就是作为一个降维方法来用。但除了这个直接应用外,很多看似不相关的算法,比如局部敏感哈希(LSH)、随机SVD等,本质上也依赖于JL引理。此外,对于机器学习模型来说,JL引理通常还能为我们的维度选择提供一些理论解释。
降维的工具
JL引理提供了一个非常简单直接的“随机投影”降维思路:
给定$N$个向量$v_1,v_2,\cdots,v_N\in\mathbb{R}^m$,如果想要将它降到$n$维,那么只需要从$\mathcal{N}(0,1/n)$中采样一个$n\times m$矩阵$A$,然后$Av_1,Av_2,\cdots,Av_N$就是降维后的结果。
17
Sep
让人惊叹的Johnson-Lindenstrauss引理:理论篇
By 苏剑林 | 2021-09-17 | 124131位读者 | 引用今天我们来学习Johnson-Lindenstrauss引理,由于名字比较长,下面都简称“JL引理”。
个人认为,JL引理是每一个计算机科学的同学都必须了解的神奇结论之一,它是一个关于降维的著名的结果,它也是高维空间中众多反直觉的“维度灾难”现象的经典例子之一。可以说,JL引理是机器学习中各种降维、Hash等技术的理论基础,此外,在现代机器学习中,JL引理也为我们理解、调试模型维度等相关参数提供了重要的理论支撑。
对数的维度
JL引理,可以非常通俗地表达为:
通俗版JL引理: 塞下$N$个向量,只需要$\mathcal{O}(\log N)$维空间。
24
Aug
隐藏在动量中的梯度累积:少更新几步,效果反而更好?
By 苏剑林 | 2021-08-24 | 43604位读者 | 引用我们知道,梯度累积是在有限显存下实现大batch_size训练的常用技巧。在之前的文章《用时间换取效果:Keras梯度累积优化器》中,我们就简单介绍过梯度累积的实现,大致的思路是新增一组参数来缓存梯度,最后用缓存的梯度来更新模型。美中不足的是,新增一组参数会带来额外的显存占用。
这几天笔者在思考优化器的时候,突然意识到:梯度累积其实可以内置在带动量的优化器中!带着这个思路,笔者对优化了进行了一些推导和实验,最后还得到一个有意思但又有点反直觉的结论:少更新几步参数,模型最终效果可能会变好!
注:本文下面的结果,几乎原封不动且没有引用地出现在Google的论文《Combined Scaling for Zero-shot Transfer Learning》中,在此不做过多评价,请读者自行品评。
SGDM
在正式讨论之前,我们定义函数
\begin{equation}\chi_{t/k} = \left\{ \begin{aligned}&1,\quad t \equiv 0\,(\text{mod}\, k) \\
&0,\quad t \not\equiv 0\,(\text{mod}\, k)
\end{aligned}\right.\end{equation}
也就是说,$t$是一个整数,当它是$k$的倍数时,$\chi_{t/k}=1$,否则$\chi_{t/k}=0$,这其实就是一个$t$能否被$k$整除的示性函数。在后面的讨论中,我们将反复用到这个函数。
8
Mar
Transformer升级之路:1、Sinusoidal位置编码追根溯源
By 苏剑林 | 2021-03-08 | 253848位读者 | 引用最近笔者做了一些理解和改进Transformer的尝试,得到了一些似乎还有价值的经验和结论,遂开一个专题总结一下,命名为“Transformer升级之路”,既代表理解上的深入,也代表结果上的改进。
作为该专题的第一篇文章,笔者将会介绍自己对Google在《Attention is All You Need》中提出来的Sinusoidal位置编码
\begin{equation}\left\{\begin{aligned}&\boldsymbol{p}_{k,2i}=\sin\Big(k/10000^{2i/d}\Big)\\
&\boldsymbol{p}_{k, 2i+1}=\cos\Big(k/10000^{2i/d}\Big)
\end{aligned}\right.\label{eq:sin}\end{equation}
的新理解,其中$\boldsymbol{p}_{k,2i},\boldsymbol{p}_{k,2i+1}$分别是位置$k$的编码向量的第$2i,2i+1$个分量,$d$是向量维度。
作为位置编码的一个显式解,Google在原论文中对它的描述却寥寥无几,只是简单提及了它可以表达相对位置信息,后来知乎等平台上也出现了一些解读,它的一些特点也逐步为大家所知,但总体而言比较零散。特别是对于“它是怎么想出来的”、“非得要这个形式不可吗”等原理性问题,还没有比较好的答案。
因此,本文主要围绕这些问题展开思考,可能在思考过程中读者会有跟笔者一样的感觉,即越思考越觉得这个设计之精妙漂亮,让人叹服~
24
Nov
exp(x)在x=0处的偶次泰勒展开式总是正的
By 苏剑林 | 2020-11-24 | 47218位读者 | 引用刚看到一个有意思的结论:
对于任意实数$x$及偶数$n$,总有$\sum\limits_{k=0}^n \frac{x^k}{k!} > 0$,即$e^x$在$x=0$处的偶次泰勒展开式总是正的。
下面我们来看一下这个结论的证明,以及它在寻找softmax替代品中的应用。
证明过程
看上去这是一个很强的结果,证明会不会很复杂?其实证明非常简单,记
\begin{equation}f_n(x) = \sum\limits_{k=0}^n \frac{x^k}{k!}\end{equation}
当$n$是偶数时,我们有$\lim\limits_{x\to\pm\infty} f_n(x)=+\infty$,即整体是开口向上的,所以我们只需要证明它的最小值大于0就行了,又因为它是一个光滑连续的多项式函数,所以最小值点必然是某个极小值点。那么换个角度想,我们只需要证明它所有的极值点(不管是极大还是极小)所对应的函数值都大于0。
26
Mar
GELU的两个初等函数近似是怎么来的
By 苏剑林 | 2020-03-26 | 80813位读者 | 引用GELU,全称为Gaussian Error Linear Unit,也算是RELU的变种,是一个非初等函数形式的激活函数。它由论文《Gaussian Error Linear Units (GELUs)》提出,后来被用到了GPT中,再后来被用在了BERT中,再再后来的不少预训练语言模型也跟着用到了它。随着BERT等预训练语言模型的兴起,GELU也跟着水涨船高,莫名其妙地就成了热门的激活函数了。
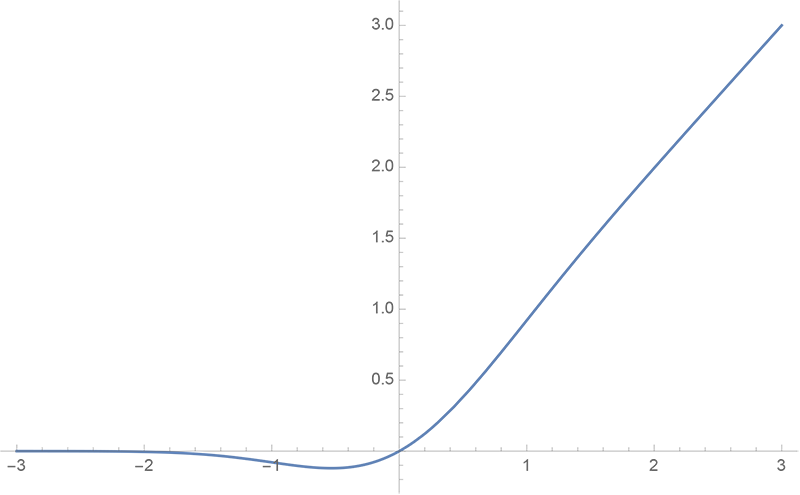
gelu函数图像
在GELU的原始论文中,作者不仅提出了GELU的精确形式,还给出了两个初等函数的近似形式,本文来讨论它们是怎么得到的。

最近评论