






10
Dec
Muon优化器赏析:从向量到矩阵的本质跨越
By 苏剑林 | 2024-12-10 | 28302位读者 | 引用随着LLM时代的到来,学术界对于优化器的研究热情似乎有所减退。这主要是因为目前主流的AdamW已经能够满足大多数需求,而如果对优化器“大动干戈”,那么需要巨大的验证成本。因此,当前优化器的变化,多数都只是工业界根据自己的训练经验来对AdamW打的一些小补丁。
不过,最近推特上一个名为“Muon”的优化器颇为热闹,它声称比AdamW更为高效,且并不只是在Adam基础上的“小打小闹”,而是体现了关于向量与矩阵差异的一些值得深思的原理。本文让我们一起赏析一番。
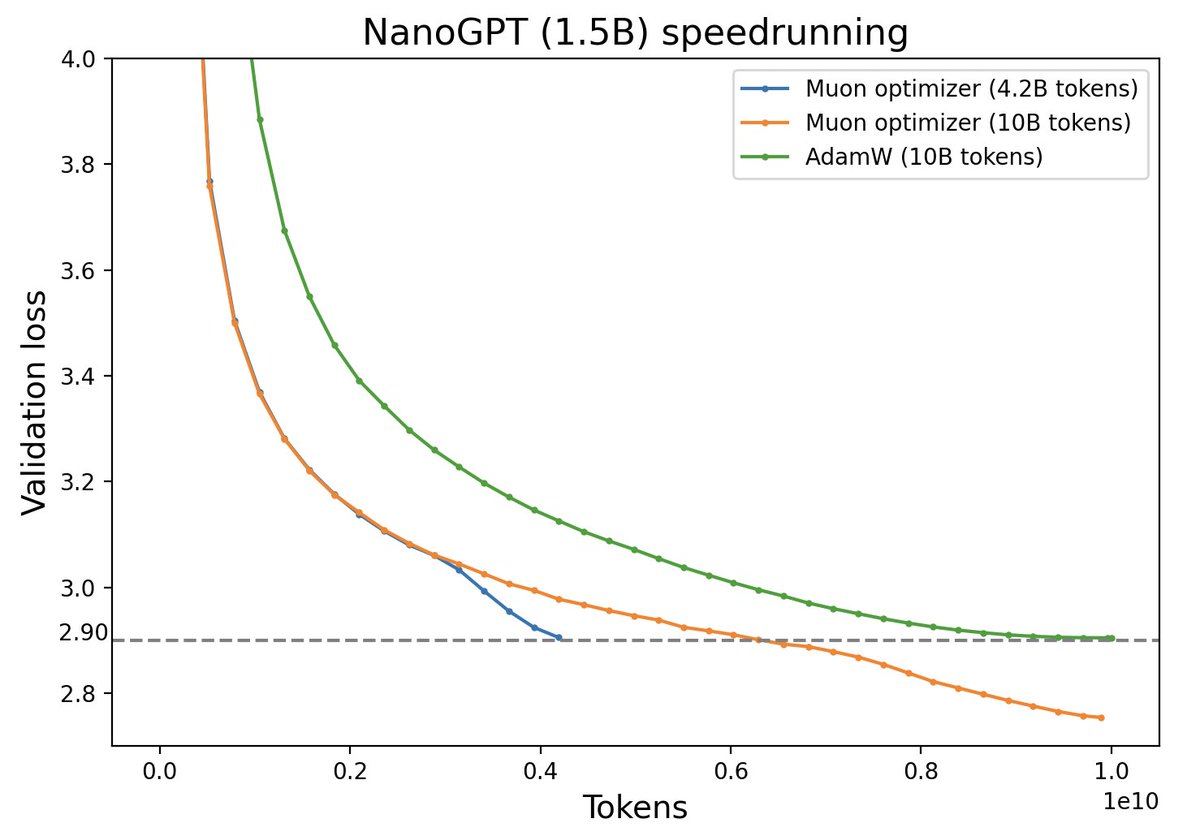
Muon与AdamW效果对比(来源:推特@Yuchenj_UW)
15
Dec
生成扩散模型漫谈(二十七):将步长作为条件输入
By 苏剑林 | 2024-12-15 | 23781位读者 | 引用这篇文章我们再次聚焦于扩散模型的采样加速。众所周知,扩散模型的采样加速主要有两种思路,一是开发更高效的求解器,二是事后蒸馏。然而,据笔者观察,除了上两篇文章介绍过的SiD外,这两种方案都鲜有能将生成步数降低到一步的结果。虽然SiD能做到单步生成,但它需要额外的蒸馏成本,并且蒸馏过程中用到了类似GAN的交替训练过程,总让人感觉差点意思。
本文要介绍的是《One Step Diffusion via Shortcut Models》,其突破性思想是将生成步长也作为扩散模型的条件输入,然后往训练目标中加入了一个直观的正则项,这样就能直接稳定训练出可以单步生成模型,可谓简单有效的经典之作。
ODE扩散
原论文的结论是基于ODE式扩散模型的,而对于ODE式扩散的理论基础,我们在本系列的(六)、(十二)、(十四)、(十五)、(十七)等博客中已经多次介绍,其中最简单的一种理解方式大概是(十七)中的ReFlow视角,下面我们简单重复一下。
28
Jan
三个球的交点坐标(三球交会定位)
By 苏剑林 | 2025-01-28 | 10162位读者 | 引用前几天笔者在思考一个问题时,联想到了三球交点问题,即给定三个球的球心坐标和半径,求这三个球的交点坐标。按理说这是一个定义清晰且简明的问题,并且具有鲜明的应用背景(比如卫星定位),应该早已有人给出“标准答案”才对。但笔者搜了一圈,发现不管是英文资料还是中文资料,都没有找到标准的求解流程。
当然,这并不是说这个问题有多难以至于没人能求解出来,事实上这是个早已被人解决的经典问题,笔者只是意外于似乎没有人以一种可读性比较好的方式将求解过程写到网上,所以本文试图补充这一点。
特殊情形
首先,设三个球的方程分别是
\begin{align}
&\text{球1:}\quad (\boldsymbol{x} - \boldsymbol{o}_1)^2 = r_1^2 \label{eq:s1} \\
&\text{球2:}\quad (\boldsymbol{x} - \boldsymbol{o}_2)^2 = r_2^2 \label{eq:s2} \\
&\text{球3:}\quad (\boldsymbol{x} - \boldsymbol{o}_3)^2 = r_3^2 \label{eq:s3} \\
\end{align}
18
Dec
生成扩散模型漫谈(二十八):分步理解一致性模型
By 苏剑林 | 2024-12-18 | 23537位读者 | 引用书接上文,在《生成扩散模型漫谈(二十七):将步长作为条件输入》中,我们介绍了加速采样的Shortcut模型,其对比的模型之一就是“一致性模型(Consistency Models)”。事实上,早在《生成扩散模型漫谈(十七):构建ODE的一般步骤(下)》介绍ReFlow时,就有读者提到了一致性模型,但笔者总感觉它更像是实践上的Trick,理论方面略显单薄,所以兴趣寥寥。
不过,既然我们开始关注扩散模型加速采样方面的进展,那么一致性模型就是一个绕不开的工作。因此,趁着这个机会,笔者在这里分享一下自己对一致性模型的理解。
熟悉配方
还是熟悉的配方,我们的出发点依旧是ReFlow,因为它大概是ODE式扩散最简单的理解方式。设$\boldsymbol{x}_0\sim p_0(\boldsymbol{x}_0)$是目标分布的真实样本,$\boldsymbol{x}_1\sim p_1(\boldsymbol{x}_1)$是先验分布的随机噪声,$\boldsymbol{x}_t = (1-t)\boldsymbol{x}_0 + t\boldsymbol{x}_1$是加噪样本,那么ReFlow的训练目标是:
25
Dec
从谱范数梯度到新式权重衰减的思考
By 苏剑林 | 2024-12-25 | 18209位读者 | 引用在文章《Muon优化器赏析:从向量到矩阵的本质跨越》中,我们介绍了一个名为“Muon”的新优化器,其中一个理解视角是作为谱范数正则下的最速梯度下降,这似乎揭示了矩阵参数的更本质的优化方向。众所周知,对于矩阵参数我们经常也会加权重衰减(Weight Decay),它可以理解为$F$范数平方的梯度,那么从Muon的视角看,通过谱范数平方的梯度来构建新的权重衰减,会不会能起到更好的效果呢?
那么问题来了,谱范数的梯度或者说导数长啥样呢?用它来设计的新权重衰减又是什么样的?接下来我们围绕这些问题展开。
基础回顾
谱范数(Spectral Norm),又称“$2$范数”,是最常用的矩阵范数之一,相比更简单的$F$范数(Frobenius Norm),它往往能揭示一些与矩阵乘法相关的更本质的信号,这是因为它定义上就跟矩阵乘法相关:对于矩阵参数$\boldsymbol{W}\in\mathbb{R}^{n\times m}$,它的谱范数定义为
8
Feb
MoE环游记:1、从几何意义出发
By 苏剑林 | 2025-02-08 | 26467位读者 | 引用前两年福至心灵之下,开了一个“Transformer升级之路”系列,陆续分享了主流Transformer架构的一些改进工作和个人思考,得到了部份读者的认可。这篇文章开始,我们沿着同样的风格,介绍当前另一个主流架构MoE(Mixture of Experts)。
MoE的流行自不必多说,近来火出圈的DeepSeek-V3便是MoE架构,传言GPT-4也是MoE架构,国内最近出的一些模型也有不少用上了MoE。然而,虽然MoE的研究由来已久,但其应用长时间内都不愠不火,大致上是从去年初的《Mixtral of Experts》开始,MoE才逐渐吸引大家的注意力,其显著优点是参数量大,但训练和推理成本都显著低。
但同时MoE也有一些难题,如训练不稳定、负载不均衡、效果不够好等,这也是它早年没有流行起来的主要原因。不过随着这两年关注度的提升,这些问题在很大程度上已经得到解决,我们在接下来的介绍中会逐一谈到这些内容。
21
Feb
MoE环游记:2、不患寡而患不均
By 苏剑林 | 2025-02-21 | 7831位读者 | 引用在上一篇文章《MoE环游记:1、从几何意义出发》中,我们介绍了MoE的一个几何诠释,旨在通过Dense模型的最佳逼近出发来推导和理解MoE。同时在文末我们也说了,给出MoE的计算公式仅仅是开始,训练一个实际有效的MoE模型还有很多细节补,比如本文要讨论的负载均衡(Load Balance)问题。
负载均衡,即“不患寡而患不均”,说白了就是让每个Expert都在干活,并且都在干尽可能一样多的活,避免某些Expert浪费算力。负载均衡既是充分利用训练算力的需求,也是尽可能发挥MoE大参数量潜力的需求。
需求分析
我们知道,MoE的基本形式是
\begin{equation}\boldsymbol{y} = \sum_{i\in \mathop{\text{argtop}}_k \boldsymbol{\rho}} \rho_i \boldsymbol{e}_i\end{equation}
27
Feb
Muon续集:为什么我们选择尝试Muon?
By 苏剑林 | 2025-02-27 | 3705位读者 | 引用本文解读一下我们最新的技术报告《Muon is Scalable for LLM Training》,里边分享了我们之前在《Muon优化器赏析:从向量到矩阵的本质跨越》介绍过的Muon优化器的一次较大规模的实践,并开源了相应的模型(我们称之为“Moonlight”,目前是一个3B/16B的MoE模型)。我们发现了一个比较惊人的结论:在我们的实验设置下,Muon相比Adam能够达到将近2倍的训练效率。

Muon的Scaling Law及Moonlight的MMLU表现
优化器的工作说多不多,但说少也不少,为什么我们会选择Muon来作为新的尝试方向呢?已经调好超参的Adam优化器,怎么快速切换到Muon上进行尝试呢?模型Scale上去之后,Muon与Adam的性能效果差异如何?接下来将分享我们的思考过程。

最近评论