






1
May
GlobalPointer:用统一的方式处理嵌套和非嵌套NER
By 苏剑林 | 2021-05-01 | 354482位读者 | 引用(注:本文的相关内容已整理成论文《Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition》,如需引用可以直接引用英文论文,谢谢。)
本文将介绍一个称为GlobalPointer的设计,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是$\mathcal{O}(1)$!
简单来说,就是更漂亮、更快速、更强大!真有那么好的设计吗?不妨继续看看。
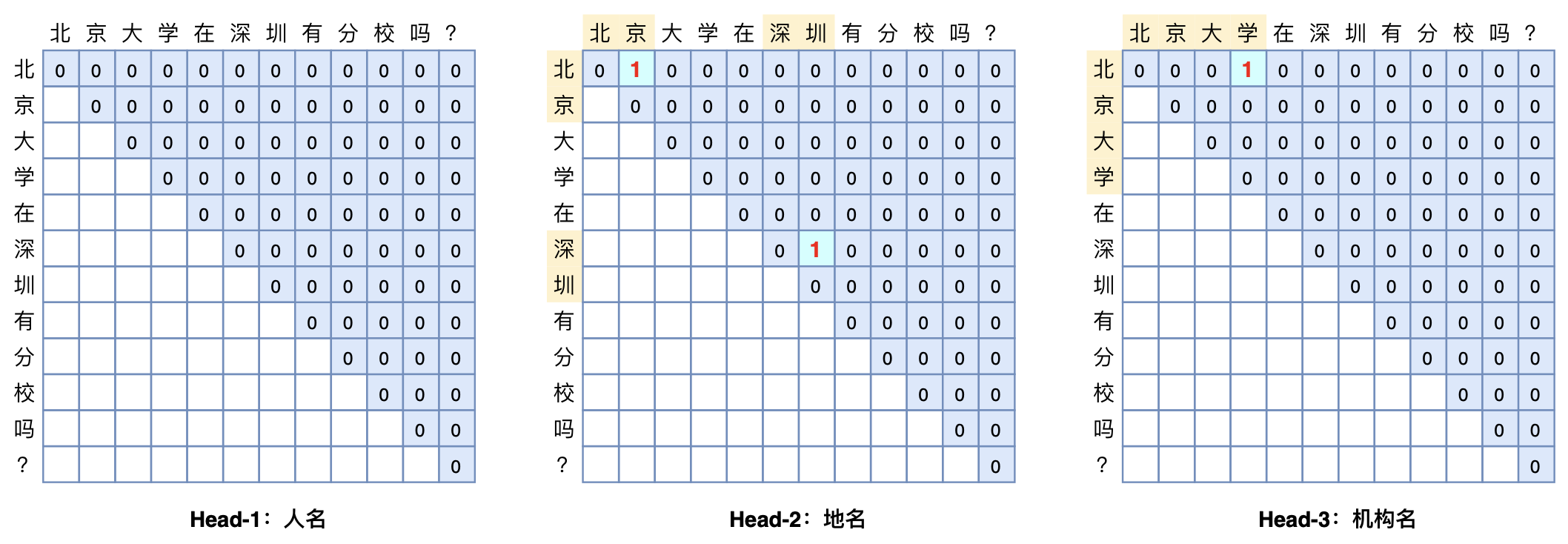
GlobalPointer多头识别嵌套实体示意图
25
Jan
Efficient GlobalPointer:少点参数,多点效果
By 苏剑林 | 2022-01-25 | 138374位读者 | 引用在《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》中,我们提出了名为“GlobalPointer”的token-pair识别模块,当它用于NER时,能统一处理嵌套和非嵌套任务,并在非嵌套场景有着比CRF更快的速度和不逊色于CRF的效果。换言之,就目前的实验结果来看,至少在NER场景,我们可以放心地将CRF替换为GlobalPointer,而不用担心效果和速度上的损失。
在这篇文章中,我们提出GlobalPointer的一个改进版——Efficient GlobalPointer,它主要针对原GlobalPointer参数利用率不高的问题进行改进,明显降低了GlobalPointer的参数量。更有趣的是,多个任务的实验结果显示,参数量更少的Efficient GlobalPointer反而还取得更好的效果。
大量的参数
这里简单回顾一下GlobalPointer,详细介绍则请读者阅读《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》。简单来说,GlobalPointer是基于内积的token-pair识别模块,它可以用于NER场景,因为对于NER来说我们只需要把每一类实体的“(首, 尾)”这样的token-pair识别出来就行了。
30
Jan
GPLinker:基于GlobalPointer的实体关系联合抽取
By 苏剑林 | 2022-01-30 | 133117位读者 | 引用在将近三年前的百度“2019语言与智能技术竞赛”(下称LIC2019)中,笔者提出了一个新的关系抽取模型(参考《基于DGCNN和概率图的轻量级信息抽取模型》),后被进一步发表和命名为“CasRel”,算是当时关系抽取的SOTA。然而,CasRel提出时笔者其实也是首次接触该领域,所以现在看来CasRel仍有诸多不完善之处,笔者后面也有想过要进一步完善它,但也没想到特别好的设计。
后来,笔者提出了GlobalPointer以及近日的Efficient GlobalPointer,感觉有足够的“材料”来构建新的关系抽取模型了。于是笔者从概率图思想出发,参考了CasRel之后的一些SOTA设计,最终得到了一版类似TPLinker的模型。
基础思路
关系抽取乍看之下是三元组$(s,p,o)$(即subject, predicate, object)的抽取,但落到具体实现上,它实际是“五元组”$(s_h,s_t,p,o_h,o_t)$的抽取,其中$s_h,s_t$分别是$s$的首、尾位置,而$o_h,o_t$则分别是$o$的首、尾位置。
21
Feb
GPLinker:基于GlobalPointer的事件联合抽取
By 苏剑林 | 2022-02-21 | 86184位读者 | 引用大约两年前,笔者在百度的“2020语言与智能技术竞赛”中首次接触到了事件抽取任务,并在文章《bert4keras在手,baseline我有:百度LIC2020》中分享了一个转化为BERT+CRF做NER的简单baseline。不过,当时的baseline更像是一个用来凑数的半成品,算不上一个完整的事件抽取模型。而这两年来,关系抽取的模型层见迭出,SOTA一个接一个,但事件抽取似乎没有多亮眼的设计。
最近笔者重新尝试了事件抽取任务,在之前的关系抽取模型GPLinker的基础上,结合完全子图搜索,设计一个比较简单但相对完备的事件联合抽取模型,依然称之为GPLinker,在此请大家点评一番。
任务简介
事件抽取是一个比较综合的任务。一个标准的事件抽取样本如下:
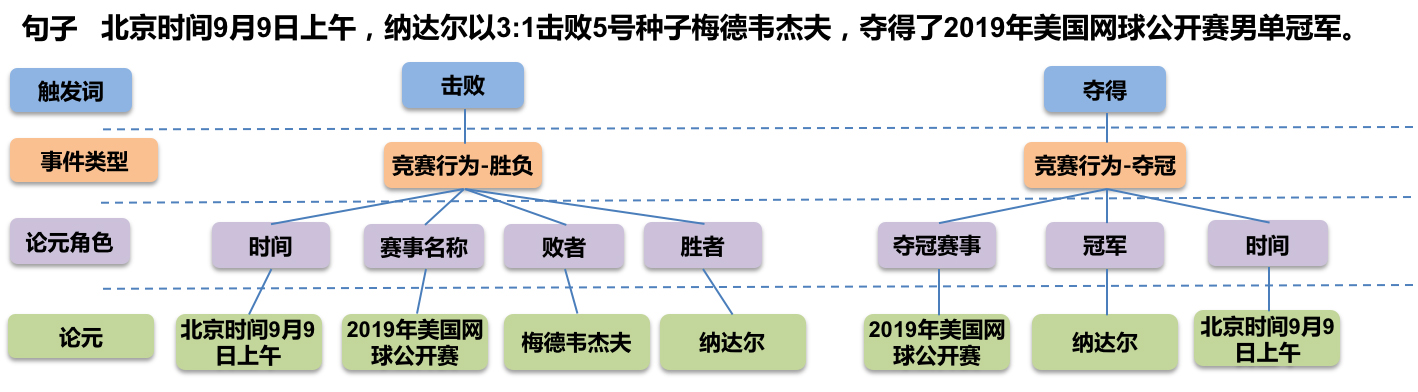
标准的事件抽取样本(图片来自百度DuEE的GitHub)
15
Apr
GlobalPointer下的“KL散度”应该是怎样的?
By 苏剑林 | 2022-04-15 | 29314位读者 | 引用最近有读者提到想测试一下GlobalPointer与R-Drop结合的效果,但不知道GlobalPointer下的KL散度该怎么算。像R-Drop或者虚拟对抗训练这些正则化手段,里边都需要算概率分布的KL散度,但GlobalPointer的预测结果并非一个概率分布,因此无法直接进行计算。
经过一番尝试,笔者给出了一个可用的形式,并通过简单实验验证了它的可行性,遂在此介绍笔者的分析过程。
对称散度
KL散度是关于两个概率分布的函数,它是不对称的,即$KL(p\Vert q)$通常不等于$KL(q\Vert p)$,在实际应用中,我们通常使用对称化的KL散度:
\begin{equation}D(p,q) = KL(p\Vert q) + KL(q\Vert p)\end{equation}
31
Oct
bert4keras在手,baseline我有:CLUE基准代码
By 苏剑林 | 2021-10-31 | 86869位读者 | 引用CLUE(Chinese GLUE)是中文自然语言处理的一个评价基准,目前也已经得到了较多团队的认可。CLUE官方Github提供了tensorflow和pytorch的baseline,但并不易读,而且也不方便调试。事实上,不管是tensorflow还是pytorch,不管是CLUE还是GLUE,笔者认为能找到的baseline代码,都很难称得上人性化,试图去理解它们是一件相当痛苦的事情。
所以,笔者决定基于bert4keras实现一套CLUE的baseline。经过一段时间的测试,基本上复现了官方宣称的基准成绩,并且有些任务还更优。最重要的是,所有代码尽量保持了清晰易读的特点,真·“Deep Learning for Humans”。
代码简介
下面简单介绍一下该代码中各个任务baseline的构建思路。在阅读文章和代码之前,请读者自行先观察一下每个任务的数据格式,这里不对任务数据进行详细介绍。
7
May
多标签“Softmax+交叉熵”的软标签版本
By 苏剑林 | 2022-05-07 | 56702位读者 | 引用(注:本文的相关内容已整理成论文《ZLPR: A Novel Loss for Multi-label Classification》,如需引用可以直接引用英文论文,谢谢。)
在《将“Softmax+交叉熵”推广到多标签分类问题》中,我们提出了一个用于多标签分类的损失函数:
\begin{equation}\log \left(1 + \sum\limits_{i\in\Omega_{neg}} e^{s_i}\right) + \log \left(1 + \sum\limits_{j\in\Omega_{pos}} e^{-s_j}\right)\label{eq:original}\end{equation}
这个损失函数有着单标签分类中“Softmax+交叉熵”的优点,即便在正负类不平衡的依然能够有效工作。但从这个损失函数的形式我们可以看到,它只适用于“硬标签”,这就意味着label smoothing、mixup等技巧就没法用了。本文则尝试解决这个问题,提出上述损失函数的一个软标签版本。
巧妙联系
多标签分类的经典方案就是转化为多个二分类问题,即每个类别用sigmoid函数$\sigma(x)=1/(1+e^{-x})$激活,然后各自用二分类交叉熵损失。当正负类别极其不平衡时,这种做法的表现通常会比较糟糕,而相比之下损失$\eqref{eq:original}$通常是一个更优的选择。

最近评论