






9
Aug
素数之美2:Bertrand假设的证明
By 苏剑林 | 2014-08-09 | 22895位读者 | 引用有了上一篇文章的$\prod\limits_{p\leq n}p < 4^{n-1}$的基础,我们其实已经很接近Bertrand假设的证明了。Bertrand假设的证明基于对二项式系数$C_n^{2n}$的素因子次数的细致考察,而在本篇文章中,我们先得到一个关于素数之积的下限公式,然后由此证明一个比Bertrand假设稍微弱一点的假设。最后,则通过一个简单的技巧,将我们的证明推动至Bertrand假设。
二项式系数的素因子
首先,我们考察$n!$中的素因子$p$的次数,结果是被称为Legendre定理的公式:
$n$中素因子$p$的次数恰好为$\sum\limits_{k\geq 1}\left\lfloor\frac{n}{p^k}\right\rfloor$。
证明很简单,因为$n!=1\times 2\times 3\times 4\times \dots \times n$,每隔$p$就有一个$p$的倍数,每隔$p^2$就有一个$p^2$的倍数,每隔$p^3$就有一个$p^3$的倍数,每增加一次幂,将多贡献一个$p$因子,所以把每个间隔数叠加即可。注意该和虽然写成无穷形式,但是非零项是有限的。
2
Jul
用Pandas实现高效的Apriori算法
By 苏剑林 | 2015-07-02 | 142183位读者 | 引用最近在做数据挖掘相关的工作,阅读到了Apriori算法。平时由于没有涉及到相关领域,因此对Apriori算法并不了解,而如今工作上遇到了,就不得不认真学习一下了。Apriori算法是一个寻找关联规则的算法,也就是从一大批数据中找到可能的逻辑,比如“条件A+条件B”很有可能推出“条件C”(A+B-->C),这就是一个关联规则。具体来讲,比如客户买了A商品后,往往会买B商品(反之,买了B商品不一定会买A商品),或者更复杂的,买了A、B两种商品的客户,很有可能会再买C商品(反之也不一定)。有了这些信息,我们就可以把一些商品组合销售,以获得更高的收益。而寻求关联规则的算法,就是关联分析算法。
啤酒与尿布

啤酒与尿布
关联算法的案例中,最为人老生常谈的应该是“啤酒与尿布”了。“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,超市管理人员发现“啤酒与尿布两件看上去毫无关系的商品会经常出现在同一个购物篮中”。经过分析,原来在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。因此,沃尔玛尝试将啤酒与尿布摆放在相同的区域,让年轻的父亲可以同时找到这两件商品。事实是效果相当不错!
9
Jul
植物拯救了地球,阻止寒冷灭绝之灾!
By 苏剑林 | 2009-07-09 | 21977位读者 | 引用
14
Jul
澳洲恐龙洞穴揭示气候变化
By 苏剑林 | 2009-07-14 | 26789位读者 | 引用
26
Nov
《环球科学》:超越费曼图
By 苏剑林 | 2012-11-26 | 19607位读者 | 引用虽然文章的大部分内容我都还无法弄懂,但是这里边讲述的振奋人心的内容让我决定把它转载过来。文章说,将大自然的各种力统一起来,或许没有物理学家原来所想的那么困难。
撰文∕ 伯尔尼(Zvi Bern)、狄克森(Lance J. Dixon)寇索尔(David A. Kosower)
翻译∕ 高涌泉(台湾大学物理系教授)
提供/ 科学人(Scientific American繁体中文版)
重点提要
物理学家对于粒子碰撞的了解,最近经历了一场宁静革命。知名物理学家费曼所引入的观念对于很多应用而言已到达极限。作者与合作者已经发展出新的方法。
物理学家利用新方法,可以更可靠地描述在大强子对撞机(LHC)那种极端条件下普通粒子的行为,这将帮助实验学家寻找新粒子与新作用力。
新方法还有更为深刻的应用:它让一种于1980年代被物理学家放弃的统一理论有了新生命,重力看起来像是双份的强核力一起作用。
春天某个晴朗的日子,本文作者狄克森从英国伦敦地铁的茂恩都站进入地铁,想前往希斯洛机场。伦敦地铁每天有300万名乘客,他瞧着其中一位陌生人,无聊地想着:这位老兄会从温布尔登站离开地铁的机率有多大?由于此人可能搭上任何一条地铁路线,所以该如何推算这个机率呢?他想了一会,领悟到这个问题其实跟粒子物理学家所面对的麻烦很像,那就是该如何预测现代高能实验中粒子碰撞的后果。
欧洲核子研究组织(CERN)的大强子对撞机(LHC)是这个时代最重要的探索实验;它让质子以近乎光速前进并相撞,然后研究碰撞后的碎片。我们知道建造对撞机及侦测器得用上最尖端的技术,然而较不为人知的是,解释侦测器的发现同样也是极为困难的挑战。乍看之下,它不应该那么困难才对,因为基本粒子的标准模型早已确立,理论学家也一直用此模型来预测实验的结果,而且理论预测所依赖的是著名物理学家费曼(Richard P. Feynman)早在60多年前就发展出来的计算技巧,每位粒子物理学家在研究生阶段都学过费曼的技巧;关于粒子物理的每本科普书、每篇科普文章,也都借用了费曼的概念。
10
Jun
无监督分词和句法分析!原来BERT还可以这样用
By 苏剑林 | 2020-06-10 | 84277位读者 | 引用BERT的一般用法就是加载其预训练权重,再接一小部分新层,然后在下游任务上进行finetune,换句话说一般的用法都是有监督训练的。基于这个流程,我们可以做中文的分词、NER甚至句法分析,这些想必大家就算没做过也会有所听闻。但如果说直接从预训练的BERT(不finetune)就可以对句子进行分词,甚至析出其句法结构出来,那应该会让人感觉到意外和有趣了。
本文介绍ACL 2020的论文《Perturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT》,里边提供了直接利用Masked Language Model(MLM)来分析和解释BERT的思路,而利用这种思路,我们可以无监督地做到分词甚至句法分析。
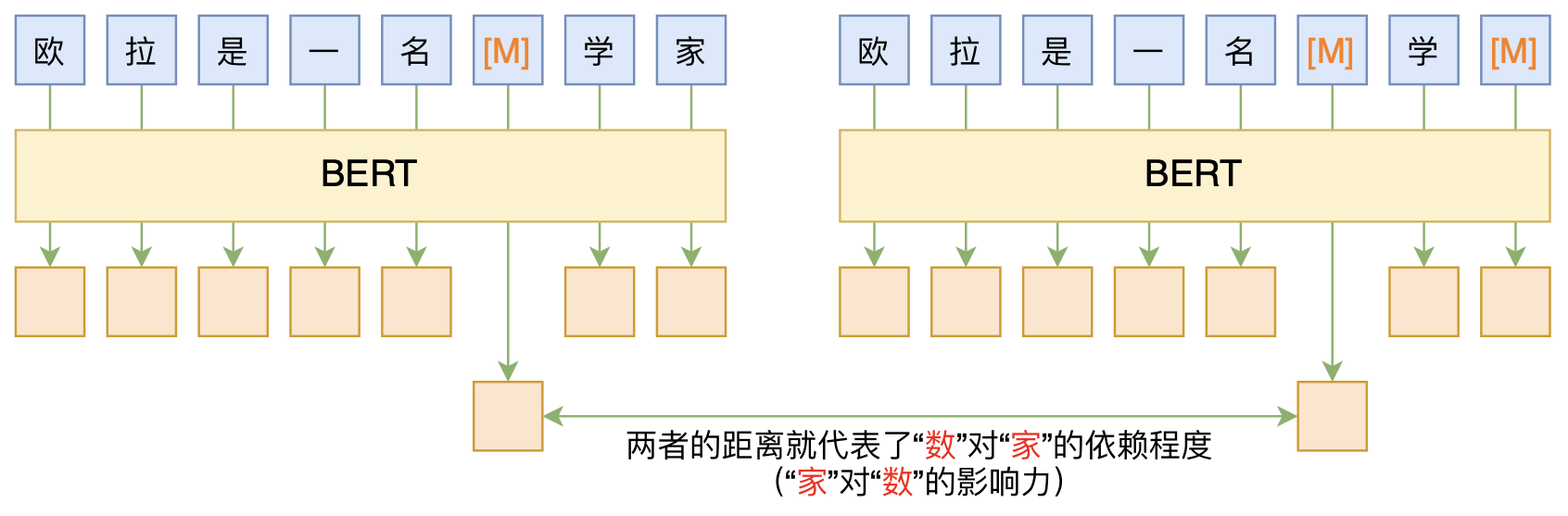
基于BERT的“token-token”相关度计算图示
10
Jul
强大的NVAE:以后再也不能说VAE生成的图像模糊了
By 苏剑林 | 2020-07-10 | 108473位读者 | 引用昨天早上,笔者在日常刷arixv的时候,然后被一篇新出来的论文震惊了!论文名字叫做《NVAE: A Deep Hierarchical Variational Autoencoder》,顾名思义是做VAE的改进工作的,提出了一个叫NVAE的新模型。说实话,笔者点进去的时候是不抱什么希望的,因为笔者也算是对VAE有一定的了解,觉得VAE在生成模型方面的能力终究是有限的。结果,论文打开了,呈现出来的画风是这样的:

NVAE的人脸生成效果
然后笔者的第一感觉是这样的:
W!T!F! 这真的是VAE生成的效果?这还是我认识的VAE么?看来我对VAE的认识还是太肤浅了啊,以后再也不能说VAE生成的图像模糊了...
22
Nov
ChildTuning:试试把Dropout加到梯度上去?
By 苏剑林 | 2021-11-22 | 65330位读者 | 引用Dropout是经典的防止过拟合的思路了,想必很多读者已经了解过它。有意思的是,最近Dropout有点“老树发新芽”的感觉,出现了一些有趣的新玩法,比如最近引起过热议的SimCSE和R-Drop,尤其是在文章《又是Dropout两次!这次它做到了有监督任务的SOTA》中,我们发现简单的R-Drop甚至能媲美对抗训练,不得不说让人意外。
一般来说,Dropout是被加在每一层的输出中,或者是加在模型参数上,这是Dropout的两个经典用法。不过,最近笔者从论文《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》中学到了一种新颖的用法:加到梯度上面。
梯度加上Dropout?相信大部分读者都是没听说过的。那么效果究竟如何呢?让我们来详细看看。

最近评论