






27
Jan
“让Keras更酷一些!”:随意的输出和灵活的归一化
By 苏剑林 | 2019-01-27 | 107650位读者 | 引用继续“让Keras更酷一些!”系列,让Keras来得更有趣些吧~
这次围绕着Keras的loss、metric、权重和进度条进行展开。
可以不要输出
一般我们用Keras定义一个模型,是这样子的:
x_in = Input(shape=(784,))
x = x_in
x = Dense(100, activation='relu')(x)
x = Dense(10, activation='softmax')(x)
model = Model(x_in, x)
model.compile(loss='categorical_crossentropy ',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
20
Jan
从Wasserstein距离、对偶理论到WGAN
By 苏剑林 | 2019-01-20 | 226654位读者 | 引用
推土机哪家强?成本最低找Wasserstein
2017年的时候笔者曾写过博文《互怼的艺术:从零直达WGAN-GP》,从一个相对通俗的角度来介绍了WGAN,在那篇文章中,WGAN更像是一个天马行空的结果,而实际上跟Wasserstein距离没有多大关系。
在本篇文章中,我们再从更数学化的视角来讨论一下WGAN。当然,本文并不是纯粹地讨论GAN,而主要侧重于Wasserstein距离及其对偶理论的理解。本文受启发于著名的国外博文《Wasserstein GAN and the Kantorovich-Rubinstein Duality》,内容跟它大体上相同,但是删除了一些冗余的部分,对不够充分或者含糊不清的地方作了补充。不管怎样,在此先对前辈及前辈的文章表示致敬。
(注:完整理解本文,应该需要多元微积分、概率论以及线性代数等基础知识。还有,本文确实长,数学公式确实多,但是,真的不复杂、不难懂,大家不要看到公式就吓怕了~)
6
Mar
O-GAN:简单修改,让GAN的判别器变成一个编码器!
By 苏剑林 | 2019-03-06 | 265585位读者 | 引用本文来给大家分享一下笔者最近的一个工作:通过简单地修改原来的GAN模型,就可以让判别器变成一个编码器,从而让GAN同时具备生成能力和编码能力,并且几乎不会增加训练成本。这个新模型被称为O-GAN(正交GAN,即Orthogonal Generative Adversarial Network),因为它是基于对判别器的正交分解操作来完成的,是对判别器自由度的最充分利用。

FFHQ线性插值效果图
18
Feb
恒等式 det(exp(A)) = exp(Tr(A)) 赏析
By 苏剑林 | 2019-02-18 | 71113位读者 | 引用本文的主题是一个有趣的矩阵行列式的恒等式
\begin{equation}\det(\exp(\boldsymbol{A})) = \exp(\text{Tr}(\boldsymbol{A}))\label{eq:main}\end{equation}
这个恒等式在挺多数学和物理的计算中都出现过,笔者都在不同的文献中看到过好几次了。
注意左端是矩阵的指数,然后求行列式,这两步都是计算量非常大的运算;右端仅仅是矩阵的迹(一个标量),然后再做标量的指数。两边的计算量差了不知道多少倍,然而它们居然是相等的!这不得不说是一个神奇的事实。
所以,本文就来好好欣赏一个这个恒等式。
26
Mar
科学空间浏览指南(FAQ)
By 苏剑林 | 2019-03-26 | 138901位读者 | 引用事实上,除了写博客内容,在这几年里,笔者是花了相当一部分时间来做科学空间的“表面功夫”,为此还专门学了一点php、css和js。虽然不敢说精益求精,但总体来说网站的浏览体验应该比前几年要好得多。
考虑到有些读者可能需要的功能,但一时半会未必能留意到,遂来整理一些站内技巧。
文章篇
什么环境阅读文章最佳?
两年前科学空间就已经加入了响应式设计,自动适应不同分辨率的屏幕。因此,不管哪个分辨率的环境应该都能看清文字内容,唯一的问题是,在小屏幕手机下公式可能会显示不全或者错位。为了较好地阅读公式,最好在7寸以上的屏幕上阅读。如果一定要用小屏幕的手机,可以考虑横屏阅读。
21
Mar
细水长flow之可逆ResNet:极致的暴力美学
By 苏剑林 | 2019-03-21 | 120712位读者 | 引用今天我们来介绍一个非常“暴力”的模型:可逆ResNet。
为什么一个模型可以可以用“暴力”来形容呢?当然是因为它确实非常暴力:它综合了很多数学技巧,活生生地(在一定约束下)把常规的ResNet模型搞成了可逆的!
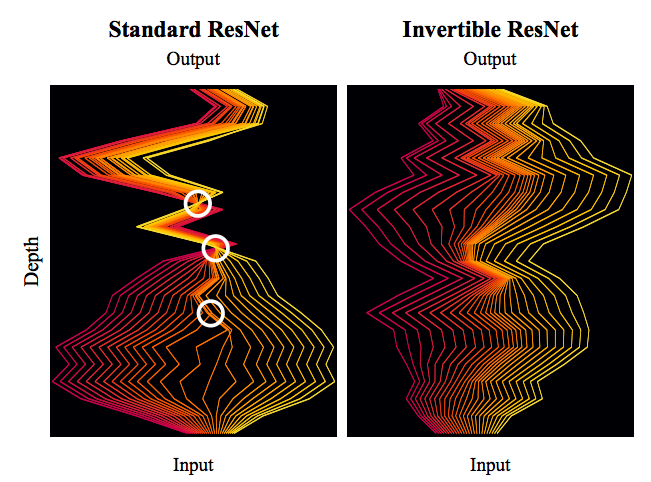
标准ResNet与可逆ResNet对比图。可逆ResNet允许信息无损可逆流动,而标准ResNet在某处则存在“坍缩”现象。
模型出自《Invertible Residual Networks》,之前在机器之心也报导过。在这篇文章中,我们来简单欣赏一下它的原理和内容。
可逆模型的点滴
为什么要研究可逆ResNet模型?它有什么好处?以前没有人研究过吗?
可逆的好处
可逆意味着什么?
意味着它是信息无损的,意味着它或许可以用来做更好的分类网络,意味着可以直接用最大似然来做生成模型,而且得益于ResNet强大的能力,意味着它可能有着比之前的Glow模型更好的表现~总而言之,如果一个模型是可逆的,可逆的成本不高而且拟合能力强,那么它就有很广的用途(分类、密度估计和生成任务,等等)。
5
Dec
万能的seq2seq:基于seq2seq的阅读理解问答
By 苏剑林 | 2019-12-05 | 93369位读者 | 引用今天给bert4keras新增加了一个例子:阅读理解式问答(task_reading_comprehension_by_seq2seq.py),语料跟之前一样,都是用WebQA和SogouQA,最终的得分在0.77左右(单模型,没精调)。

用seq2seq做阅读理解的模型图示
方法简述
由于这次主要目的是给bert4keras增加demo,因此效率就不是主要关心的目标了。这次的目标主要是通用性和易用性,所以用了最万能的方案——seq2seq来实现做阅读理解。
用seq2seq做的话,基本不用怎么关心模型设计,只要把篇章和问题拼接起来,然后预测答案就行了。此外,seq2seq的方案还自然地包括了判断篇章有无答案的方法,以及自然地导出一种多篇章投票的思路。总而言之,不考虑效率的话,seq2seq做阅读理解是一种相当优雅的方案。
这次实现seq2seq还是用UNILM的方案,如果还不了解的读者,可以先阅读《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》了解相应内容。
3
May
从动力学角度看优化算法(四):GAN的第三个阶段
By 苏剑林 | 2019-05-03 | 101815位读者 | 引用在对GAN的学习和思考过程中,我发现我不仅学习到了一种有效的生成模型,而且它全面地促进了我对各种模型各方面的理解,比如模型的优化和理解视角、正则项的意义、损失函数与概率分布的联系、概率推断等等。GAN不单单是一个“造假的玩具”,而是具有深刻意义的概率模型和推断方法。
作为事后的总结,我觉得对GAN的理解可以粗糙地分为三个阶段:
1、样本阶段:在这个阶段中,我们了解了GAN的“鉴别者-造假者”诠释,懂得从这个原理出发来写出基本的GAN公式(如原始GAN、LSGAN),比如判别器和生成器的loss,并且完成简单GAN的训练;同时,我们知道GAN有能力让图片更“真”,利用这个特性可以把GAN嵌入到一些综合模型中。
2、分布阶段:在这个阶段中,我们会从概率分布及其散度的视角来分析GAN,典型的例子是WGAN和f-GAN,同时能基本理解GAN的训练困难问题,比如梯度消失和mode collapse等,甚至能基本地了解变分推断,懂得自己写出一些概率散度,继而构造一些新的GAN形式。
3、动力学阶段:在这个阶段中,我们开始结合优化器来分析GAN的收敛过程,试图了解GAN是否能真的达到理论的均衡点,进而理解GAN的loss和正则项等因素如何影响的收敛过程,由此可以针对性地提出一些训练策略,引导GAN模型到达理论均衡点,从而提高GAN的效果。

最近评论